



引言
最近带团队做新项目,发现刚毕业的学弟还在用最原始的方式搭建Maven多模块项目——手动建文件夹、写pom依赖、调整目录结构...整整折腾了一下午,连基础框架都没搭好。
不光是新人,我们这些工作好几年的老鸟每次开新项目也得重复这些机械操作。就拿我们团队来说,之前搭个基础框架平均要40分钟,还经常配错依赖。所以我花了两周业余时间撸了这个插件,现在团队建项目都是"一键生成",30秒搞定,简直不要太香!
说多了都是泪(开发背景)
为啥要折腾这破插件?还不是被那些破事逼的😂 给你们瞅个真实血泪史:
上周带的实习生搭项目,就四个模块(api、service、pojo、common),活生生卡了一下午。不是把依赖写反了(service依赖api这种骚操作都整出来了),就是目录建得跟打仗似的,最后还是我亲自操刀重构的。当时我就拍桌子了:这种重复到吐的活儿,就不能自动化搞定?
其实不仅是新手,就连有经验的开发者每次新建项目时,也难免要重复这些机械操作。于是我开发了这个插件,把这些重复性工作自动化,让项目搭建时间从小时级缩短到分钟级。
插件核心功能
别看插件不大,解决的可都是咱们天天踩的坑:
-
• 真正的一键生成: 输入模块名就能自动创建全套结构,连pom依赖都帮你配好
-
• 智能依赖关联: 按业务顺序输入模块名(如
api→service→pojo),自动建立依赖关系 -
• 完全自定义: 模块名、Java版本随便改,生成的结构完全符合公司规范
-
• 自带最佳实践: 默认生成的目录结构和配置都是Maven官方推荐的标准
-
• 零配置启动: 自动生成
.gitignore和README,拉下来就能直接开发
开装!(两种姿势)
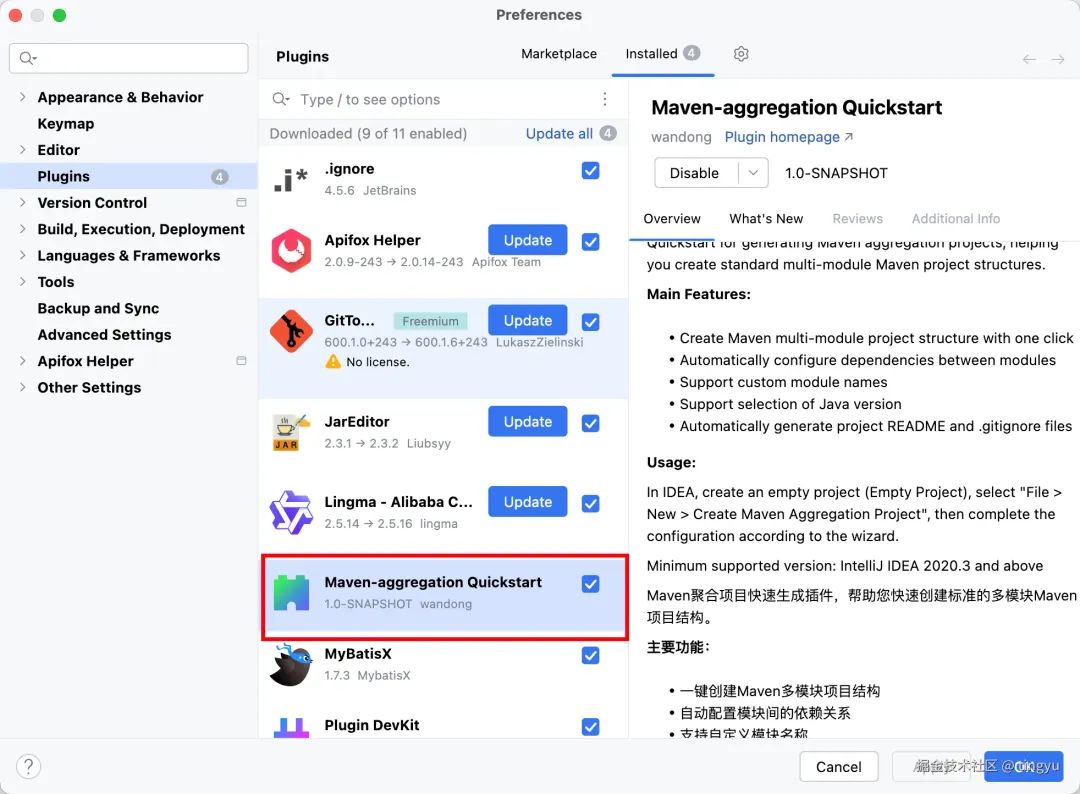
懒人法:插件市场一键装(推荐新手)
这个目前还在审核中,所以你需要先手动下载jar包,再安装。等审核通过后,就可以直接在插件市场搜索安装了。
-
• 打开IDEA,按
Ctrl+Alt+S打开设置(Mac用户用Cmd+,) -
• 点左侧
Plugins,顶部切换到Marketplace -
• 搜索框敲
Maven-aggregation Quickstart(输前几个字就能搜到) -
• 点Install,等进度条走完重启IDEA就好
如图所示:
图片
方法二:手动安装(离线环境)
从插件仓库下载最新的jar包
同样打开插件设置页面,点右上角小齿轮 ⚙️
选Install Plugin from Disk...,找到下载的jar包就行
注意:IDEA版本得2020.3以上,太老的版本可能不兼容(别问怎么知道的,踩过坑😭)
注意:插件需要IntelliJ IDEA 2020.3及以上版本,如果你使用的是较旧版本,建议先升级IDEA
废话不多说,开干!(实战环节)
光吹牛逼没用,上手操作才是王道。拿个电商项目举例子,看看这插件到底多好用:
1. 打开创建向导
重启IDEA后,首先创建项目 ,创建一个空的工程,选择Empty Project,点File > New就能看到Create Maven Aggregation Project选项(在New Project下面一点)
如图所示:

图片
也可以通过模块名右击 :New - Create Maven Aggregation Project。如图所示:

图片
2. 填写项目信息
就一个配置页面,填这几项就行:
-
• GroupId: 公司/组织域名倒写,比如我们公司用
com.wandong -
• ArtifactId: 项目名,小写无空格,比如
user-center -
• Version: 默认1.0.0就行,后期再改
-
• 模块名称: 这个最重要!按业务顺序填,用逗号隔开,比如
api,``service,pojo,common -
• Java版本: 建议选11或17,太新的版本可能有兼容性问题
如图所示:

图片
💡 小技巧:模块顺序很重要!插件会按你输入的顺序自动建立依赖关系,比如api依赖service,service依赖pojo
小技巧:模块名称最好遵循业务领域划分,如api(接口层)、service(服务层)、pojo(实体类)、common(公共组件)
3. 坐等收菜
最后一步点Finish,然后就可以摸鱼等结果了——插件会自动帮你把所有模块和配置文件都建好。我那用了三年的老笔记本也就20秒搞定,新电脑估计10秒内就能完事。创建完的项目长这样:
ecommerce-platform/
├── api/
├── service/
├── pojo/
├── common/
├── pom.xml // 父pom文件
├── README.md
└── .gitignore
如图所示:

图片

图片
最香的是每个模块都是标准Maven结构,src/main/java、src/test/resources这些文件夹全都给你建好,再也不用手动建目录了(我以前每次都要漏建一两个):
module-name/
├── src/
│ ├── main/
│ │ ├── java/ // 源代码目录
│ │ └── resources/ // 资源文件目录
│ └── test/
│ ├── java/ // 测试代码目录
│ └── resources/ // 测试资源目录
└── pom.xml // 模块pom文件
老司机才知道的骚操作
给团队定制专属模板(这招能装X)
我们团队有自己的代码规范,所以我研究了下怎么改模板,发现超简单:
-
\1. 先找到插件安装位置,一般在
~/.local/share/JetBrains/IntelliJIdea/plugins/(Windows用户在C:\Users\用户名\AppData\Roaming\JetBrains\插件名) -
\2. 里面有个
templates文件夹,直接改里面的Velocity模板文件就行 -
\3. 改完重启IDEA,新生成的项目就完全符合团队规范了
依赖关系不用手动配
这个功能我特别喜欢!你输入模块时按业务顺序排好(比如api,service,pojo),插件会自动帮你:
-
• api里加service依赖
-
• service里加pojo依赖
-
• 所有模块默认依赖common
完全不用自己写dependency标签,省了我每次都要复制粘贴的功夫
遇到问题这样解决
有同学问过我几个常见问题,这里统一说下:
内存溢出怎么办? 刚用的时候我也遇到过,打开Help > Edit Custom VM Options,把-Xmx后面的数字改大,比如-Xmx2048m(2G内存)就够用了
插件找不到? 确保IDEA版本在2021.1以上,太老的版本不支持。实在不行就卸载重装,记得重启IDEA
想改Java版本? 直接改父pom.xml里的maven.compiler.source和maven.compiler.target,两个值设成一样的就行,比如17
想改源码?看这里(进阶玩家)
要是你想给插件动刀子——比如加上公司特有的代码生成规则,或者想趁机学一波IDEA插件开发,这项目源码绝对适合你。我当时也是摸着石头过河,把踩过的坑给你们标出来:
1.先把代码搞下来
git clone git@gitee.com:tingyuabc/maven-aggregation-quickstart.git
cd maven-aggregation
2.构建其实很简单
不用复杂配置,直接Maven打包就行:
mvn clean package
等着控制台输出BUILD SUCCESS,然后去target/目录找生成的jar包。我第一次打包的时候因为依赖冲突卡了半天,后来发现是IDEA版本对应问题,建议用2022.1以上版本构建
3. 本地安装测试
在IDEA中选择Install Plugin from Disk...,选择刚生成的jar包进行安装测试。

















 2758
2758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









