




 本文详细介绍了如何使用Eclipse和Tomcat发布Web应用的全过程,包括配置环境、安装工具、发布步骤等关键环节,旨在帮助开发者高效地部署Web应用。
本文详细介绍了如何使用Eclipse和Tomcat发布Web应用的全过程,包括配置环境、安装工具、发布步骤等关键环节,旨在帮助开发者高效地部署Web应用。
首先让我们看看准备工具:
jdk: jdk-1_5_0_05-windows-i586-p.exe
eclipse:eclipse-SDK-3.1.2-win32.zip
tomcat:jakarta-tomcat-5.0.28.exe
tomcat插件:tomcatPluginV31.zip
当所有这一切都准备好之后,让我们一项一项来安装配置
一 jdk的安装
jdk的安装只需要根据提示安装就可以了。中途你可以选择自己喜欢的安装路径。安装之后,会有一个jdk1.5.0_05和一个jre1.5.0_05文件夹。
然后开始设置环境变量。右键我的电脑--属性--高级--环境变量。在这里你可以选在在系统变量中添加,这样这台机器上的所有用户都可以使用这个环境变量。
添加CLASSPATH: .;D:\Program Files\Java\jdk1.5.0_05\lib\tools.jar;D:\Program Files\Java\jdk1.5.0_05\lib\dt.jar 注意,在最前面有一个“.”,不要忘记了。这里面的路径要换成你自己的安装路径。
添加JAVA_HOME: D:\Program Files\Java\jdk1.5.0_05 同样换成你自己的路径
二 tomcat的安装
按照安装提示进行安装就可以了。 中途可以选择端口。默认是8080。你可以改成80,这样在以后输入地址的时候比较方便。但是80端口比较容易发生冲突。所以这里就不用改了。(安装之后在配置文件中也可以重新设置端口号,请查阅相关资料)
在环境变量中添加 CATALINA_HOME: D:\Program Files\Tomcat 5.0
TOMCAT_HOME:D:\Program Files\Tomcat 5.0
TOMCAT_BASE:D:\Program Files\Tomcat 5.0
这里说明一下。我在网上搜了很多文章,对这里的环境变量设定不一。没有查到这三个环境变量具体有什么不同,可能是不同版本之间的差别?所以三个我全都写上了
在CLASSPATH中添加:D:\Program Files\Tomcat 5.0\common\lib\servlet-api.jar
在所有这一切做完之后,打开你的浏览器,输入 http://localhost:8080 看看会有什么事情发生。
三 eclipse的安装
将eclipse解压缩到目的文件夹。我的是D:\Program Files\eclipse。然后可以启动eclipse.exe。
关于eclipse的使用可以参看一些其他文章。
四 tomcat插件的安装
关闭eclipse。将tomcatPluginV31.zip解压缩,将解压缩的到的文件夹com.sysdeo.eclipse.tomcat_3.1.0拷贝到D:\Program Files\eclipse\plugins里面。
重新打开eclipse。然后在window--prefereces中的左侧找到java--Installed JREs,选中jdk1.5.0_05
然后在左侧找到tomcat,选择5.x版本 在tomcat根目录中,输入TOMCAT_HOME中的地址:D:\Program Files\Tomcat 5.0
在tomcat-advanced中,在tomcat base路径 一栏中,同样输入D:\Program Files\Tomcat 5.0
现在,按下确定,大功告成。
环境:windows 7+Eclipse Java EE IDE for Web Developers+tomcat 7.02
一.配置Tomcat插件
我们创建一个myplugins文件夹用于存放插件,myplugins位于D:\Program Files\J2EE目录下。eclipse安装路径为:D:\Program Files\J2EE\eclipse-JavaEE。tomcat的安装路径为:D:\Program Files\J2EE\apache-tomcat-7.0.2。因此myplugins、eclipse-JavaEE和tomcat位于同一个目录下,当然这并不是必须的。只是方便管理。
再创建用户存放tomcat插件的目录:D:\Program Files\J2EE\myplugins\tomcatPluginV321\eclipse\plugins,然后将tomcatPluginV321.zip中的com.sysdeo.eclipse.tomcat_3.2.1解压缩到D:\Program Files\J2EE\myplugins\tomcatPluginV321\eclipse\plugins目录下。这里eclipse\plugins是必须的。
我们在eclipse-JavaEE下再创建一个links文件夹,然后在links文件夹下创建一个tomcat.link文件。可以通过先创建一个文本文件,然后另存为tomcat.link。使用记事本打开tomcat.link,输入:path=D:\\Program Files\\J2EE\\myplugins\\tomcatPluginV321 。
这时候tomcat的外部配置就完成了,接下来打开Eclipse,这时候我们就会发现Eclipse中有了tomcat的小图标。
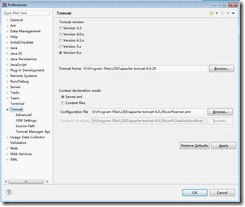
然后再Eclipse中的【window】->【preferences】,打开如下图所示的界面
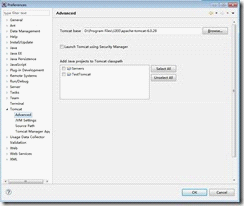
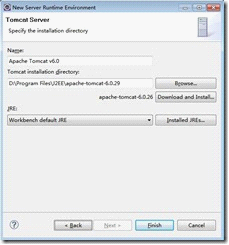
在Tomcat的Advanced标签中输入Tomcat Base的地址,也就是Tomcat的安装地址
这时候我们通过Eclipse菜单栏中的Tomcat小图标就能启动Tomcat了。
二.配置Eclipse的server
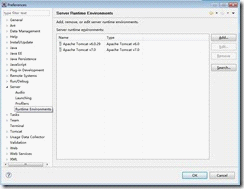
和配置Tomcat一样,同样是在Eclipse中的【window】->【preferences】下进行配置,如下图所示:
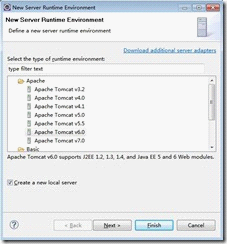
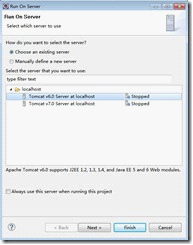
只有配置Tomcat的server我们才能通过Tomcat进行发布网站。前面配置的Tomcat插件只是让我们能够在Eclipse配快速启动Tomcat而已,发布网站是在这一步配置的。如上图所示,我们这里配置了两个Tomcat server,分别是tomca 6.0和Tomcat 7.0,这个我们可以根据需要来决定使用哪一个server。这个配置server其实也很简单,只需要add一下就可以了。如下图所示:
配置好server以后,我们将在后面用到他们。
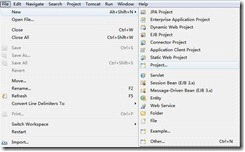
三.创建web应用
接下来我们再创建一个web project,如下图所示
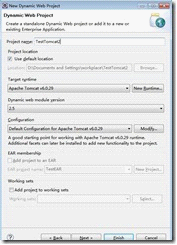
这样就创建了一个动态的web应用程序。从上面我们可以看到有一个Target Runtime的选择,这个选项就是我们前面创建的server,这里我们选择Tomcat 6.0,选择了Target Runtime后Eclipse会自动帮我们选择Dynamic web module version和configuration这两个选项,我们默认就可以,点击finish完成项目的创建。在创建的TestTomcat2这个项目的WebContent目录下创建一个index.jsp文件。如下图所示:
四.发布web应用
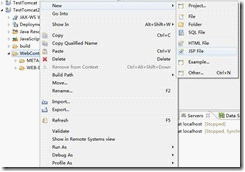
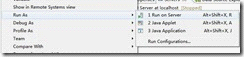
右键项目TestTomcat2,选择【run as】->【run on server】,如下图所示:
点击finish完成发布工作,发布后在Eclipse中会自动打开发布的项目,如下图所示:
上面就是通过Eclipse和Tomcat发布web应用的全过程。

















 4886
4886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}