



最后细数一次 JDK8 踩过的坑,往后再不干了
重复的事情不应该再做第二遍,否则是对生命的不尊重。
❝
🔊 本文主要内容:JDK8 踩过的坑,内容基础。
❞
「⏱️踩坑的原因:未知和遗忘。」
本文主要内容
第一类 API:只有特定参数值才会引发异常
| 相关 API | 具体描述 |
|---|---|
| Collectors.toMap | 1. 重复值 Duplicate key 错误..... |
| 2. value 的 function 计算结果 null 引发 NPE | |
| parallelStream 并行流 | 1. ThreadLocal#get() 为 null |
| 2. 非安全类数据异常 | |
| stream#sort 排序 | 排序字段为 null,引发 NPE,多字段排序常发生 |
| java.util.Optional#get/of | of 入参为 null,引发 NPE;get#value 为 null 异常 .... |
第二类 API:只要运行一次就能察觉错误
| 相关 API | 具体描述 |
|---|---|
| stream#peek | 非终止 API,遇到终止 API 才会执行 |
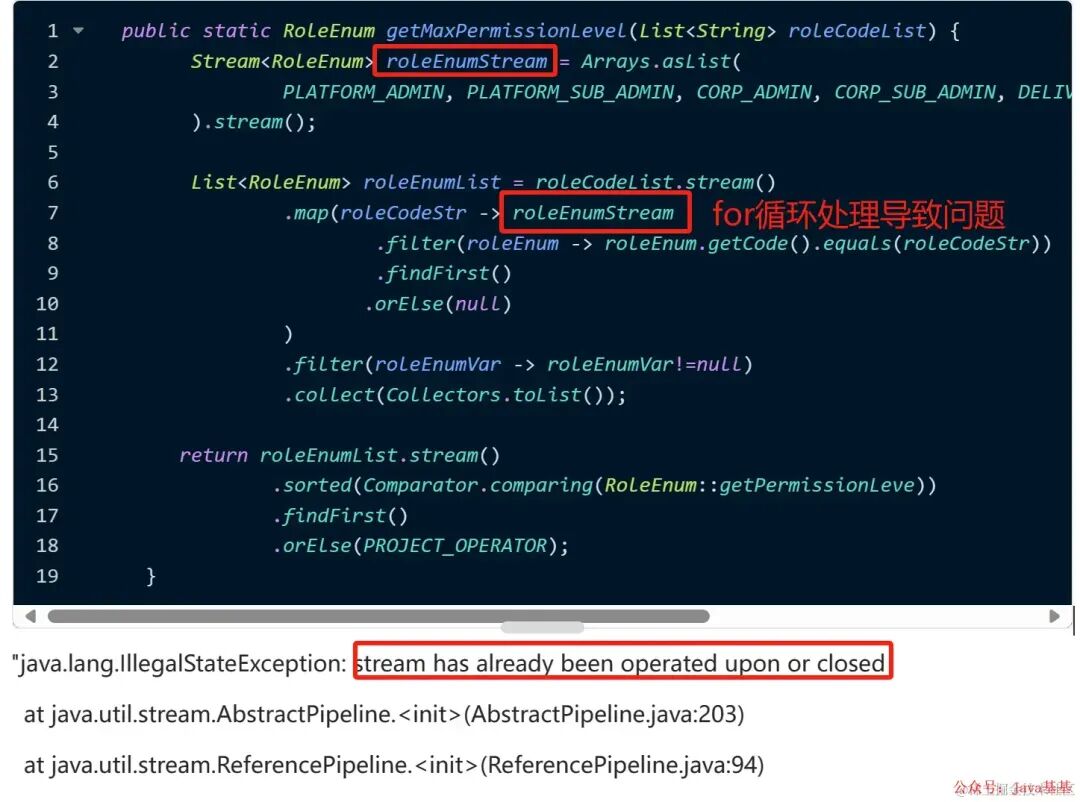
| stream 只能消费一次 | stream has already been operated upon or closed |
注:下文内容为上面表格的举例说明。
Collectors.toMap
关于 Collectors.toMap 的易错点主要有两个:
key 计算结果重复
| 场景还原 | 具体描述 |
|---|---|
| 从 DB 查询 List 数据, 将 List 转换成 Map,方便下一个循环的匹配查找 | 业务执行过程,出现了脏数据,key 不再唯一,引发错误 |
| key 是由 Function 方法计算而来 | Function 计算结果重复,引发错误 |
下面案例:模拟数据重复值,toMap 时出现 duplicate key
Map<String, String> map = Arrays.asList("A", "A")
.stream()
.collect(Collectors.toMap(str -> str, Function.identity()));
防止脏数据等异常数据,一定指定 mergeFunction;请使用下面 API 进行 toMap
toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper,
BinaryOperator<U> mergeFunction) 值为 null
| 场景还原 | 具体描述 |
|---|---|
| 从 DB 中获取的对象数据,进行 toMap | value 的字段被某业务场景更新为 null 了(或丢失更新)。 |
| value 是由 Function 方法计算而来 | Function 计算为 null |
下面案例:value 值由函数值返回,模拟返回 null, 运行结果 NPE
privatestatic String returnNull(){
returnnull;
}
publicstaticvoidmain(String[] args){
Map<String, String> map = Arrays.asList("A", "A")
.stream()
.collect(Collectors.toMap(str -> str, str -> returnNull(), (first, second) -> first));
}
parallelStream
❝
遇到最大的坑:直接将 stream 修改成 parallelStream , 天真地以为做了性能优化。
❞
常见 stream 流操作中有 DB 查询、远程 API 等耗时操作,直接将 stream 修改成 parallelStream 做优化
并行流
-
ThreadLocal#get 异常
-
非线程安全类异常
parallelStream 是多线程并行流,容易出现多线程问题
| 场景还原 | 具体描述 |
|---|---|
| ThreadLocal#get 数据有时候正确 | ThreadLocal 与当前线程有关系 |
| ArrayList 返回条目数不对 | ArrayList 不是线程安全类 |
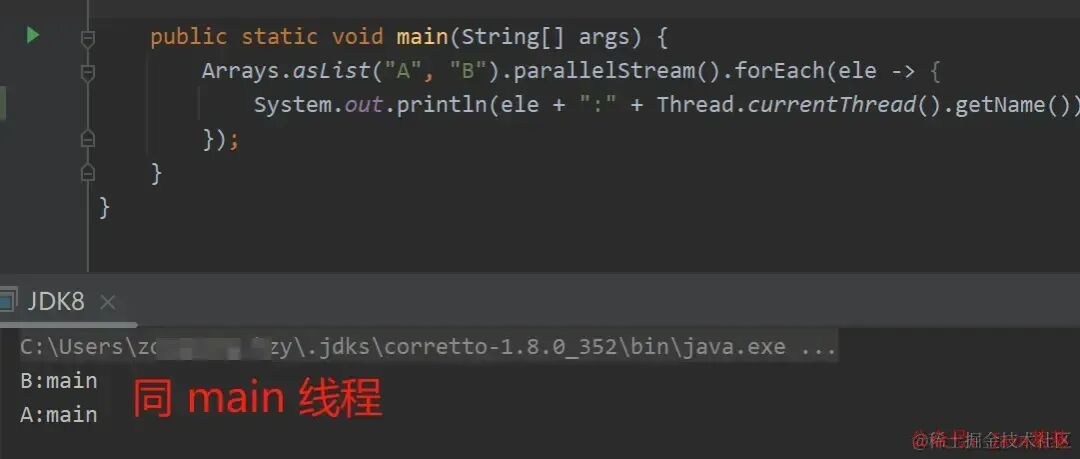
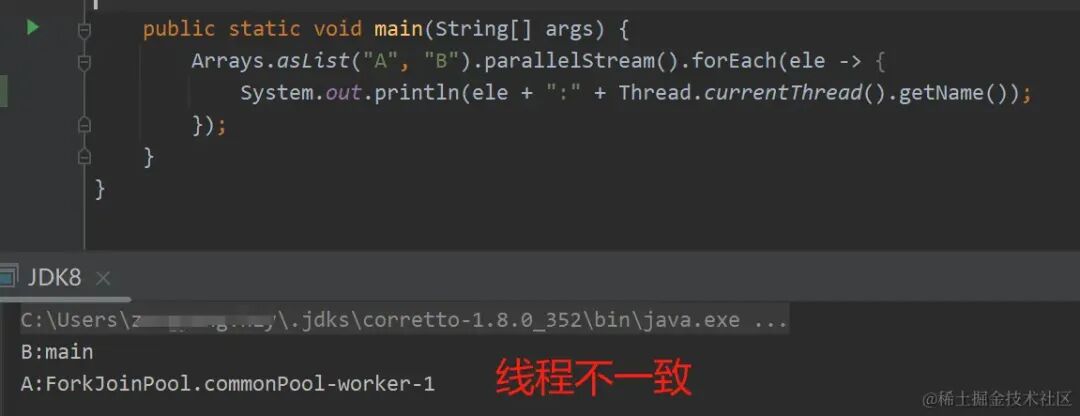
下面案例:相同代码执行两次,结果线程名称不一致。
| 执行第一次 | 执行第二次 |
|---|---|
|
|
|
| ThreadLocal 异常的情况,模拟用户应用上下文,最终获取为 null |
|---|
|
|
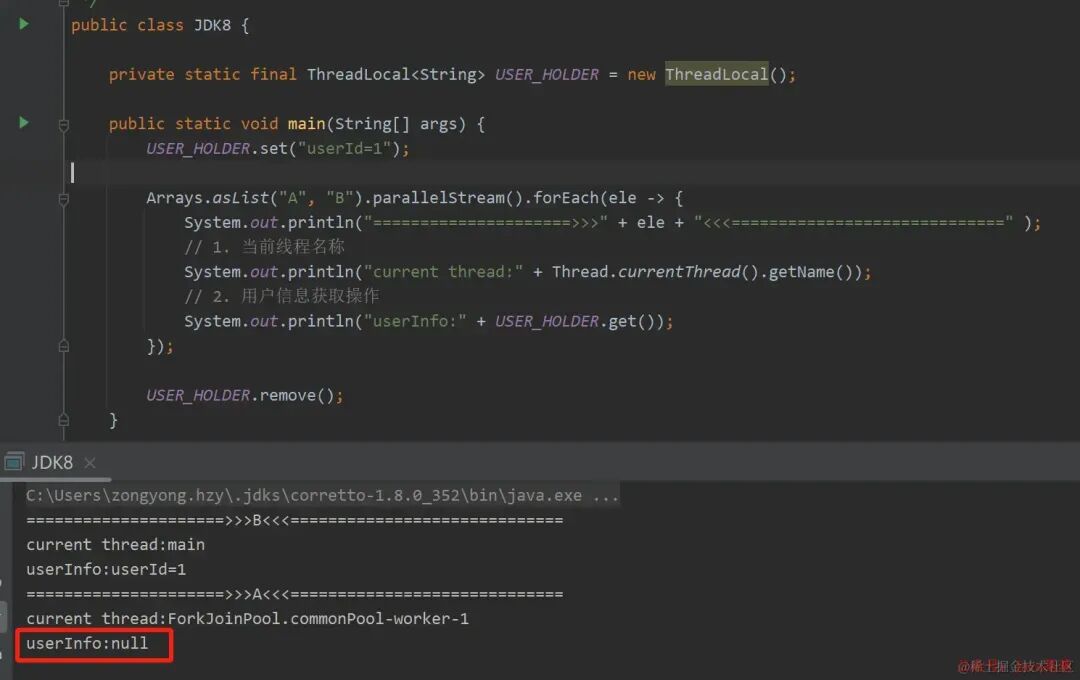
其他场景不再赘述,一定要知道 parallelStream 是并行的,多线程的问题它都有。特别注意:「数据量小不易察觉」 ;性能优化不能仅仅将 stream 修改成 parallelStream !!!血泪经验......

stream#sort
排序字段 null
多字段排序在 tob 业务常见;常因为第二、三个字段为 null 排序出现 NPE
| 场景还原 | 具体描述 |
|---|---|
| 业务查询结果,先按第一个字段排序,相同再按照第二个字段排序...... | stream 不同于数据库的排序操作,为 null 时数据库会默认排序,但这个API不会 |
| 案例:模拟从 DB 检索出来的数据,按照业务要求进行多字段排序 |
|---|
|
|
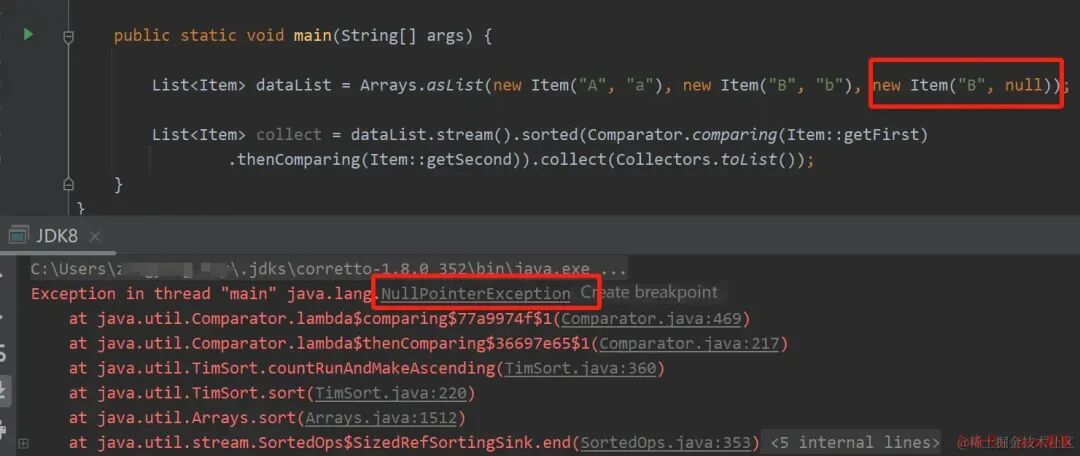
往事:同事第一次用这个 API 就出现了线上故障 ≡(▔﹏▔)≡
如果排序字段有可能为空,有需要排序,可在比较器中加入Comparator.nullsLast(String::compareTo)orComparator.nullsFirst(String::compareTo)为空的会放在前面或后面
Optional#get/of
get/of
Optional 被引入用来解决 NPE,但下面这两个 API 却容易出现异常 😅
-
of 入参为 null 抛 NPE
-
get 返回值,检查 value 为 null 抛 NoSuchElementException
下面是 java.util.Optional#get 方法源码
public T get(){
if (value == null) {
thrownew NoSuchElementException("No value present");
}
return value;
}题外话:Optional 是我个人非常喜欢的一个类,大大减少了 NPE;比如我还用它作出参入参。形如下面:
public <T,R> Optional<T> function(Optional<R> param){
.....
}其他
再啰嗦一下边边角角的 API
stream只能消费一次
运行一次就知道用错误了(好多流的 API 也是只能消费一次)
下面案例:stream 用了多次,出现错误
peek 方法
peek 用的很少,个人不推荐用,初衷为了 debug 。peek 遇到终止类的 API 才执行。
下面案例:convenientMap 并不会插入新的元素。只有添加了一些终止操作才会执行。例如:collect(Collectors.toList()), forEach等。
// toMap 功能
List<Task> taskList = instTaskBO.getInstanceId(instance.getInstanceId());
Map<String, Task> convenientMap = new HashMap<>();
// 将 list 转成map
taskList.stream().peek(task -> convenientMap.put(String.valueOf(task.getId()), task));其他
-
8的日期:不熟,用的少,坑不知道😅
-
CompletableFuture:考虑异常情况;join 设置时长
下面案例:对于异常给一个默认的返回值
// 异常情况给一个默认值
private CompletableFuture<Integer> calculate(Supplier<Integer> supplier){
return CompletableFuture
.supplyAsync(() -> invokeTask(supplier))
.exceptionally(throwable -> {
log.error(".....", throwable);
return0;
});
}总结
本文总结个人在使用 JDK8 踩过的坑,内容基础。但总结是比较花费精力,后面尽量总结研究一些高级点的东西~~~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









