




 本文详细介绍了Shell脚本的基础知识,包括条件判断、文件类型判断、字符串判断、流程控制、循环结构、变量声明及数值运算等内容,是初学者快速掌握Shell编程的实用指南。
本文详细介绍了Shell脚本的基础知识,包括条件判断、文件类型判断、字符串判断、流程控制、循环结构、变量声明及数值运算等内容,是初学者快速掌握Shell编程的实用指南。
1.条件判断
文件类型判断
-d 是存在目录
-e 是否存在文件
-f 是否为普通文件

![[ -d ./test1 ] && echo "yes" || echo "NO"](https://i-blog.csdnimg.cn/blog_migrate/6e304bd1550c46ec155550acefcf896a.png)
2.文件权限判断 -r 文件 -w 文件 -x 文件
3.文件之间的比较
文件1 -nt 文件2 判断文件1是否比文件2新
文件1 -ot 文件2 判断文件1是否比文件2旧
文件1 -ef 文件2 判断两个文件是否为同一个文件,用于判断硬链接
4.整数之间的比较
-eq 等于
-ne 不等于
-gt 大于
-lt 小于
-ge 大于等于
-le 小于等于
5.字符串判断
-z 字符串 判断字符是否为空
-n 字符串 判断字符是否非空
字符1 == 字符2 判断字符1,2 是否相等
6.与 或 非 多条件
条件1 -a 条件2 逻辑与 两个同时为真,结果才为真
条件1 -o 条件2
! 非,原判断式取反
流程控制
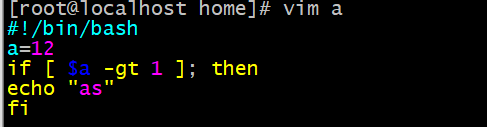
if [ 条件 ];then
程序
fi
或
if [ 条件 ]
then
程序
fi
单行输入 if [ -f /usr/bin/ssh ]; then echo "true"; fi
注意:条件判断与[] 间必须有空格,then放在[]之后用;隔开.或者换行写入
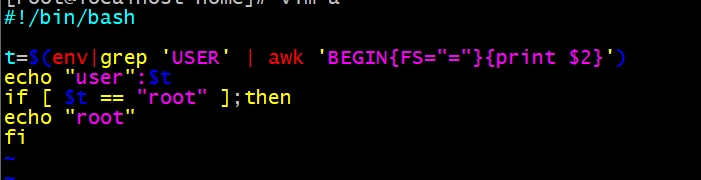
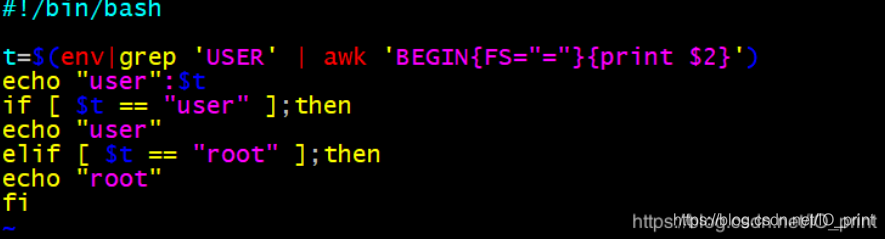
if…elif …fi
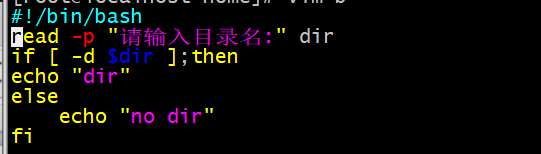
if … else…fi
case语句
case $变量名 in
“值1”)
执行程序;;
“值2”)
执行程序;;
*)
以上都不是执行程序
;;
esac
#!/bin/bash
read -p "请输入数字1,2,3" num
case $num in
1)
echo "1";;
"2")
echo "2";;
"3")
echo "3";;
*)
echo "输入错误";;
esac
for循环
for 变量 in 值1 值2
do
程序
done
#!/bin/bash
for i in 1 2 3
do
echo $i
done
单行输入 for i in ${值}; do echo $i; done
for((初始值;循环条件;变量变化)))
do
程序
done
#!/bin/bash
for((i=1;i<5;ii+1))
do
echo $i
done
while
while [ 条件判断]
do
程序
done
#!/bin/bash
i=1
s=0
while [ $i -lt 100 ]
do
s=$(($s+$i))
i=$(($i+1))
done
echo "sum:"$s
通配符 \: 匹配多哥任意内容 ? 匹配任意一个内容 [] 匹配括号中的一个字符
正则表达式:用来在文件中匹配符合条件的字符串,正则是包含匹配. grep、awk、sed等命令支持正则表达式。
通配符:匹配符合条件的文件名,通配符是完全匹配。 find 、ls等使用通配符匹配。
基础正则表达式:
* 匹配前一个字符匹配0次或任意多次
a* 匹配所有内容,包括空行 注意\*匹配前一个字符0次或任意多次
aa* 匹配含a的行.
. 匹配处换行符外任意的一个字符
^ 匹配行首
$ 匹配 行位
^$ 匹配空白行
[] 匹配括号中指定的字符,只匹配一个字符
[^] 匹配任意一个括号外的字符
\ 转义符
{n} 匹配前一个字符n次
{n,} 匹配前一个字符不小于n次
字符串截取
1.cut (截取格式规律的文档)
-f 截取列 -d [字符] 以字符切割
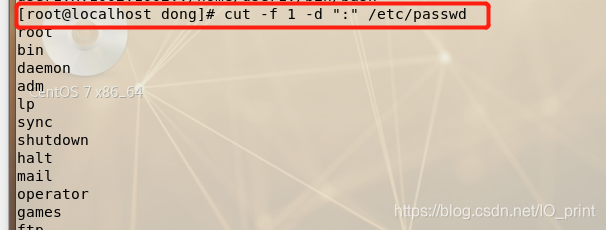
cut -f 1,3 -d “:” /etc/passwd 截取第一列和第三列
2.printf
printf ‘输出类型输出格式’ 输出内容
输出类型:
%ns : 输出字符串,n表示输出几个字符串
%ni: 输出整数
%m.nf:输出浮点数 m为整数位,n为小数位
输出格式:
\a:输出警告声音
\b:输出退格键
\f:清楚屏幕
\n:换行
\r:回车
\t:水平输出退格键,Tab键.
\v:垂直输出退格键,Tab键.

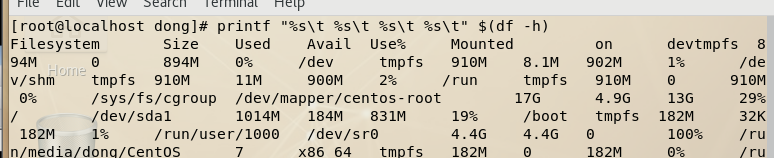
printf ‘%s’ $(cat 文件)
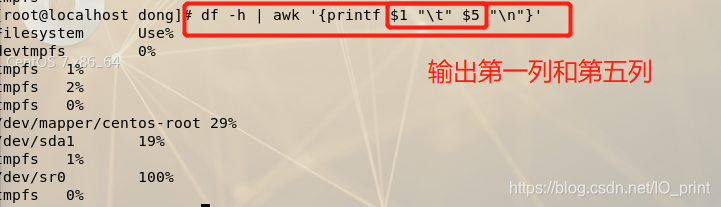
3.awk
awk ‘条件1{动作1}条件2{动作2}’ 文件名
条件(pattern): 一般为关系表达式作为条件
动作(action): 格式化输出,流程控制语句
BEGIN 开始 awk ‘BEGIN {printf “this is begin”}’
END 结尾 awk ‘END {printf “this is end”}’
FS内置变量 设置指定分隔符
awk ‘BEGIN {FS=":"}{print $1}’
awk -F: ‘($3==0) {print $1}’ /etc/passwd #以:分割,且 第三列值等于0,输出改行的第一个字段
关系运算符
grep -v name |awk ‘$1>2 {printf $1}’
4.sed 用于数据选取 替换 删除 新增
sed [选项] ’ [动作]’ 文件名
选项:
-n 会把sed命令处理的行输入到屏幕
-e 允许对输入数据应用多条sed命令标记
-i 直接修改读取数据文件,默认不修改原文件.
动作:
a: 追加,在当前行后添加一行或多行
c :行替换,用c后面的字符串替换原数据行
i :插入,在当前行前插入一行或多行.
d :删除指定行
p :打印,输出指定行
s:字符替换,格式为 “行范围s/就字符串/新字符串/g”
sed -n ‘2p’ 文件名 打印文件的第二行
sed ‘2,4d’ 文件名 删除2-4行内容
sed -e ‘s/原字符/替换后/g; s/原字符/替换后/g’ 文件名
字符处理
排序命令 sort
sort [选项] 文件名
选项:
-f :忽视大小写
-n :以数值型进行排序,默认使用字符串型排序.
-r: 反向排序.
-t : 指定分隔符,默认分隔符号是制表符(tab键).
-k n[,m] :按照指定的字段范围排序.从第n个字段开始,m字段结束(默认到行尾)
sort -n -t “:” -k 3,3 /etc/passwd 使用uid排序
统计命令 wc
wc 选项 文件名
选项:
-l 只统计行数
-w:只统计单词数
-m:值统计字符数
环境变量
source 配置文件 修改配置文件后,必须注销重新登录才能生效.使用source命令不用重新登录
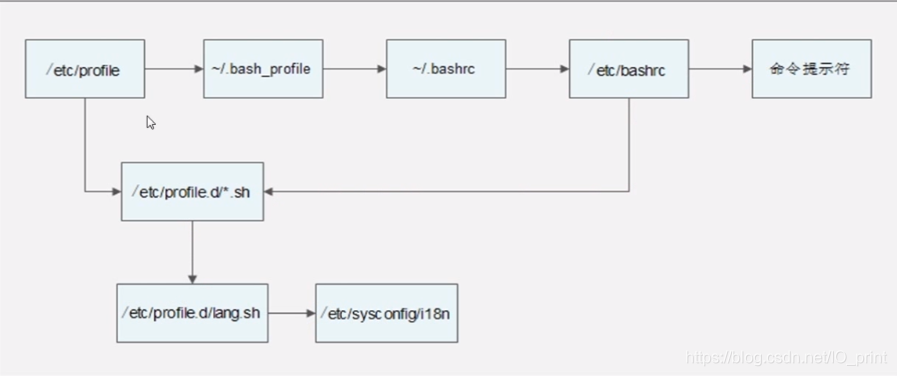
环境变量加载顺序
系统启动 /etc/profile -> /etc/profile.d/.sh->/etc/profile.d/lang.sh->/etc/sysconfig/i18n
/etc/profile->~/.bash_profile->~/bashrc -> /etc/bashrc
用户切换 /etc/bashrc-> /etc/profile -> /etc/profile.d/.sh->/etc/profile.d/lang.sh->/etc/sysconfig/i18n
source ./bashrc
其他环境变量
1.注销时生效的环境变量配置 ~/.bash_logout
2.历史命令 ~/.bash_history
3.shell登录信息 /etc/issue
变量声明
1.declare [+/-] [选项] 变量
-: 设置变量设置类型属性
+: 取消变量类型属型
-a 声明变量为数组型
-i 整数类型
-x 环境变量 // 和export相似
-p 查看变量类型
数组
m[0]=12
m[1]=11
declare -a m
echo ${m}
echo ${m[*]} //列出所有数组内容
expr或let数值运算工具
a=1
b=2
c=$(expr $a + $b) #注意+号前后 空格
echo $c
$((运算式)) 或 $[运算式]
a=1
b=2
c=$(($a+$b))
echo $c
c=$[$a+$b]
#$(())与$()区别
# $() 将系统执行命令返回
# $(()) 做数值运算
d=$(date)
环境变量
set 查看所有环境变量
env 查看环境变量
set -u
unset 变量名 取消环境变量
用户自定义环境变量 export x=1
系统环境变量
PATH
位置参数
$0 命令本身
$# 参数个数
$* 将所有参数看成一个整体
$@ 将每个参数设置独立存在
vim t.sh
#!/bin/bash
echo "程序名称:$0" t.sh
echo "参数1:$1"
echo "参数个数$#"
运行 bash ./t.sh 1

其它:
$? 返回上次自行结果 命令执行终止返回0
$$ 当前京城的进程号
$! 后台运行的最后一个的进程号

















 459
459

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









