




在多模态智能体的发展中,如何像人类一样高效存储并利用长期记忆始终是关键挑战。
M3-Agent 框架为此提出了一种全新的解决方案:它能够接收并处理实时的视觉与听觉输入,将信息转化为实体中心的多模态长期记忆图,同时具备情景记忆 与语义记忆的分层机制。相比传统方法,它在长期信息保持、多模态推理和记忆一致性方面展现出更接近人类的智能特征。
论文链接:https://go.hyper.ai/lGKm9
最新 AI 论文:https://hyper.ai/papers
本周论文推荐
1. Seeing, Listening, Remembering, and Reasoning: A Multimodal Agent with Long-Term Memory
本文介绍了 M3-Agent,一个新型的多模态智能体框架,具备长期记忆能力。 M3-Agent 能够处理实时的视觉和听觉输入,并利用这些信息构建和更新其长期记忆。除了事件记忆外,它还能发展出语义记忆,从而积累关于环境的世界知识。实验结果表明,经过强化学习训练的 M3-Agent 超越了结合 Gemini-1.5-pro 和 GPT-4o 的模型提示的最强基线。
论文链接:https://go.hyper.ai/lGKm9
M3-Bench 长视频问答基准数据集:https://go.hyper.ai/FPR7q
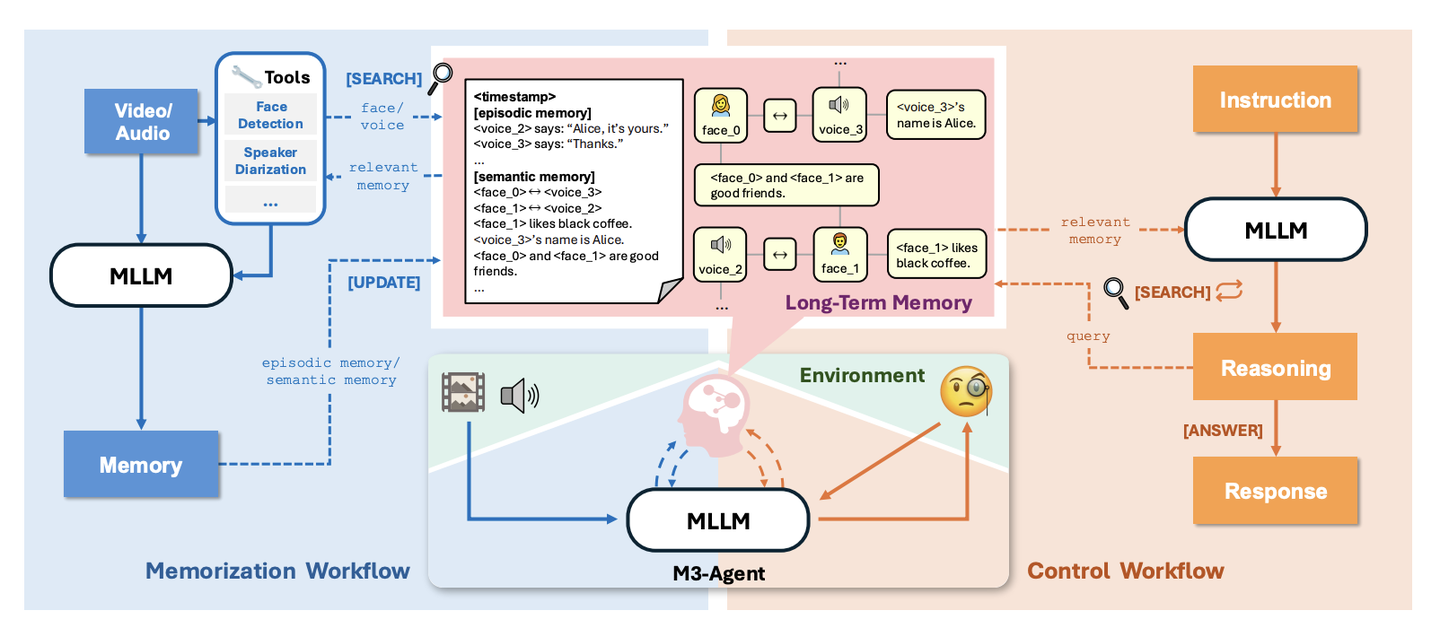
模型架构图
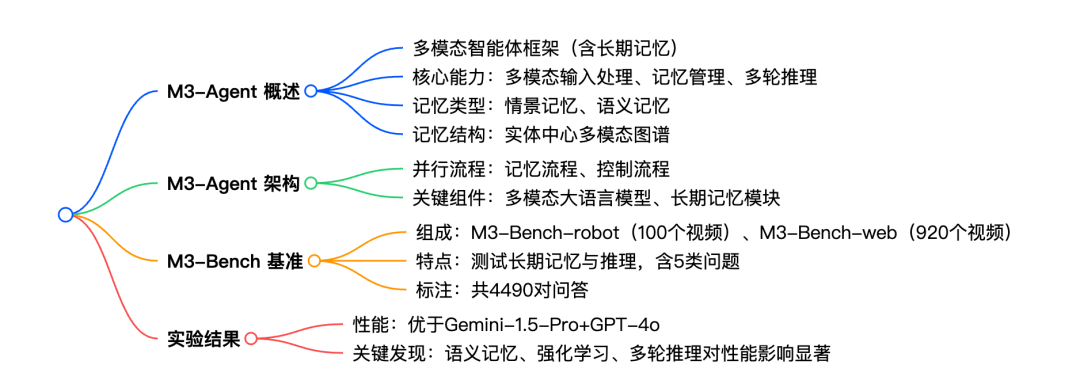
论文思维导图
2.Medical Graph RAG: Towards Safe Medical Large Language Model via Graph Retrieval-Augmented Generation
本文提出了一种面向医疗领域的全新基于图的检索增强生成(RAG)框架,命名为 MedGraphRAG 。该框架旨在提升大型语言模型生成循证医学回答的能力,增强处理私密医疗数据的安全性与可靠性。研究团队在论文中提出两项创新技术:三元组图结构构建与 U-Retrieval 检索机制。
论文链接:https://go.hyper.ai/FIuKc
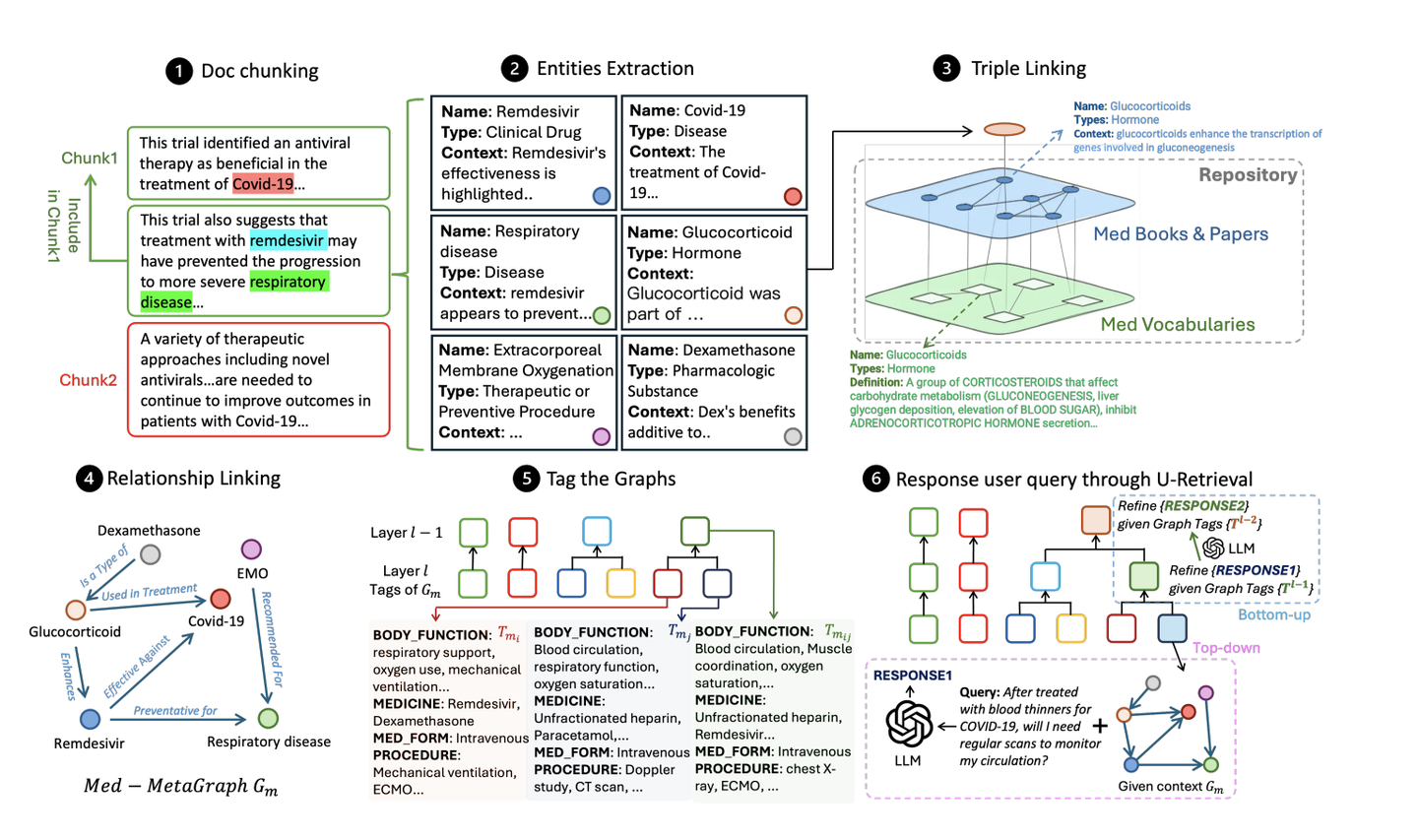
模型架构图
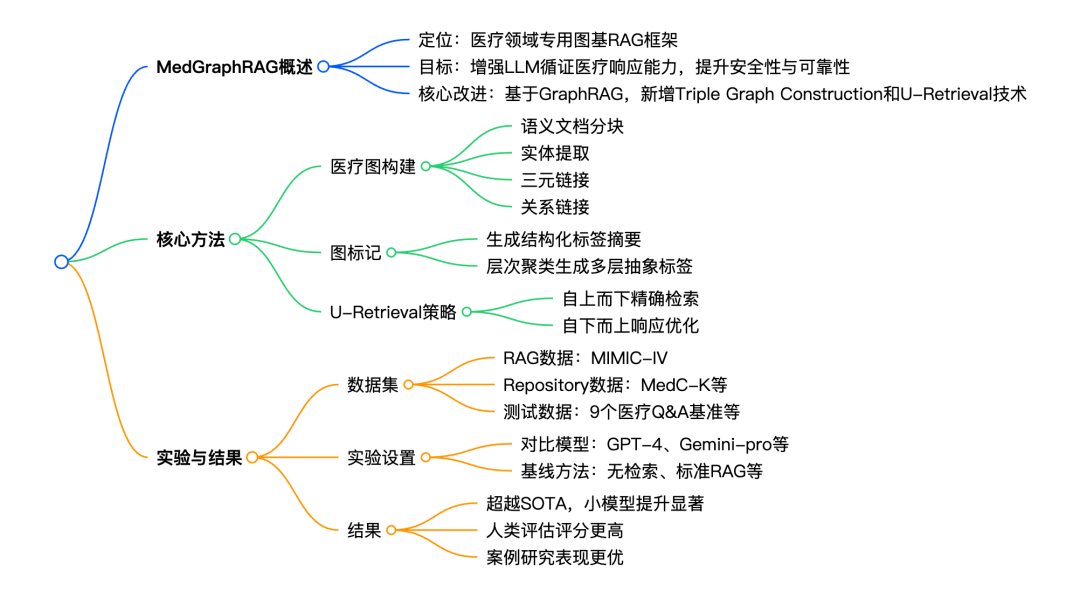
论文思维导图
3.VisCodex: Unified Multimodal Code Generation via Merging Vision and Coding Models
本文介绍了一种新型框架 VisCodex,该框架通过融合视觉和编码模型来增强多模态大语言模型的代码生成能力。此外,研究团队构建了一个名为 Multimodal Coding Dataset(MCD)的大规模多样化数据集,包括高质量的 HTML 代码、图表图像代码对、基于图像的 Stack Overflow 问答以及算法问题。实验结果表明,VisCodex 在多项评估中表现出色,不仅超过了开源的 MLLMs,也接近于领先的企业级模型 GPT-4o 。
论文链接:https://go.hyper.ai/JJtbR
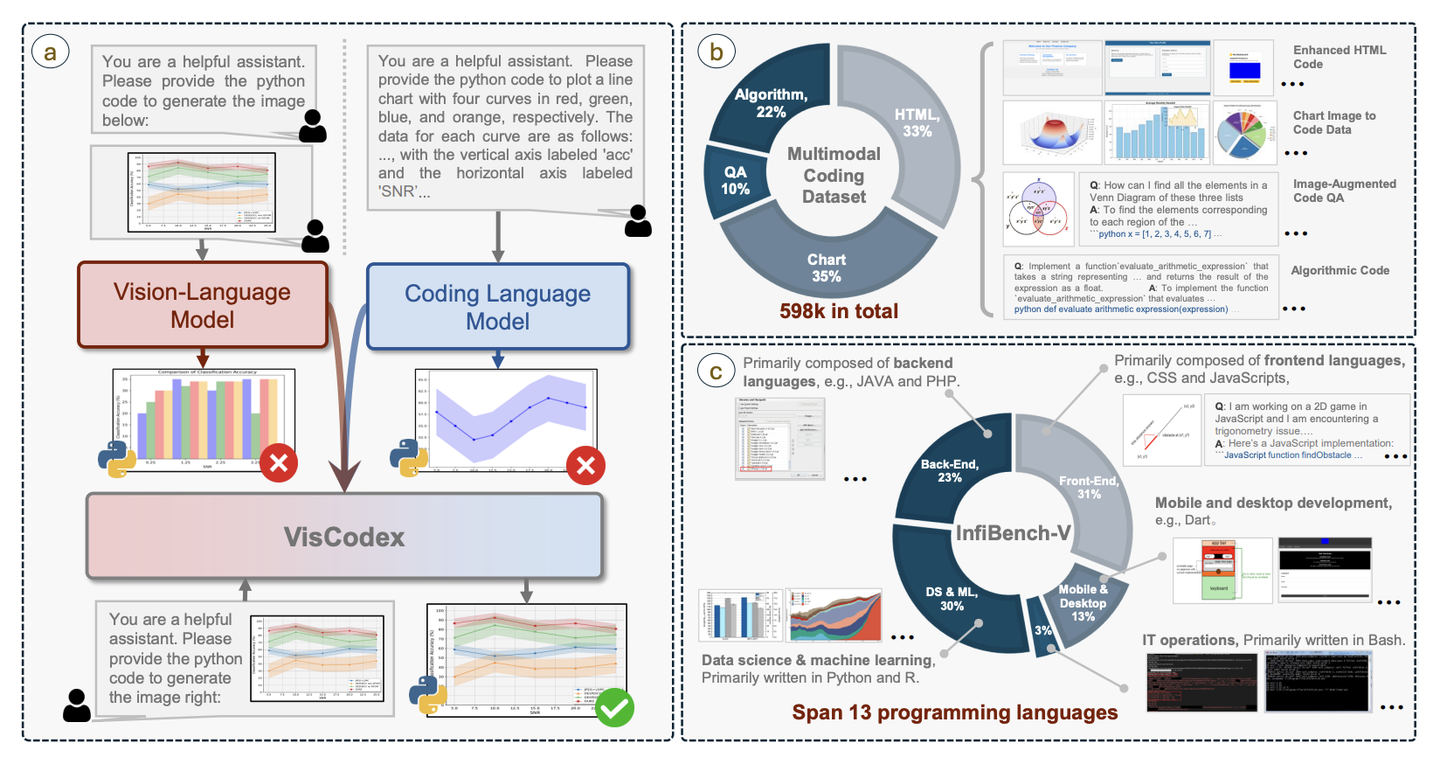
模型架构图
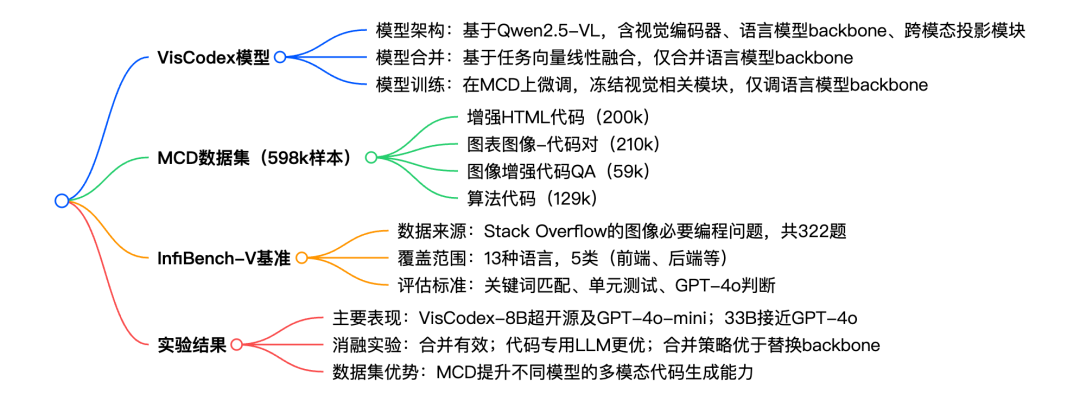
论文思维导图
4.DINOv3
本文提出了一个多功能的自监督视觉基础模型 DINOv3,旨在生成高质量的稠密特征。该模型在多种视觉任务上取得了卓越的表现,显著优于以往的自监督和弱监督基础模型。研究团队还发布了 DINOv3 模型套件,旨在为不同资源约束和部署场景提供可扩展的解决方案。
论文链接:https://go.hyper.ai/lUNDj
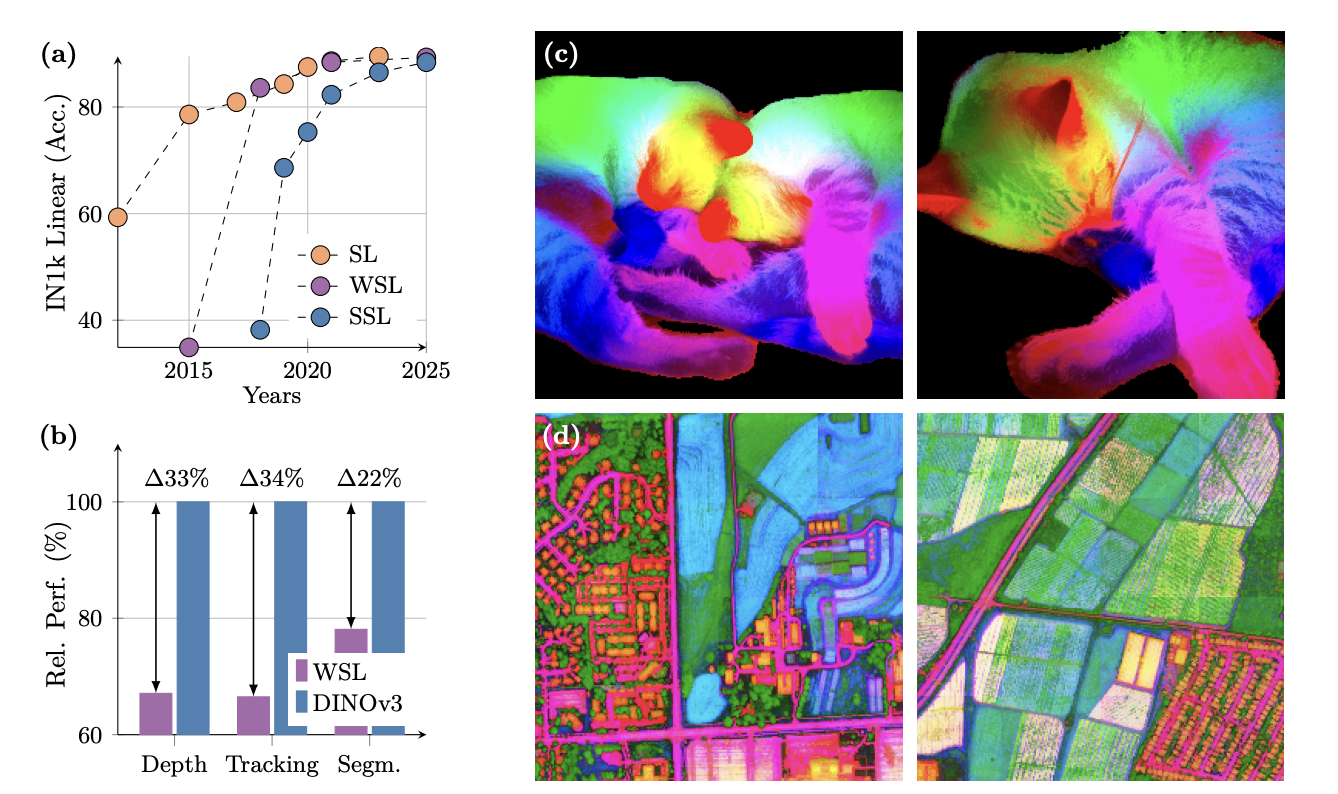
模型架构图
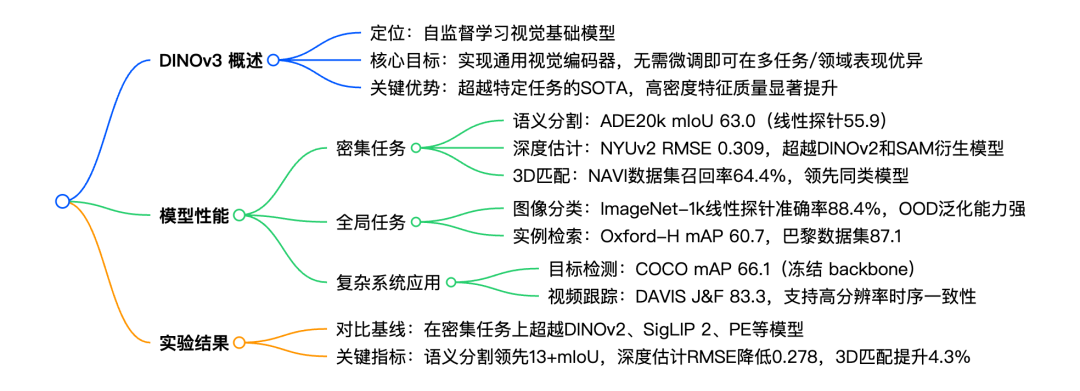
论文思维导图
5.Llama-Nemotron: Efficient Reasoning Models
本文介绍了 Llama-Nemotron 系列模型,一个开放的异构推理模型家族,具备卓越的推理能力、推理效率,并采用面向企业使用的开放许可协议。该系列包含三种规模:Nano(8B)、 Super(49B)和 Ultra(253B),在性能上可与最先进的推理模型相媲美,同时在推理吞吐量和内存效率方面表现更优。
论文链接:https://go.hyper.ai/3INVh
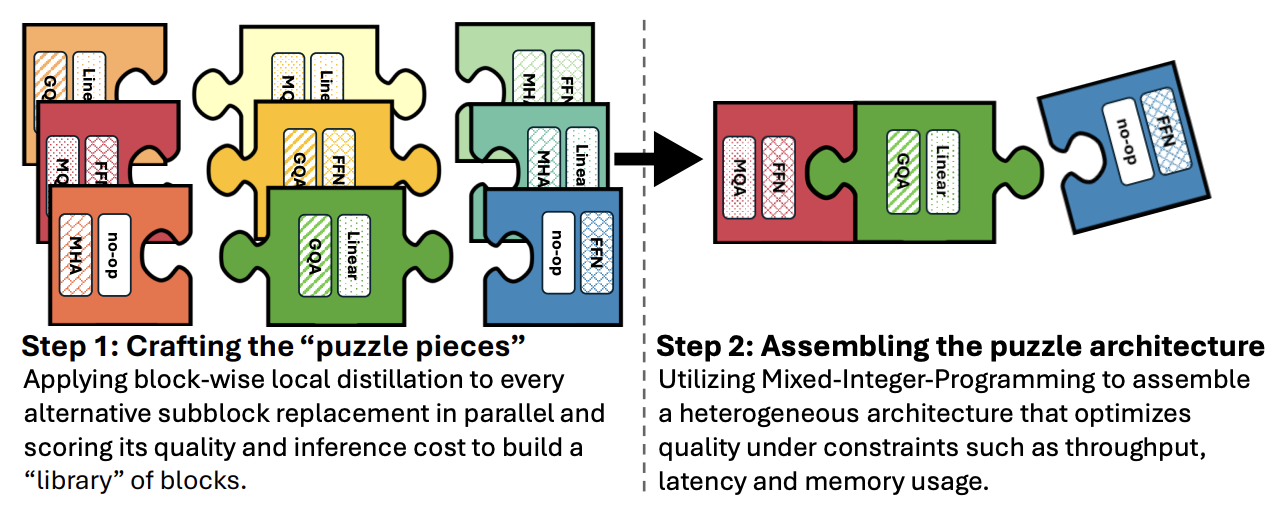
模型架构图

论文思维导图


















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









