




完整内容也可以在公众号「非专业程序员Ping」查看

引言
前面我们讲解了字符与编码,知道了Character与Unicode的关系和区别,也介绍了字符(Character)、字形(Glyph)、字体的区别,并通过实际解析一个Font文件,真正了解到了Font文件中有什么;如果你对这些概念还熟悉,推荐先阅读前面几篇文章打好基础。
作为程序员,日常和文本打交道肯定最多,不知道你是否深入想过这样一个问题:
一段中英日等多国混排的文字,系统(排版引擎)是如何知道怎么排布每个文字的,特别是不同国家的语言排版规则不同,比如中文、英文是从左向右排列,阿拉伯文是从右向左排列的;阿拉伯文会有连字(ligature),中文没有连字;更细节的,为了增强文本的可读性和美观性,系统一般还会将文字紧凑处理(kerning)、连字处理(ligature)等,排版引擎在其中到底做了哪些事情,每一步的基本原理又是怎么样的,本文将带你逐步揭开排版引擎的神秘面纱。
通过本文,或许你也能自定义一个文字排版引擎了。
一、文本预处理/Unicode归一化
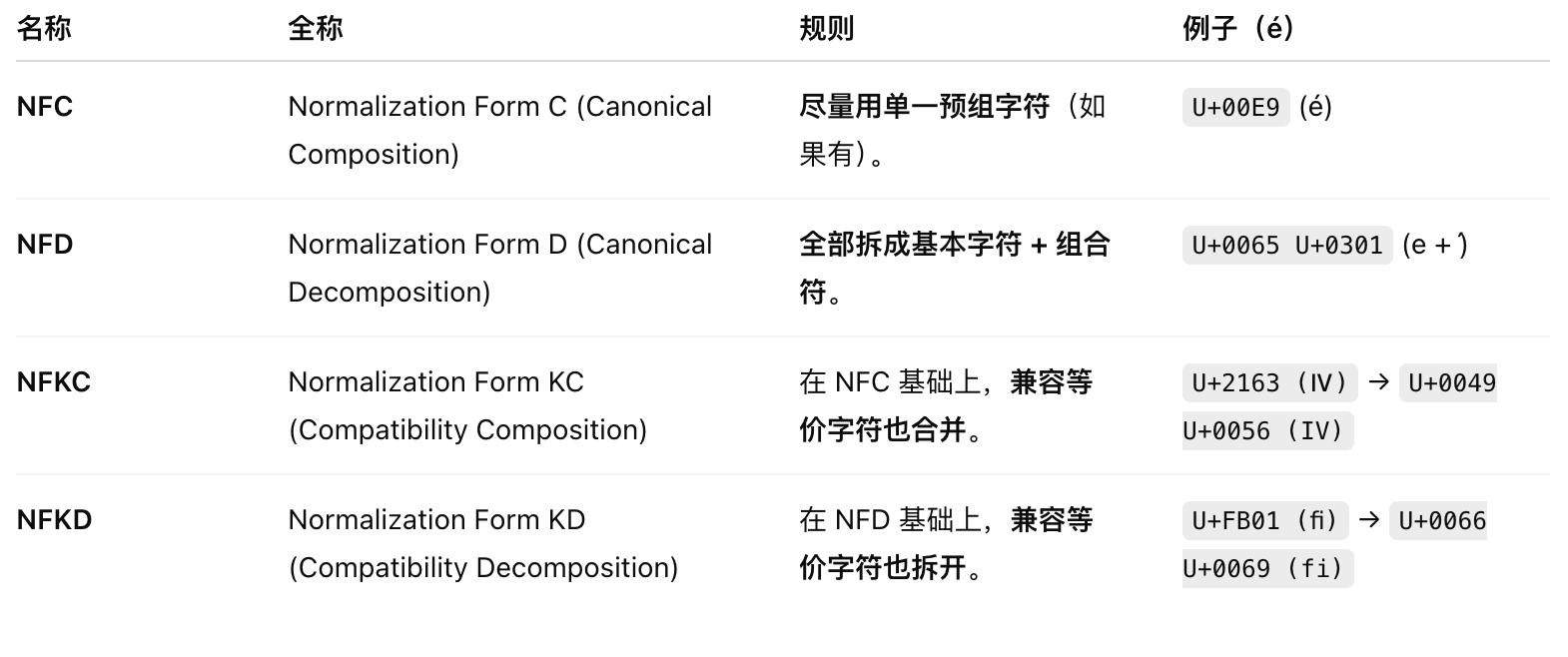
在字符与编码一文中,我们知道同一个字符可能对应多个code point,比如👨👩👧对应U+1F468 + U+200D + U+1F469 + U+200D + U+1F467 ;甚至Unicode为了兼容历史编码,也允许一个字符有多种表示方法,比如é可以表示为:单一code point(U+00E9),组合code point(U+0065 + U+0301)。
预处理就是保证字符串在进行排版/字形选择(shaping)之前是稳定、唯一、可预测的,避免因为 Unicode 的多种表示方法导致排版不一致,比如避免é被分开成e和 ́排版渲染。
预处理一般步骤是:
- 编码转换:将字符统一成UTF-32编码
- 规范化(Normalization):NFC/NFD/NFKC/NFKD等,Web 标准和绝大多数现代系统都默认使用NFC
Q:NFC/NFD/NFKC/NFKD是什么
这些是Unicode标准里定义的几种规范化形式,区别是:
二、分段
为什么要分段:不同国家、语言的排版规则不同,比如阿拉伯文有连字、中文没有,阿拉伯文从右到左排,中文从左往右排,分段之后方便后续的字体选择和shaping,比如HarfBuzz 这样的 shaping 引擎一次只能处理一个 Script run
分段就是把字符串按 Unicode Script (Latin, Han, Hiragana, Katakana 等) 划分成 run(分组)。
原理比较简单,Unicode 为每个 code point 定义了一个 Script 属性,遍历字符串,按 Script 属性连续分段即可。
比如对于Hello世界あい,从左往右扫描字符串,每遇到 Script 改变,就切分出一个 run,最后会被划分成:
Hello" → Latin世界→ Hanあい→ Hiragana
特殊情况:
有些字符的 Script = Common(标点、数字、空格)或 Inherited(音调符号、声调标记),这些字符分段时需要特殊处理,规则一般是:
- 如果是 Common → 继承相邻 run 的 Script(如果左右run都有Script,一般跟随左边;如果左边没有run,比如开头就是空格,那就跟随右边;如果左右都没有run,比如
!!!,那整体就是一个Common run)。 - 如果是 Inherited → 附着到前一个 base 字符的 Script。
比如:
世界! → “世界” (Han) + “!” (也归 Han run)
é (e + 重音符) → 整体算 Latin
三、双向文本处理(BiDi)
BiDi就是将字符从逻辑顺序处理成视觉顺序,计算机里字符串总是按逻辑顺序存储(用户输入顺序),但在渲染时,不同语言有不同的书写方向,比如中文、英文从左往右排列,阿拉伯文、希伯来文从右往左排列,如果一段文本中既有中文、英文,又有阿拉伯文、希伯来文,那还得处理混排时的顺序,BiDi就是处理混排情况下文本的实际显示顺序的。
在后续的例子中,为了方便演示,我们假设以小写字母作为LTR,以大写字母作为RTL,比如:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









