






文章首发网址:星星点灯的技术栈(https://www.xxdiandeng.cn),欢迎关注点灯君的原创博客网站!
C++基础知识
C++ 源文件和编码规范
代码文件/程序文件
Header file 头文件
Source file 源文件
例如:
world.h 是头文件
world.hpp 是头文件
world.cpp 是源文件
world.cxx 是源文件
geosoft.no的编码风格指南(英文版)
https://geosoft.no/development/cppstyle.html
第一个C++程序
#include <iostream>
using std::cout;
using std::endl;
int main() {
// 在控制台上显示 Aloha world.
cout << "Aloha world!" << endl;
return 0;
}
编码规范:
Special characters like TAB and page break must be avoided
不准使用“制表”和“分页”等特殊字符。
因此,在IDE中,将“制表符”设置并替换为4个空格。
Functions must always have the return value explicitly listed.
函数必须总是将返回值明确列出。
若你不写返回值,编译器会默认返回
int,这会让不了解此特性的程序员晕掉
C++ 标准库头文件
#include <iostream>尖括号内无扩展名
namespace 名字空间
- 不要使用
using namespace std,易造成名字冲突 - 但可以使用
using std::cout;,省略std
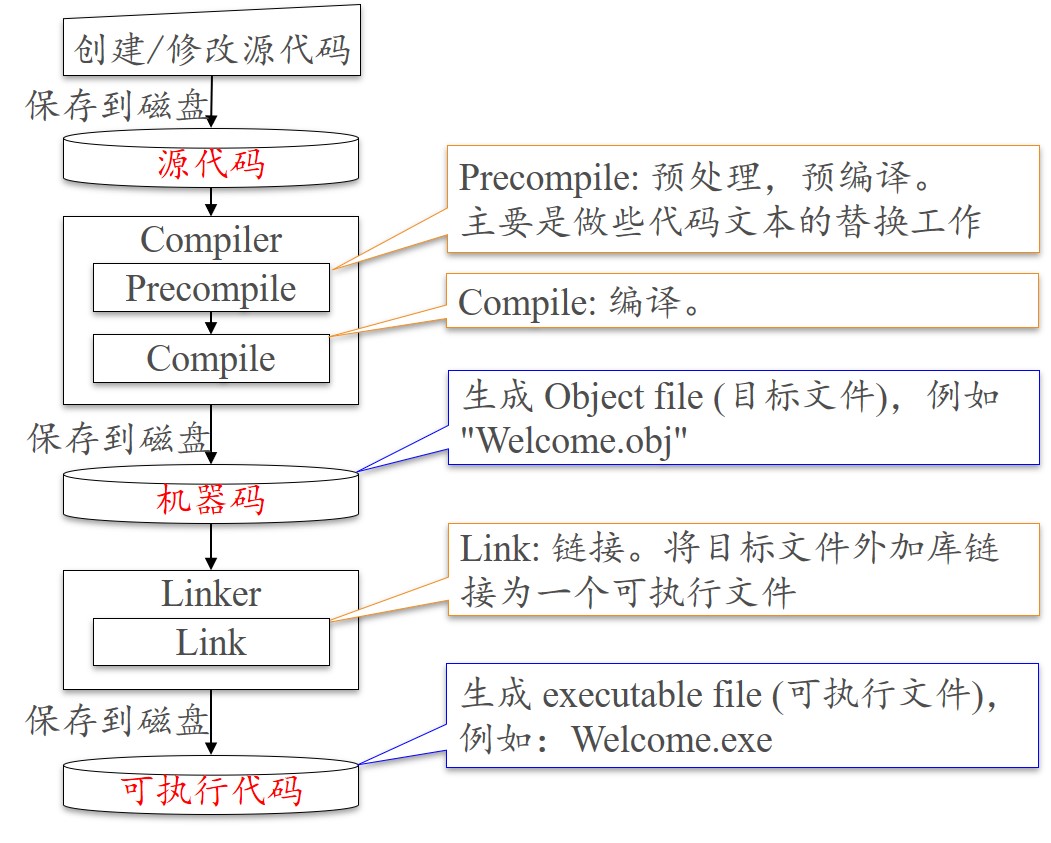
编译C++程序的步骤
预处理–>编译–>生成目标文件(.obj)–>链接,生成可执行文件(.exe)
输入与输出
输入输出的分类:
- Standard I/O (标准IO)
- File I/O(文件IO)
- String I/O(字符串IO)
- Network I/O(网络IO)
输入输出流
C++ uses streams to perform input and output in media such as the screen, the keyboard or a file.
C++使用一种叫做“流”的概念对屏幕、键盘或者文件进行输入输出操作
cin:标准输入流cout:标准输出流
运算符与函数
-
⭐
cin >>:">>" 流提取运算符 -
⭐
cout <<:"<<" 流插入运算符 -
cin.get()从流中读并取走一个字符 -
cin.getline()从流中读取字符,直至行尾或指定的分隔符 -
cin.ignore()从流中读取并舍弃指定数量的字符 -
cout.put()将字符写到流中(无格式) -
cout.flush()将流中缓存内容全部输出
引用
-
引用就是另一个变量的别名
-
通过引用所做的读写操作实际上是作用于原变量上
-
引用必须在声明的时候初始化
-
引用一旦初始化,引用名字就不能再指定给其它变量
// To declare a reference variable
int x;
int& rx = x;
// or
int x, &rx = x;
/* '&' 放在定义中是引用 */
编码规范:
C++ pointers and references should have their reference symbol next to the type rather than to the name.
C++指针与引用符号应靠近其类型而非名字。
例如:
float* x; // NOT: float *x; int& y; // NOT: int &y;
-
关于字符串引用:
C++11标准规定,字符串必须定义为常量指针。
const char* s = "hello"; const char* t = "world"; const char*& r = s; r = t; // 相当于s = t; std::cout << r << std::endl; std::cout << s << std::endl;
函数传参
You can use a reference variable as a parameter in a function and pass a regular variable to invoke the function. (引用可做函数参数,但调用时只需传普通变量即可)
When you change the value through the reference variable, the original value is actually changed. (在被调函数中改变引用变量的值,则改变的是实参的值)
示例:Swap函数
void swap(int &x, int &y) {
int t;
t = x; x = y; y = t;
}
int main() {
auto a{5}, b{10};
cout << "Before: a=" << a << " b=" << b << endl;
swap(a, b);
cout << "After: a=" << a << " b=" << b << endl;
return 0;
}
空指针与动态内存分配
空指针
C++11中引入保留字 “nullptr” 作为空指针。
实例:
void codeExample() {
auto x{10};
int* p = nullptr;
int* q{nullptr};
q = &x;
}
动态内存分配
- C++中通过运算符
new申请动态内存
new <类型名> (初值) ; //申请一个变量的空间
new <类型名>[常量表达式] ; //申请数组
如果申请成功,返回指定类型内存的地址;
如果申请失败,抛出异常,或者返回空指针(nullptr)。(C++11)
- 动态内存使用完毕后,要用delete运算符来释放。
delete <指针名>; //删除一个变量/对象
delete [] <指针名>; //删除数组空间
数据类型及转换、列表初始化
布尔数据类型
C++语言在其标准化过程中引入了bool、true和false关键字,增加了原生数据类型来支持布尔数据。
bool isMyBook;
bool isRunning = {false}; //C++11 列表初始化方式
bool isBoy( );
bool hasLicense();
bool canWork();
bool shouldSort();
编码规范:
The prefix is should be used for boolean variables and methods.
布尔变量/函数的命名应使用前缀“is”
例如:isSet, isVisible, isFinished, isFound, isOpen
布尔值与整型的转换
0 <--> false // 整数0和布尔false互相转化
true -> 1 // 布尔true转化为整数1
non-zero -> true // 任意非0整数转化为布尔true
问题:‘a’->?
'a’的ASCII码为97,所以为true
关系运算得到布尔值
关系运算(Relational Operation)包括:==, !=, <=, >=, <, >
int a=0, b={1}; //C++11
3 == a;
b < a;
3.2 >= b;
if (3 == a) {
// blah blah
}
逻辑运算得到布尔值
逻辑运算(Logical Operation)包括:&&, ||, !
int a={0}, b{1}; //C++11
a && b;
b || 18;
!a;
while (!a) {
// blah blah
}
代码示例
#include <iostream>
int main() {
bool isAlpha;
isAlpha = false;
if (!isAlpha) {
std::cout << "isAlpha=" << isAlpha << std::endl;
std::cout << std::boolalpha <<
"isAlpha=" << isAlpha << std::endl;
}
return 0;
}
std::boolalpha 将布尔变量输出为true/false
编码规范:
The incompleteness of split lines must be made obvious.
断行必须很明显。
在逗号或运算符后换行,新行要对齐
列表初始化
列表初始化是使用大括号对变量等实体进行初始化。
- C++11标准之前的初始化方法
int x = 0;
int y(2);
char c('a');
int arr[] = { 1,2,3 };
char s[] = "Hello";
C++11标准仍然支持旧的初始化方法
直接列表初始化
//直接列表初始化
/* Variable initialization */
int x{}; // x is 0;
int y{ 1 }; // y is 1;
/* Array initialization */
int array1[]{ 1,2,3 };
char s1[ 3 ] { 'o', 'k' };
char s3[]{ "Hello" };
拷贝列表初始化
//拷贝列表初始化
/* Variable initialization */
int z = { 2 };
/* Array initialization */
int array2[] = { 4,5,6 };
char s2[] = { 'y','e','s' };
char s4[] = { "World" };
char s5[] = "Aloha"; // Omit curly braces (省略花括号)
尽量使用列表初始化
尽量使用列表初始化,除非你有个很好的不用它的理由
原因:列表初始化不允许“窄化”,即不允许丢失数据精度的隐式类型转换
类型转换
C 风格的强制(显示)类型转换:
(int)2.5
C++ 风格的强制(显示)类型转换:
static_cast<type> value
cout << static_cast<double>(1) / 2;
cout << static_cast<double>(1 / 2);
编码规范:
Type conversions must always be done explicitly. Never rely on implicit type conversion.
类型转换必须显式声明。永远不要依赖隐式类型转换
例如:
floatValue = static_cast<float>(intValue); // NOT: floatValue = intValue;
[C++11]自动类型推导
关键字auto
C++03及之前的标准中,auto放在变量声明之前,声明变量的存储策略。但是这个关键字常省略不写。
C++11中,auto关键字放在变量之前,作用是在声明变量的时候根据变量初始值的类型自动为此变量选择匹配的类型。
int a = 10;
auto au_a = a;//自动类型推断,au_a为int类型
cout << typeid(au_a).name() << endl;
typeid().name(),用于显示某些变量/类型的信息,包含在头文件typeinfo中。
auto的使用限制
- auto 变量必须在定义时初始化,这类似于const关键字
auto a1 = 10; //正确
auto b1; //错误,编译器无法推导b1的类型
b1 = 10;
- 定义在一个auto序列的变量必须始终推导成同一类型
auto a4 = 10, a5{20}; //正确
auto b4{10}, b5 = 20.0; //错误,没有推导为同一类型
- 如果初始化表达式是引用或const,则去除引用或const语义。
int a{10}; int &b = a;
auto c = b; //c的类型为int而非int&(去除引用)
const int a1{10};
auto b1 = a1; //b1的类型为int而非const int(去除const)
- 如果auto关键字带上&号,则不去除引用或const语意
int a = 10; int& b = a;
auto& d = b;//此时d的类型才为int&
const int a2 = 10;
auto& b2 = a2;//因为auto带上&,故不去除const,b2类型为const in
- 初始化表达式为数组时,auto关键字推导类型为指针。
int a3[3] = { 1, 2, 3 };
auto b3 = a3;
cout << typeid(b3).name() << endl; //输出int * (输出与编译器有关)
- 若表达式为数组且auto带上&,则推导类型为数组类型。
int a7[3] = { 1, 2, 3 };
auto& b7 = a7;
cout << typeid(b7).name() << endl; //输出int [3] (输出与编译器有关)
- C++14中,auto可以作为函数的返回值类型和参数类型
Almost Always Auto (AAA) 原则
Using auto are for correctness, performance, maintainability, robustness—and convenience (使用auto是为了代码的正确性、性能、可维护性、健壮性,以及方便),例如:保证在声明变量时即初始化
- “int x = 3;” 能变成auto形式吗?
当我们非常希望能够在变量定义的时候,【明确】地指出变量的类型,而且不希望随便更改其类型,那么我们可以使用下面的方法:
auto x = int {3}; // 初始化列表
auto y = int {3.0}; // 编译器报错,初始化列表不能窄化
auto z = int (3.0); // C风格的强制类型转换,z的值是整数3
- auto和初始化列表一起用
要避免在一行中使用直接列表初始化和拷贝列表初始化,也就是,下面的代码是有问题的:
auto x { 1 }, y = { 2 }; // 不要同时使用直接和拷贝列表初始化
- 一些例子
| Classic C++ Style (经典C++风格) | Modern C++ Style(现代C++风格) |
|---|---|
| int x = 42; | auto x = 42; |
| float x = 42.; | auto x =42.f; |
| unsigned long x = 42; | auto x = 42ul; |
| std::string x = “42”; | auto x = "42"s; //c++14 |
| chrono::nanoseconds x{ 42 }; | auto x = 42ns; //c++14 |
| int f(double); | auto f (double) -> int; |
auto f (double) { /*…*/ }; | |
auto f = [](double) { /*… */ }; //匿名函数 |
关键字decltype
decltype利用已知类型声明新变量。
在编译时期推导一个表达式的类型,而不用初始化,其语法格式有点像sizeof
#include<iostream>
using namespace std;
int fun1() { return 10; }
auto fun2() { return 'g'; } // C++14
int main(){
// Data type of x is same as return type of fun1()
// and type of y is same as return type of fun2()
decltype(fun1()) x; // 不会执行fun1()函数
decltype(fun2()) y = fun2();
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
return 0;
}
decltype 主要用于泛型编程(模板)
简化的C++内存模型
4种内存模型

Stack (栈)
- 局部变量,编译器自动分配释放
- 栈向低地址方向生长
Heap (堆)
- 一般由程序员分配释放(
new/delete),若程序员不释放,程序结束时可能由OS回收 - 堆向高地址方向生长
Global/Static (全局区/静态区)
- 全局变量和静态变量的存储是放在一块的。
- 可以简单认为:
- 程序启动全局/静态变量就在此处
- 程序结束释放
Constant (常量区)
- 可以简单理解为所有常量都放在一起
- 该区域内容不可修改
普通变量内存模型
int a, b=0; a=b;
-
a和b都是变量的名,对a和b的访问实际上访问的是a和b这两个变量中存储的值 -
a和b的地址分别是&a和&b
数组内存模型
- 对于数组
a[],a是数组a[]的首地址的别名 - 要访问每个数组元素的值,使用
a[0],a[1],… - 要访问一个地址所存的内容,使用 “
*”- 访问数组中第一个元素可以使用
*(a+0) - 访问数组中第二个元素
*(a+1)
- 访问数组中第一个元素可以使用
常量与指针
命名常量/符号常量
const datatype CONSTANTNAME = VALUE;
等号右边的VALUE被称为字面常量
const double PI = 3.14159;
const int SIZE = 3;
int const X = 5;
const char C = 'k';
const char* STR = "hello";
PI = 3.14; // Error!
C++中字符串常量必须以const定义!(如第5行)
编码规范:
Named constants (including enumeration values) must be all uppercase using underscore to separate words.
符号常量(包括枚举值)必须全部大写并用下划线分隔单词
例如:MAX_ITERATIONS, COLOR_RED, PI
常量和指针
指针变量:
int x = 5;
int* p = &x;
常量指针,const在“*”前面,表示指针所指的内容不能通过间接引用(*p)改变:
const int x = 1;
const int* p1;
p1 = &x; //指针 p1的类型是 (const int*)
*p1 = 10; // Error!
char* s1 = "Hello"; // Error!
const char* s2 = "Hello"; // Correct
指针常量,const在“*”后面,表示指针本身地址不能改变(即不能再指向其他地方):
int x = 1, y = 1;
int* const p2 = &x; //常量 p2的类型是 (int*)
*p2 = 10; // Okay! --> x=10
p2 = &y; // Error! p2 is a constant
数组名是一个指针常量。
常量指针常量:一个常量中存着一个指针,这个指针又指向另外一个常量:
int x = 5;
const int* const p = &x;
- 总结
- (指针)和 const(常量) 谁在前先读谁
- 代表被指的数据,名字代表指针地址
- const在谁前面谁就不允许改变。
#define、typedef、using
#define
#define,用来定义“宏”(macro),是一个预处理指示符
#define MACRONAME Something,将程序中的所有MACRONAME替换为something
如:#define TRUE 1,结尾无分号,将会把程序里所有出现TRUE的地方替换为1
typedef
typedef创建能在任何位置替代类型名的别名。
-
typedef SomeType NewTypeName -
如:
typedef _Bool bool;,C99中没有bool关键字,所以在<stdbool.h>中这样定义一个
using
用来替代typedef。
语法:using identifier = type-id;
// 类型别名,等同于 typedef unsigned int UInt;
using UInt = unsigned int;
// 名称'UInt'现指代类型
UInt x = 42u;
// 类型别名,等同于 typedef void (*FuncType)(int, int);
using FuncType = void (*) (int, int);
// 名称'FuncType'现在指代指向函数的指针
void example (int, int) {}
FuncType f = example;
using 只能用于类型,如:using MyCin = std::cin 是错误的,因为 std::cin 是一个对象。
编码规范:
Names representing types must be in mixed case starting with upper case.
代表类型的名字必须首字母大写并且其它字母大小写混合
例如:Line, SavingsAccount
特殊函数
变量的作用域分类
a. 全局作用域:全局变量
b. 局部作用域:局部变量
局部作用域可以分为:文件作用域、函数作用域以及函数内部的块作用域。
如果外部代码块与其内嵌代码块有同名的变量,那么会产生同名覆盖这种现象。此时要遵循“就近原则”来判断哪个同名变量起作用
一元作用域解析运算符
局部变量名与全局变量名相同时,可使用 :: 访问全局变量
:: 这个运算符被称为一元作用域解析运算符
#include <iostream>
int v1 = 10;
int main() {
int v1 = 5;
std::cout << "local variable v1 is " << v1 << std::endl;
std::cout << "global variable v1 is " << ::v1 << std::endl;
return 0;
}
重(Chóng)载函数
重载函数(Overloading Functions)是在同一个名字空间中存在两个或者多个具有相同名字的函数所构成的语法现象。
#include <iostream>
using std::cout;
using std::endl;
int max (int num1, int num2);
double max (double num1, double num2);
int main () {
cout << max(1, 2) << endl;
cout << max(1.5, 2.5) << endl;
return 0;
}
// 用于处理int类型
int max (int num1, int num2) {
if (num1 > num2)
return num1;
else
return num2;
}
// 用于处理double类型
double max (double num1, double num2) {
if (num1 > num2)
return num1;
else
return num2;
}
-
调用重载函数的语句,是由编译器在编译期确定的。
-
编译器判断某个函数调用语句所对应的重载函数时,判断依据是函数参数的类型、个数和次序。
-
如果编译器无法判定,就会报告二义性错误。
函数默认参数
函数的参数可以指定默认值。
int max (int x, int y = 0);
int main() {
cout << max(1) << endl;
}
调用带有默认参数值的函数时,如果不指定带有默认值的参数,则该参数自动被赋为默认值(如max(1))
-
定义时:
指定默认值时,要保证带有默认值的参数要位于函数参数列表的右侧。
void t1 (int x, int y = 0, int z); // ERROR void t2 (int x, int y = 0, int z = 0); // CORRECT void t3 (int x = 0, int y = 0, int z = 0); // CORRECT -
调用时:
参数列表中实参应前置。
t2 (1, ,20); // ERROR t3 (, , 20); // ERROR t3 (1,20); // CORRECT t3 (8); // CORRECT -
函数重定义/声明时,不允许重定义默认参数!
int Add (int a, int b = 3); // 原型声明 int Add (int a, int b = 3) { // 错误!不能重定义默认参数值,正确做法是:将"=3"删去 // 尽管与原型声明相同 }
内联函数
普通函数的优缺点
- Pros(优点): 易读易维护
- Cons (缺点): 调用时有开销
函数调用时:参数及部分CPU寄存器的内容进栈,控制流跳转
函数返回时:返回值及寄存器值出栈,控制流跳转
内联(Inline functions)函数:
-
目的:减小函数调用开销
-
方法:代码插入到调用处(以空间换时间)
-
结果:导致程序变大
声明、定义内联函数:
// 定义内联函数
inline int max (int a, int b) {
return (a > b ? a : b);
}
内联函数的声明和定义一般不分开。
调用内联函数:
// Calling (调用内联函数)
int x = max (3, 5);
int y = max (0, 8);
内联展开,实际工作时,直接在源代码处展开函数:
int x = (3 > 5 ? 3 : 5);
int y = (0 > 8 ? 0 : 8);
内联函数适用于频繁调用的短函数。不适用于多处调用的长函数。
编译器在遇到内联函数的调用时,会将内联函数的函数体展开到调用位置,从而避免函数调用的开销。
一般来说,内联函数只有在需要考虑程序运行性能的环境中才使用。
程序员所用的 inline 关键字,只是对编译器的一个请求。内联函数是否展开,是由编译器决定的。
[C++11]基于范围的for循环
语法
语法:for(元素名变量 : 广义集合) { 循环体 }
- “元素名变量”可以是引用类型,以便直接修改集合元素的值;
- “元素名变量”也可以是const类型,避免循环体修改元素的值;
- 其中“广义集合”就是“Range(范围)”,是一些元素组成的一个整体
广义集合例子:
-
int a1[] {1,3,5,7};不能用
auto关键字声明原始数组。(也就是C语言风格的数组)同时,在C++程序中,应弃用原始数组,改用
std::array。 -
std::array<int,4>a2{2,4,6,8}; -
std::vector<int>v={42,7,5}; -
std::vector<std::string>s{"Hello","World","!};
用法实例
想要操作某个广义集合中的所有元素,那么只需要关心
-
a. 从集合中取出某个元素
-
b. 保证所有元素都被遍历
例:把数组a的元素都输出到屏幕上;然后把数组的元素翻倍
int a[] = { 2,1,4,3,5 };
for (auto i : a) {
std::cout << i << std::endl;
}
for (auto& i : a) {
i = 2 * i;
}
限制
基于范围的循环仅限于for语句
do…while(); 和while(){} 不支持基于范围的循环
[C++17]带有初始化器的if和switch语句
if语句
-
不带有初始化器:
int foo(int arg) { // do something return (arg); } int main() { auto x = foo(42); if (x > 40) { // do something with x } else { // do something with x } // auto x = 3; } -
带有初始化器:
int foo(int arg) { // do something return (arg); } int main() { // auto x = foo(42); if (auto x = foo(42); x > 40) { // do something with x } else { // do something with x } auto x = 3; // 名字 x 可重用 }
x的作用域在两个代码块中不同。
有什么用:
-
The variable, which ought to be limited in if block, leaks into the surrounding scope
本应限制于if块的变量,侵入了周边的作用域
-
The compiler can better optimize the code if it knows explicitly the scope of the variable is only in one if block
若编译器确知变量作用域限于if块,则可更好地优化代码
switch语句
Synatx: switch(initializer;variable)
实例:
switch (int i = rand() % 100; i) {
case 1:
// do something
default:
std::cout << "i = " << i << std::endl;
break;
}

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









