




(图文并茂)深度学习实战(3):mnist手写体识别案例
经过上一篇的(图文并茂)深度学习实战(2):ubuantu下安装和配置caffe框架(gpu版),我已经在linux系统下安装好了caffe框架,接下来就以mnist手写体识别为例,先熟悉一下caffe框架的相关流程。
1.mnist数据集介绍
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.
如图:
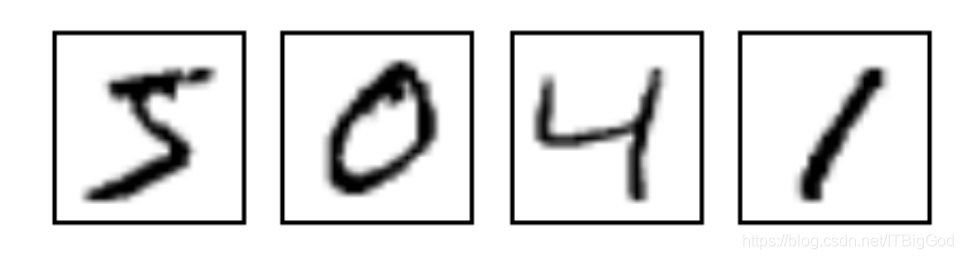
手写体识别解决的是把28x28像素的灰度手写数字图片识别为相应的数字,其中数字的范围从0到9。
它包含了四个部分:
| 文件 | 内容 |
|---|---|
| train-images-idx3-ubyte.gz | 训练集图片 - 55000张训练图片, 5000张验证图片 |
| train-labels-idx1-ubyte.gz | 训练集图片对应的数字标签 |
| t10k-images-idx3-ubyte |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











