







 本文档详细介绍了如何在 IntelliJ IDEA 中使用 Maven 创建非骨架工程,学习 Elasticsearch 的原生 Java API。从设置 JDK 版本、添加依赖到创建索引、设置 mapping、添加 document、搜索数据、分页查询以及高亮显示,每个步骤都有清晰的代码示例。通过 JUnit 测试用例展示了如何连接 ES 集群、创建索引、添加 JSON 数据、使用 QueryBuilder 进行搜索和高亮等操作。
本文档详细介绍了如何在 IntelliJ IDEA 中使用 Maven 创建非骨架工程,学习 Elasticsearch 的原生 Java API。从设置 JDK 版本、添加依赖到创建索引、设置 mapping、添加 document、搜索数据、分页查询以及高亮显示,每个步骤都有清晰的代码示例。通过 JUnit 测试用例展示了如何连接 ES 集群、创建索引、添加 JSON 数据、使用 QueryBuilder 进行搜索和高亮等操作。
【1】创建maven工程,不需要骨架,普通的即可,因为我们是为了学习es在idea上怎么使用,而不是开发项目。
【2】导入jar包坐标
这里很多东西中央仓库都没有,而且加载又慢,顺便提一嘴,把maven的config文件夹下的conf-setting.xml中添加阿里的云端
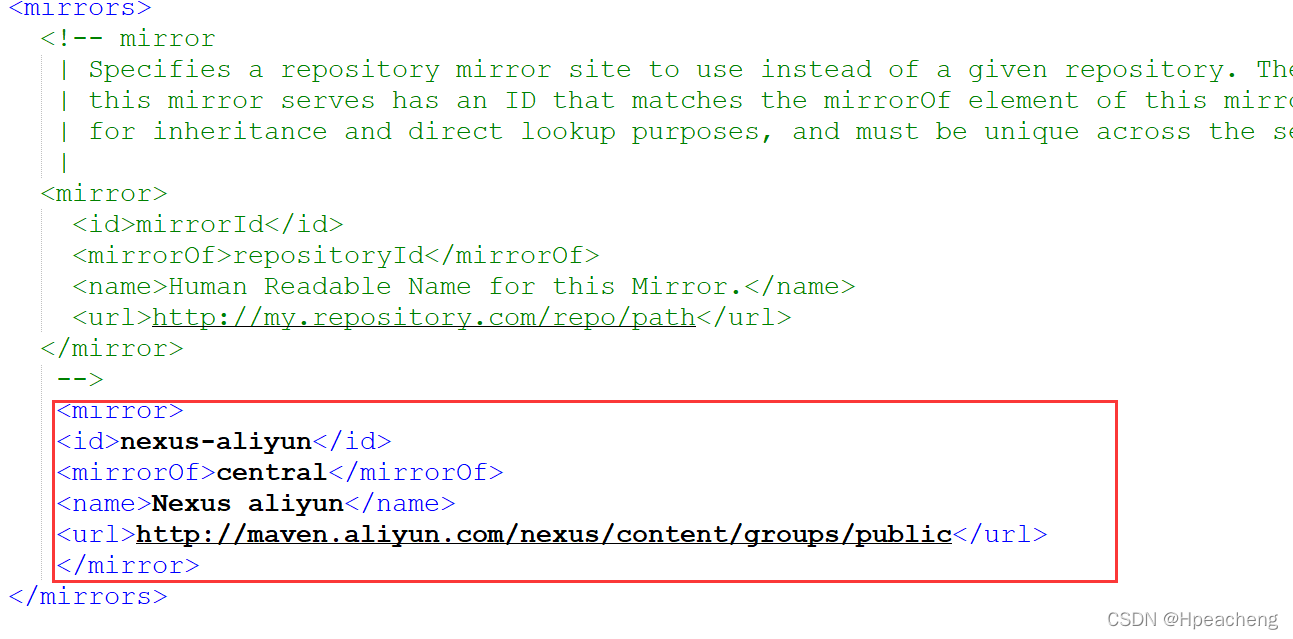
记得要把jdk手动设置成1.9,因为idea默认用1.5
<properties>
<maven.compiler.source>1.9</maven.compiler.source>
<maven.compiler.target>1.9</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
【3】我们先学习下原生的es在java中如何使用(不适用springdata框架)
获取连接步骤:
1.创建一个setting对象,用来设置我们的es-cluster集群名称,来获取到我们的es集群
2.创建一个TranspotClient对象,他有一个字类PreBuiltTransportClient,可以把我们的setting写入。获取到cilent客户端对象。
3.用client.addTransportAddress添加我们的主机地址和端口号,这里的端口号不是http的端口号了,而是TCP的
4.最后使用client,创建一个索引库
5.关闭索引库
@Test
public void createIndex() throws Exception{
// 编写测试方法实现创建索引库
// 1、创建一个Settings对象,相当于是一个配置信息。主要配置集群的名称。
//put中这只集群的name,获取我们配置好的cluster集群
Settings settings=Settings.builder().put("cluster.name","my-elasticsearch").build();
// 2、创建一个客户端Client对象
//除了设置集群的名称,还需要设置我们的端口号,这里注意端口号不是http,而是tcp
//为了防止某个节点挂了,所以三个全设置上。
TransportClient client=new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9303));
// 3、使用client对象创建一个索引库
client.admin().indices().prepareCreate("hello").get();//设置索引库名称并且创建,get是执行这个索引操作
// 4、关闭client对象
client.close();
}
【4】索引库创建了,自然也要设置mapping,也就是我们的域,一共有两种方式可以把我们的mapping的json格式弄出来。一种是拼接json字符串,另一种是用XcontentBuilder方法,也会转成json。不过不管用哪一种,都非常麻烦
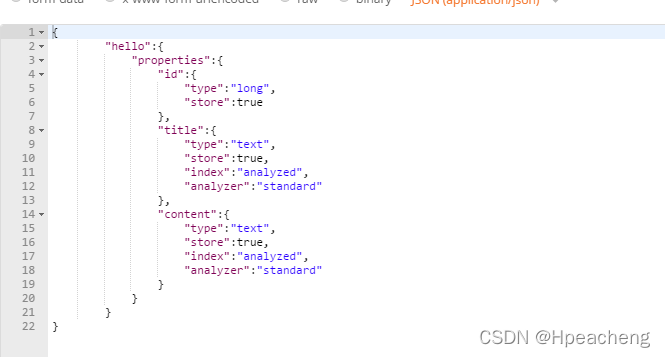
先来一张用postman创建的mapping,这样两个对比比较好理解
startObject就代表{
写了参数的startObject(参数)就代表:参数{
endobject就代表}
field就代表域中的属性
XContentBuilder builder= XContentFactory.jsonBuilder()
.startObject() //相当于{
.startObject("article") //相当于type的名字 article:{
.startObject("properties") //properties:{
.startObject("id") //id:{
.field("type","long")
.field("store",true)
.endObject()//}
.startObject("title") //title:{
.field("type","text")
.field("store",true)
.field("index",true)
.field("analyzer","ik_smart")
.endObject()
.startObject("content") //content:{
.field("type","text")
.field("store",true)
.field("index",true)
.field("analyzer","ik_smart")
.endObject()
.endObject()
.endObject()
.endObject();
//4使用client向es服务器发送mapping信息,参数1:设置指定的索引,参数2:设置我们需要映射的tpye,参数三:把我们的json数据传入
client.admin().indices().preparePutMapping("hello").setType("article").setSource(builder).get();
最后也是用client.admin().indices来创建mapping,需要设置索引库,索引库的type。
【5】添加document,也就是域中对应的内容
大家可以发现,原生的es在idea中,都离不开三部,
就是1.setting,2.transportClient获取client,3.client.addTransportAddress设置主机和端口号
所以我们大可把这三部,提出去,用@Before标注,这样就会在其他方法执行前把我们需要的client加载好。
依旧是使用xContentBuilder来写我们的json数据,区别就是最后发送请求的时候,只用prepareIndex(canshu1,canshu2,canshu3),参数分别是索引库,type,和documentID。
@Test
public void addDocument() throws Exception{
Settings settings=Settings.builder().put("cluster.name","my-elasticsearch").build();
TransportClient client=new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9303));
XContentBuilder builder=XContentFactory.jsonBuilder()
.startObject()
.field("id",1)
.field("title","这是用java编写的es索引")
.field("content","即麻烦又不好用")
.endObject();
client.prepareIndex("hello","article","1").setSource(builder).get();//这里的id是_id,就是文档的id
client.close();
}
【6】当然我们既然用了idea,就不需要这么麻烦的去弄document的json格式,有的是方法可以帮我们的数据转成json,之前在做网页的时候,从后端传过来的数据,不就是需要转成json格式的嘛。多了两个jar包而已,总比自己写这么多语句好。
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.6.7</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.0</version>
</dependency>
有了json的jar包,我就创建一个pojo类不就好了,这个类里写上和field对应的参数。
在我们存document的时候就可以直接设置这个pojo类的参数,然后利用ObjectMapper把类转成json字符串。
@Test
public void addArticleDocument2() throws Exception{
Article article=new Article();
article.setId(2l);
article.setTitle("这是用json转换器把java-->json");
article.setContent("比用Xcontent拼接简单");
ObjectMapper mapper=new ObjectMapper();
String s = mapper.writeValueAsString(article);
//下面的部分可以拿出去,都是重复内容
Settings settings=Settings.builder().put("cluster.name","my-elasticsearch").build();
TransportClient client=new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9303));
client.prepareIndex("hello","article","2").setSource(s, XContentType.JSON).get();
client.close();
}
【7】搜索数据
1 把重复的代码拿出来
@Before
public void init() throws Exception{
Settings settings=Settings.builder().put("cluster.name","my-elasticsearch").build();
client=new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9303));
}
2.因为查询数据只有一个QueryBuilder的查询信息的差异,其他的都一样,所以我们把一样的代码也封装成一个方法,到时候直接调用即可
private void search(QueryBuilder queryBuilder) throws Exception{
//执行查询,第一个参数设置查询的索引,第二个设置type
SearchResponse searchResponse = client.prepareSearch("hello").setTypes("article").setQuery(queryBuilder).get();
//取查询结果,获取结果集
SearchHits hits = searchResponse.getHits();
//取查询结果的总记录数
long totalHits = hits.getTotalHits();
System.out.println("总共查询到"+totalHits+"条数据");
//查询结果列表
for (SearchHit hit : hits) {
//打印文档对象,以json的格式输出
System.out.println(hit.getSourceAsString());
//用map键值对拿出属性数据
Map<String, Object> source = hit.getSource();
System.out.println("id为:"+source.get("id")+","+"\n"+"title为:"+source.get("title")+","+"\n"+"content为:"+source.get("content"));
System.out.println("--------------------");
}
//关闭client
client.close();
QueryBuiler一共可以创建出3中查询对象,根据term查询,根据queryString查询,根据id查询
@Test
public void searchById() throws Exception{
//ducumentID可以同时定义多个
QueryBuilder queryBuilder= QueryBuilders.idsQuery().addIds("1","2");
search(queryBuilder);
}
@Test
public void searchByTerm() throws Exception{
//参数1为搜索的域,参数2为搜索的关键词
QueryBuilder queryBuilder=QueryBuilders.termQuery("title","转换器");
search(queryBuilder);
}
@Test
public void searchByQuerySrting() throws Exception{
//defaultFiled不写也行
QueryBuilder queryBuilder=QueryBuilders.queryStringQuery("转换器").defaultField("title");
search(queryBuilder);
}
【8】分页查询,我们一般默认情况下,只会搜索出10条数据,也就是如果我们搜索到了100条数据,也只会显示10条
所以需要进行分页,来设定我们每页显示几条数据,这个需要在我们的searchResponse中设置,因为这个使获取返回的数据的。
只要加上setFrom()从第几页查询,setSize(),每页查询几条数据。其他的都不变
SearchResponse searchResponse = client.prepareSearch("hello").setTypes("article").setQuery(queryBuilder)
//设置分页信息
.setFrom(0)
.setSize(5)
.get();
【9】高亮查询
就是把我们搜索的关键字标注出来,并且显示结果,下面标红字的就是高亮显示。
我们需要做的就是1.创建一个HighlightBuilder对象,然后这个对象设置高亮显示的域。
preTag就是在高亮关键字的前面添加tag标签,postTag自然就是在后面。
依然是在searchResponse返回的数据上设置高亮。
结果集hits里也有提供获取高亮信息的方法:getHighlightFields
得到的是一个map集合,其中String代表的是咱们的域,HighlightField类是我们域中高亮的document数据。
private void search(QueryBuilder queryBuilder,String highLightField) throws Exception{
//创建一个HighLightBuilder,设置高亮显示
HighlightBuilder highlightBuilder=new HighlightBuilder();
highlightBuilder.field(highLightField).preTags("<em>").postTags("<em>");
//执行查询,第一个参数设置查询的索引,第二个设置type
SearchResponse searchResponse = client.prepareSearch("hello").setTypes("article").setQuery(queryBuilder)
//设置分页信息以及高亮显示
.setFrom(0)
.setSize(5)
.highlighter(highlightBuilder)
.get();
//取查询结果,获取结果集
SearchHits hits = searchResponse.getHits();
//取查询结果的总记录数
long totalHits = hits.getTotalHits();
System.out.println("总共查询到"+totalHits+"条数据");
//查询结果列表
System.out.println("-----高亮显示结果");
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
System.out.println(highlightFields);
HighlightField field = highlightFields.get(highLightField);
Text[] fragments = field.getFragments();
if (fragments!=null){
System.out.println(fragments[0].toString());
}
System.out.println("--------------------");
}
//关闭client
client.close();
最后我们来看一下,高亮的数据和我们普通的数据获取有什么区别,高亮只会拿到我们设置的域中的符合条件的数据。并且把关键字用我们指定的标签包起来了;
@Test
public void searchByTerm() throws Exception{
//参数1为搜索字段,参数2为搜索的关键词
QueryBuilder queryBuilder=QueryBuilders.termQuery("title","转换器");
search(queryBuilder,"title");
}
{"id":18,"title":"这是用json转换器把java-->json18","content":"比用Xcontent拼接简单18"}
id为:18,
title为:这是用json转换器把java-->json18,
content为:比用Xcontent拼接简单18
-----高亮显示结果
{title=[title], fragments[[这是用json<em>转换器<em>把java-->json18]]}
这是用json<em>转换器<em>把java-->json18
--------------------
{"id":77,"title":"这是用json转换器把java-->json77","content":"比用Xcontent拼接简单77"}
id为:77,
title为:这是用json转换器把java-->json77,
content为:比用Xcontent拼接简单77
-----高亮显示结果
{title=[title], fragments[[这是用json<em>转换器<em>把java-->json77]]}
这是用json<em>转换器<em>把java-->json77


















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











