




 本文详细介绍了Spark的四种运行模式,重点讲解了standalone集群的搭建过程,包括配置修改、集群部署及测试验证,适用于初学者快速上手Spark集群环境。
本文详细介绍了Spark的四种运行模式,重点讲解了standalone集群的搭建过程,包括配置修改、集群部署及测试验证,适用于初学者快速上手Spark集群环境。
文章目录
Spark的四种运行模式
首先spark有四种运行模式,目前只接触到了local,standalone ,yarn 三种运行模式。
local模式顾名思义就是运行在 本地,一般用于测试小型的spark应用程序,比较简单,只用在开发工具中安装插件即可,不需要搭建集群。
standalone 和 yarn 属于同级别的,都需要搭建集群,yarn集群在前面的博客已经介绍,这里不做详细介绍,下面是我们standalone 集群的搭建过程。
- local
- standalone
- yarn
- mesos
standalone 集群的搭建
standalone集群的大体框架
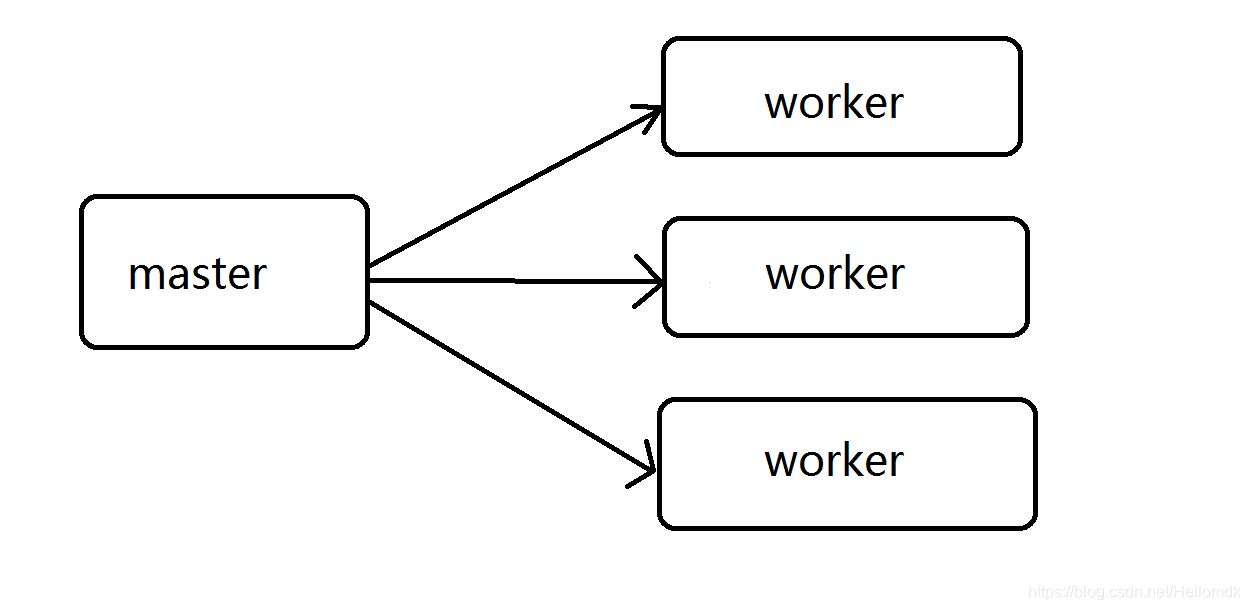
standalone集群步骤
1,在node01节点上下载spark安装包
2,解压spark-1.6.3-bin-hadoop2.6.tgz安装包
tar -zxvf spark-1.6.3-bin-hadoop2.6.tgz
3,修改spark配置文件
- 进入conf目录下修改配置文件的名字
把slaves.template文件改名为slaves文件mv slaves.template slaves - 修改slaves配置文件内容
standalone是主从架构,而slaves配置文件里面放的是从节点的IP,所以将node02,node03,node04放入slaves中。

- 修改spark-env.sh内容
SPARK_MASTER_PORT字段设置主节点的IP
SPARK_MASTER_IP字段设置端口(用来Master与Worker的心跳,资源通信)
SPARK_WORKER_CORES代表每一个worker进程能管理几个核(有几个核的支配权)。
//如果CPU是4核8线程,那么这个核是支持超线程的核。
//如果是普通的核,一个核在一个时刻只能处理一个线程。
//这个配置是根据当前节点的资源情况来配置的,如果节点有8个core,并且支持超线程,此时可以将这个节点看成由16个core组成。
SPARK_WORKER_MEMORY字段代表每个worker可以管理多大内存。
SPARK_WORKER_DIR配置worker路径
SPARK_WORKER_INSTANCES设置每个节点上启动的worker进程数。
4,将配置好的spark安装包发送到各个节点上
scp -r spark-1.6.3 root@node2: ‘pwd’
scp -r spark-1.6.3 root@node3:‘pwd’
scp -r spark-1.6.3 root@node4:‘pwd’
5,将启动命令改名
进入sbin目录下,找到start-all.sh文件(此文件与hadoop的start.sh冲突),将其改为:start-spark.sh
mv start-all.sh start-spark.sh
6,启动spark
start-spark.sh
7,jps查看各个节点开启的进程
node01上启动了一个Master进程
node02上启动了一个Worker进程
node03上启动了一个Worker进程
node04上启动了一个Worker进程
8,浏览器查看
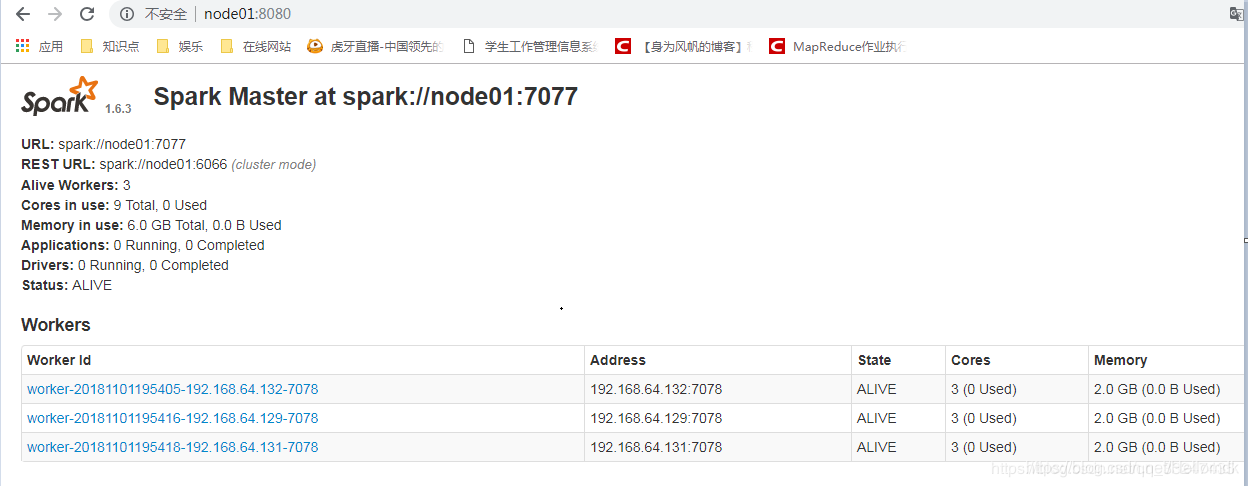
通过访问8080端口,可以监控worker进程的启动情况,如图所示启动的 worker和配置文件配置相同,说明启动成功。
9、提交测试
提交一个spark Application应用到集群中运行。
spark-submit --master spark://node01:7077 --class org.apache.spark.examples.SparkPi /opt/software/spark/spark-1.6.3/lib/spark-examples-1.6.3-hadoop2.6.0.jar 10

如图所示,计算出π的大致结果。
补充:π值计算,实际上是打点法,如上面的命令,传入的参数是n,那么它会划分出两块区域,一块n*n的正方形,在这个正方形中画出一块内切圆,然后随机打点,落入圆内的概率乘以面积就是大致的计算结果。

















 5504
5504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









