







文本文件:后缀名为.txt, .xml,.json,.csv等这样的文件。
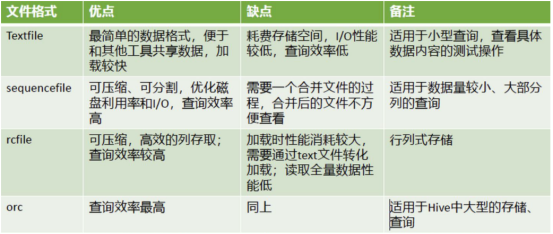
sequence , rc ,orc 三种格式,不能直接使用load data的方式导入数据,
先将数据导入到textfile的表格中,然后通过insert overwrite table的方式再复制过去。
textfile格式
textfile是hive默认的表格保存格式, 行存储的方式进行数据存储。占用空间,并且读取速度比较慢,可以通过load data来加载数据
1.表创建
create table emp_text(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
)
row format delimited fields terminated by ','
stored as textfile;
2.准备海量数据的文件
emp.txt
1,tony,clerk,0,2021-09-01,9873.12,998.33,101
2,ton1,cler1,1,2021-09-02,9873.13,998.13,101
3,ton2,cler2,1,2021-09-11,9873.14,998.23,101
4,ton3,cler3,1,2021-09-21,9873.15,998.39,101
5,ton4,cler4,1,2021-09-15,9873.16,998.36,101
6,ton5,cler5,1,2021-09-23,9873.17,998.37,101
3.linux中对文件进行压缩:gzip
gzip emp.txt
4.linux中查看文件大小
du -s -h emp.txt.gz

5.再通过load data的方式导入到textfile表格中
load data local inpath '/root/emp.txt.gz' into table emp_text;

6.查看数据量是否正确
select * from emp_text;

7.查看前10行数据
select * from emp_text limit 10;

sequence格式
sequence是序列格式,占用的空间比text实际要大,也是行存储的方式,使用key value键值对的方式存储数据。
1.表创建
create table emp_seq(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
)
row format delimited fields terminated by ','
stored as sequencefile;
2.支持三种压缩选择:NONE(无压缩),RECORD,BLOCK。
Record压缩率低,一般建议使用BLOCK压缩。设置以下操作:
set hive.exec.compress.output=true; --启用压缩格式
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
--指定输出的压缩格式为Gzip
set mapred.output.compression.type=BLOCK; --压缩选项设置为BLOCK
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;

3.插入数据
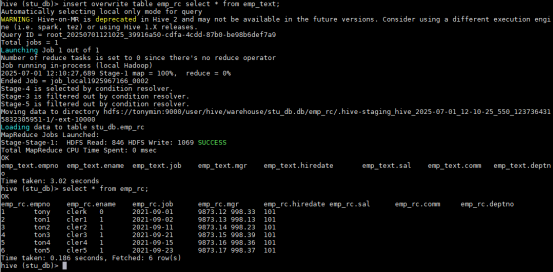
insert overwrite table emp_seq select * from emp_text;
select * from emp_seq;

rc格式
facebook创建的一种文件存储格式,列存储的方式。使用懒加载存储和管理数据(对每一行的数据单独的进行数据压缩,如果要读取,只读对应的数据,只解压对应的数据),查询速度比较快。
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点。
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取。
行存储:
1 tony 18
2 jack 16
3 tom 19
列存储:
1 2 3
Tony jack tom
18 16 19
1.建表
create table emp_rc(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
)
row format delimited fields terminated by ','
stored as rcfile;
2.设置以下操作
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compress=true;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
3.插入数据
insert overwrite table emp_rc select * from emp_text;
orc格式
orc是工作中使用最多的最常见的格式,也是列存储的方式,是rc的优化版,同样有懒加载的特点,优化在文件的压缩和存储上,orc是项目组中使用最多的文件存储格式。默认会自动的对表格的数据进行压缩,内部压缩的格式使用的是zlib,在读取中大型表格的时候,速度是最快的。
1.建表
create table emp_orc(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal float,
comm float,
deptno int
)
row format delimited fields terminated by ','
stored as orc;
2.插入数据
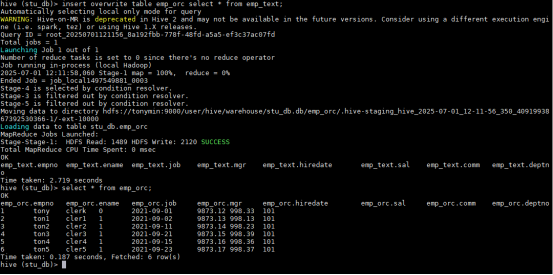
insert overwrite table emp_orc select * from emp_text;
select * from emp_orc;
平时表格会用到的存储格式,
只有两种:
text:如果表格的文件需要经常被导入和导出;表格的数据不是很大。使用gzip进行压缩。
orc:当表格非常大的时候 ,使用其他的格式读取数据的时间比较长。使用zlib进行压缩。
数据压缩,常见Textfile(维度表、数据量级不大的表格,使用Gzip压缩)和 orc(中大型表,使用zlib压缩) 这两种。

















 2606
2606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









