




 本文介绍如何在Hadoop中自定义输出格式,通过编写自定义RecordWriter和OutputFormat类,实现将不同类型的请求(GET、POST和其他)分别输出到get.txt、post.txt和其他.txt文件中,展示了如何在MapReduce作业中进行更精细的文件名定制。
本文介绍如何在Hadoop中自定义输出格式,通过编写自定义RecordWriter和OutputFormat类,实现将不同类型的请求(GET、POST和其他)分别输出到get.txt、post.txt和其他.txt文件中,展示了如何在MapReduce作业中进行更精细的文件名定制。
应用之前学过的一个案例结合自定义OutPutFormat,进行输出文件名字自定义。(不使用默认的part-r-00000)
对日志文件中的GET 和 POST 和其他类型 请求分离输出分别输入到get.txt ,post.txt,other.txt
自定义RecordWriter类
package com.bigdata.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
/**
-
自定义RecordWriter
*/
public class MyRecordWriter extends RecordWriter<Text, NullWritable> {
//定义输出流,对应不同的文件
FSDataOutputStream getRequestOut=null;
FSDataOutputStream postRequestOut=null;
FSDataOutputStream otherRequestOut=null;public MyRecordWriter(TaskAttemptContext context){
//获取文件系统
FileSystem fs=null;
//获取job传进来的路径
Path outputPath= FileOutputFormat.getOutputPath(context);
try{
fs=FileSystem.get(context.getConfiguration());
//创建两个输出流
getRequestOut=fs.create(new Path(outputPath,“get.txt”));
postRequestOut=fs.create(new Path(outputPath,“post.txt”));
otherRequestOut=fs.create(new Path(outputPath,“other.txt”));
}catch (Exception e){
e.printStackTrace();
}
}@Override
public void write(Text text, NullWritable nullWritable) throws IOException, InterruptedException {
//判断是否包含itstar字段,写到itstar.log,数据分开
if(text.toString().contains(“GET”)){
getRequestOut.write(text.toString().getBytes());
}else if(text.toString().contains(“POST”)){
postRequestOut.write(text.toString().getBytes());
}else{
otherRequestOut.write(text.toString().getBytes());
}}
@Override
public void close (TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//关闭资源
if(getRequestOut != null){
getRequestOut.close();
}
if(postRequestOut != null){
postRequestOut.close();
}
if(otherRequestOut != null){
otherRequestOut.close();
}}
}
自定义outputFormat类
package com.bigdata.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
-
自定义outputFormat,继承FileOutputFormat
*/
public class MyOutputFormat extends FileOutputFormat<Text, NullWritable> {@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
return new MyRecordWriter(taskAttemptContext);
}
}
maper类
package com.bigdata.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OutputMaper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
context.write(value,NullWritable.get());
}
}
reduce类
package com.bigdata.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OutputReduce extends Reducer<Text, NullWritable,Text,NullWritable> {
Text k=new Text();
@Override
protected void reduce(Text key,Iterable values,Context context) throws IOException, InterruptedException {
String s=key.toString();
k.set(s+"\r\n");
context.write(k,NullWritable.get());
}
}
元数据截图
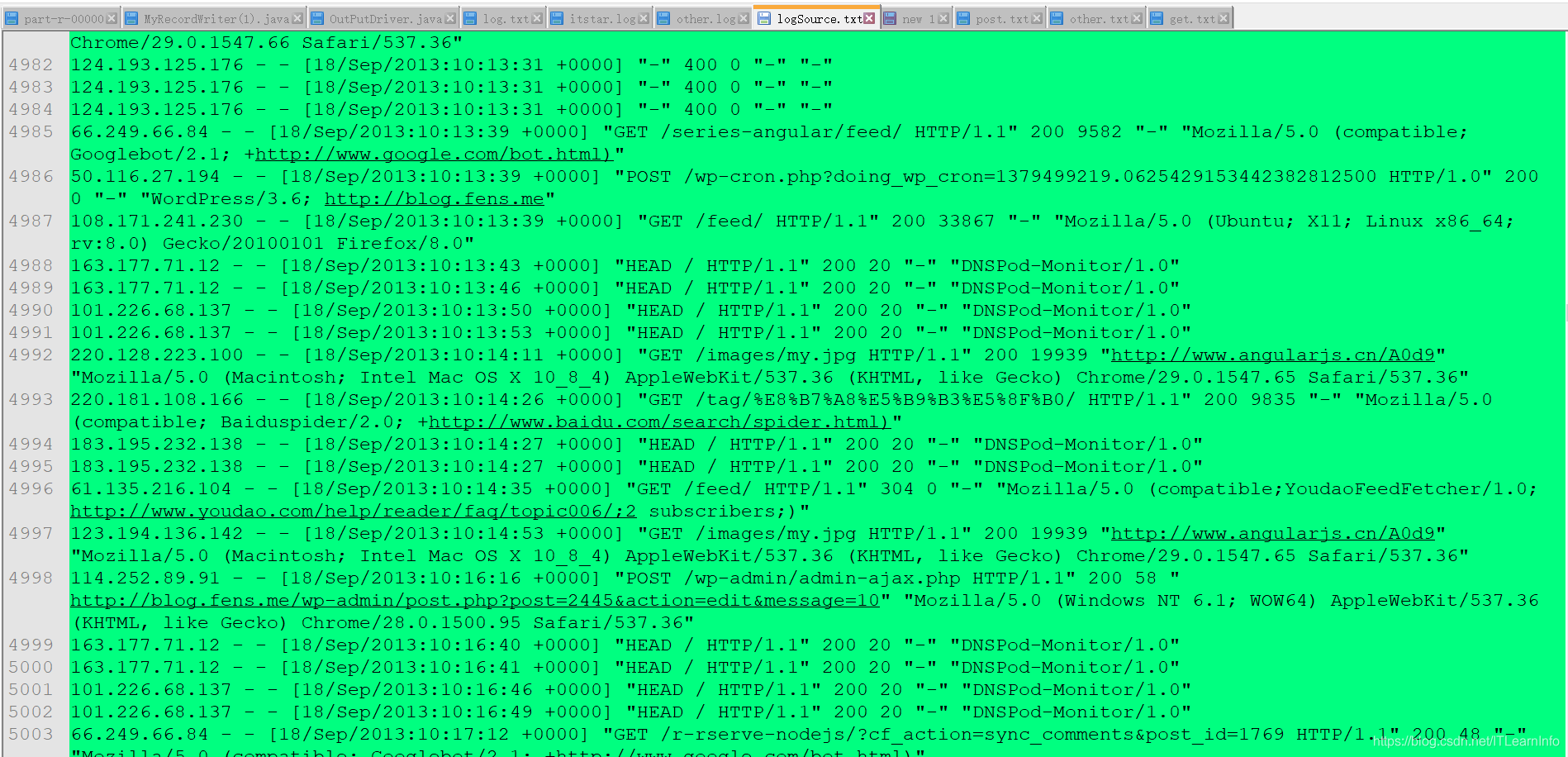
运行结果截图
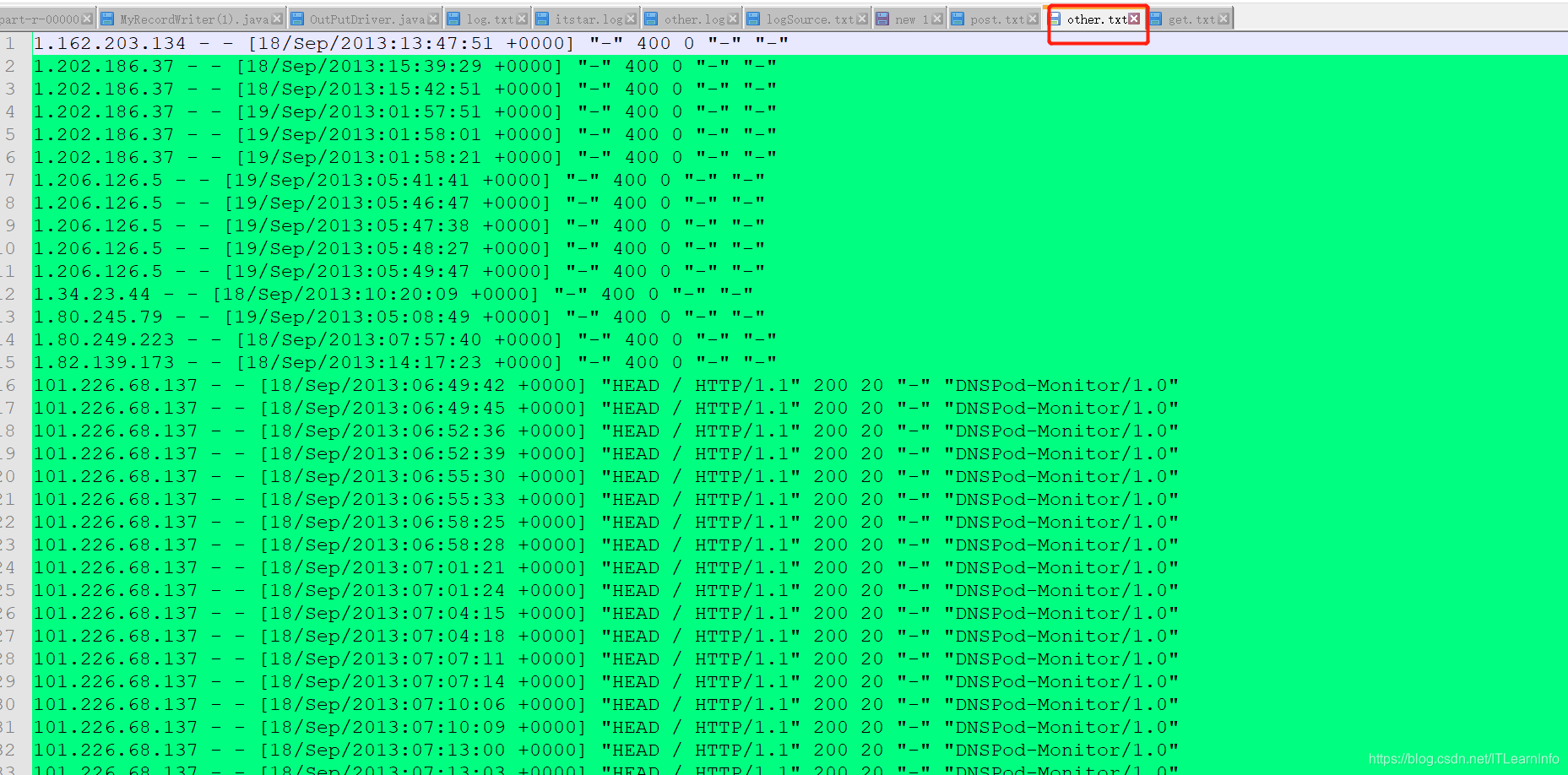
包含其他类型的日志 other.txt
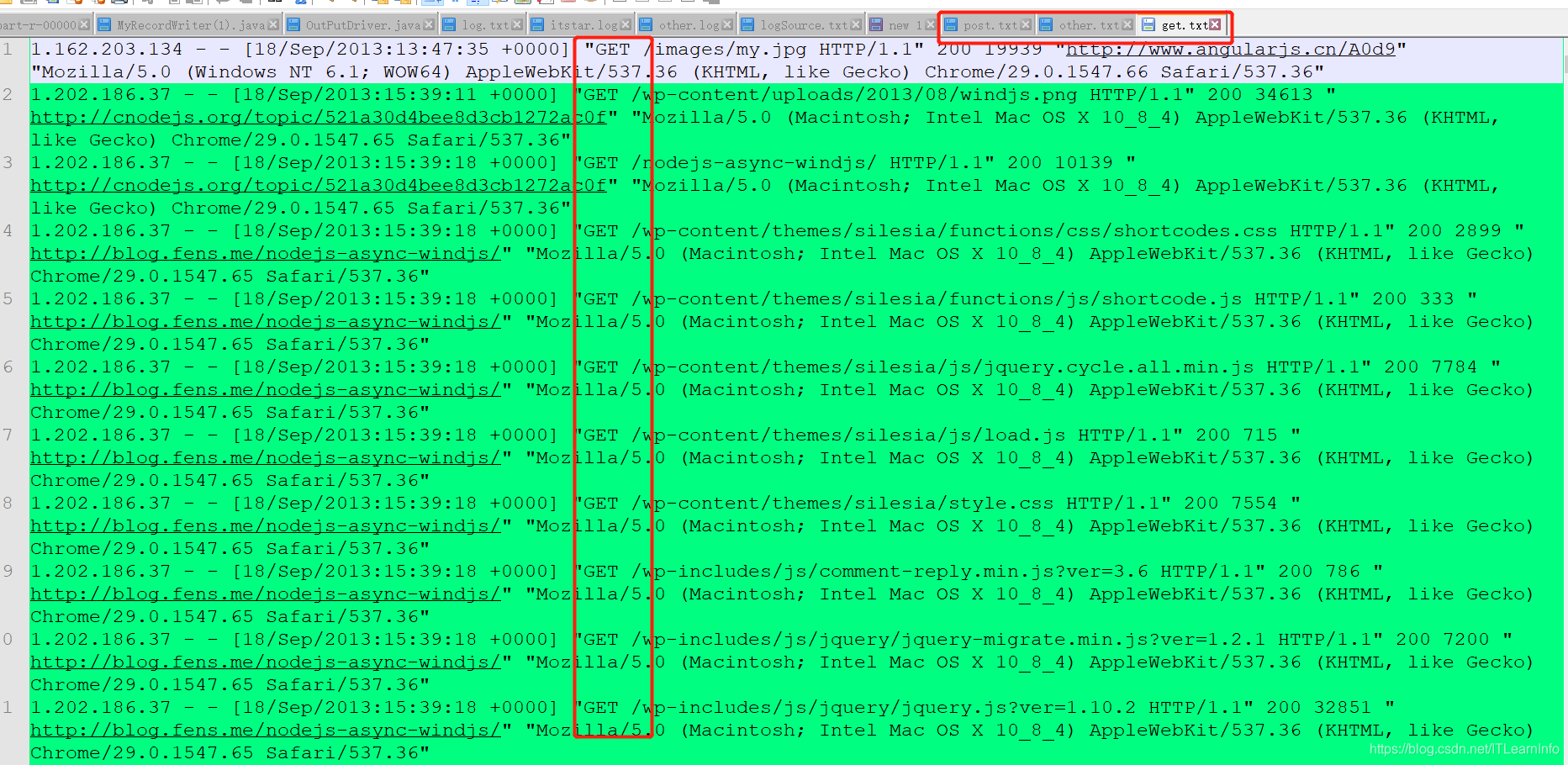
包含get请求的日志运行截图 get.txt
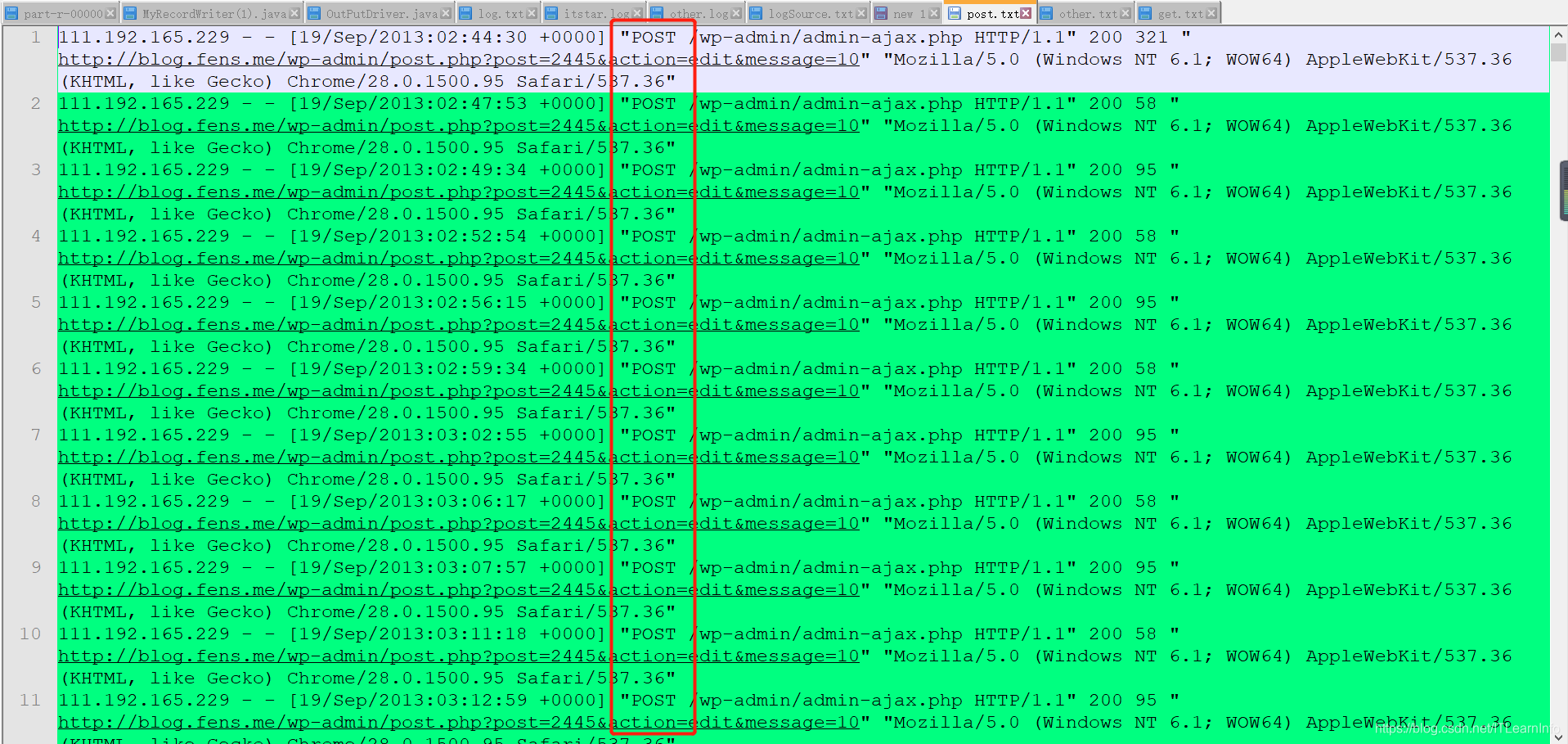
只包含post请求的日志运行截图

















 3062
3062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









