




三种分布式介绍
1,伪分布式
在一台服务器上,启动多个进程,分别表示各个角色
2,完全分布式
在多台服务器上,每台服务器启动不同角色的进程,使用多台服务器组成HDFS集群
node01:namenode
node02:secondarynamenode datanode
node03:datanode
node04:datanoode
3,高可用性的完全分布式
node01:namenode
node02:secondarynamenode datanode
node03:datanode namenode
node04:datanode
伪分布式的搭建
免密登录
node01->node01
ssh-keygen -t rsa //生成公钥
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node01 //将公钥添加到node01
配置JDK(和window相似)
①rz安装命令(上传文件)
yum -y install lrzsz
rz //上传文件
②解压缩,找合适的文件位置存放
tar -zxvf jdk-8u151-linux-x64.tar.gz /usr/local
③配置环境变量
#接着需要配置JAVA环境变量.
vim ~/.bashrc
# 在文件最后添加
export JAVA_HOME=/usr/local/jdk-9.0.1-1
export PATH=$JAVA_HOME/bin:$PATH
# 接下来需要使用source命令是环境变量生效.
source ~/.bashrc
④检验jdk是否安装成功
java -version
安装hadoop
sudo tar -zxvf hadoop-2.8.2.tar.gz -C /usr/local
# 将hadoop解压到/usr/local
sudo mv hadoop-2.8.2 hadoop
# 将文件夹重命名为hadoop(可选,方便后续添加环境变量)
hadoop相关文件配置
①配置环境变量
vim ~/.bashrc
# 在文件最后添加:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# 保存推出 :wq
# 使用source命令,是环境变量生效.
source ~/.bashrc
②修改hdfs-site.xml配置文件
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
③修改core-site.xml配置文件
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/abc/hadoop/local</value>
</property>
④修改slaves配置文件
node01
格式化NameNode
hdfs namenode -format
启动HDFS
start-dfs.sh
操作HDFS文件系统
①创建目录
hdfs dfs -mkdir -p /user/root
②上传文件
hdfs dfs -D dfs.blocksize=1048576 -put /home/node02/hello.txt /user
安装过程中遇到的问题
①java异常,找不到指定的address
解决:更改hadoop安装包中的配置文件hadoop-env.sh

把图中的JAVA_HOME=${JAVA_HOME}更改成jdk安装的绝对路径
②java异常 ,找不到node01节点
解决:更改配置文件hosts
vi /etc/hosts
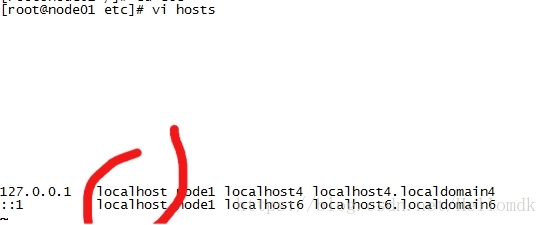
把第一个localhost改成node01

















 4097
4097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









