




1,什么是大数据
简单的说:就是短时间内快速的、产生海量的、多种多样的、有价值的数据。
2,大数据技术:
分布式存储
分布式计算
1,分布式批处理
攒一段时间的数据,然后在未来的某一个时间来处理这些数据
2,分布式流处理
数据不需要攒,直接处理每产生一条数据,立马对数据作出处理,将数据推送到前台界面和存储到数据库中形成报表发个老板。
例如:天猫大屏幕 QQ实时在线分布情况。
机器学习
主要做预算类的… ,比如天气预报,车流量统计(明天阻不阻塞)
3,什么是分布式存储
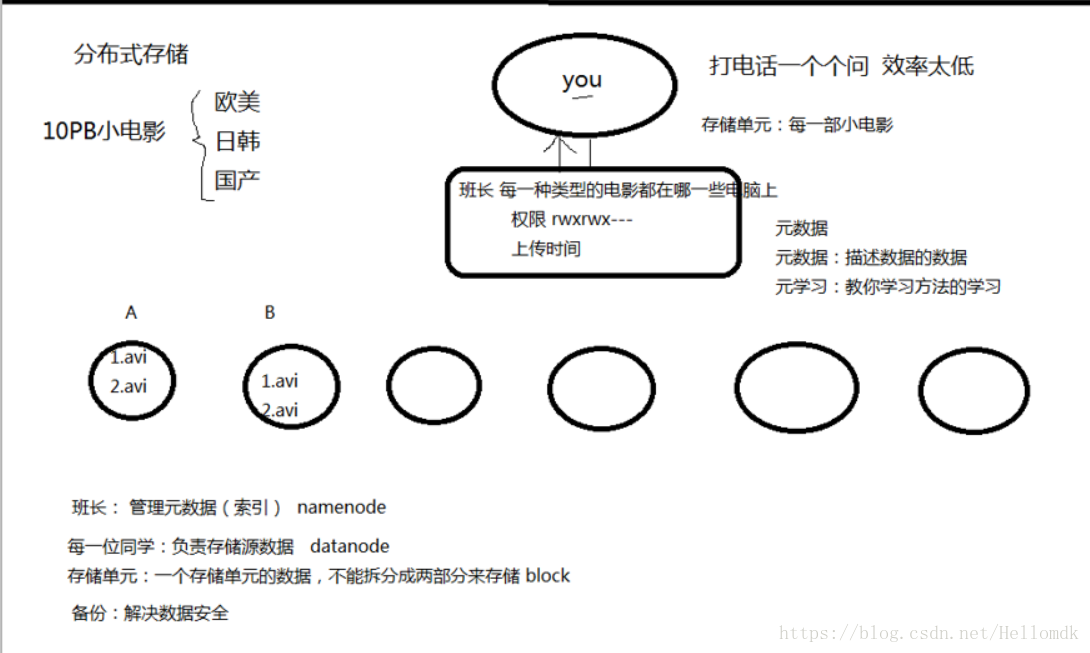
如图:一个小例子
给你10PB的小电影(欧美、日韩、国产),但是你的电脑磁盘存不下,那么怎么解决呢,我们最想想到的是找几个室友一块存储,假如说存储存上了,某一天你想看某个电影,你想看某个视频,怎么查找呢,你总不能一个个大给室友打电话问吧,那么怎么解决呢。
这个时候我们可以找个代理,来存储各个电脑上存储的类别,也就是存储一个索引,当你想看某个类别时就直接告诉你资源在那台机器上,你再去拿就可以以了。当然有一些宝贵资源,室友不想分享给你,那么就又引出了权限的概念。
这个例子就是分布式存储的思想
代理:管理元数据(索引) namenode
存储的电脑:负责存储源数据 datenode
存储单元:默认是128M,一个存储单元的数据不能分成两部分来存储 block
备份:解决数据安全问题
4,分布式存取过程

1,如果要上传一个大文件,计算大文件的block数量 大文件地址/128M=block数量
2,client回向namenode汇报
①当前大文件的block数量
②当前大文件属于谁 权限
③上传时间
for(Block block : blocks(大数据切割出来的Block)){
3,client切割出来一个block
4,请求block块的Id号以及地址
5,因为namenode能够掌控全局,管理所有的DN,所以他会将负载不高的DN地址返回给client
6,client拿到地址后,找到DN上传数据
7,DN贾昂block存储完毕后,会向NN汇报当前的存储情况
}
Namenode的作用
1,掌控全局,管理DN以及元数据
2,元数据存在内存中
3,接受客户端的读写服务
4,收集DateNode汇报的block列表信息
5,NameNode保存metadata信息模块包括
支持owership 和permissions
文件大小,时间
(block列表:BlockID)
Block副本位置(由DateNode上报)
6,接收client的读请求,返回地址
DataNode的作用:
1,存储block块,向NN汇报,发送心跳(告诉它自己还没死掉),
2,接收client的读请求
5,备份机制
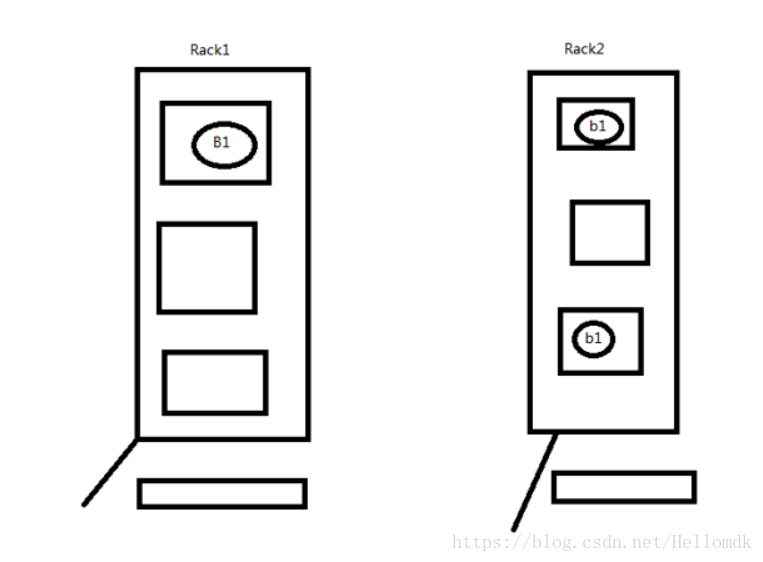
备份机制:
1,第一个block存储在负载不是很高的一台服务器上
2,第1个备份的block存储在与第一个block不同的机架随机的一台服务器上
3,第2个备份存储在与第一个备份相同机架上的一台服务器上
问题:
为什么第1个备份要和第2,3个备份存储到不同的机架上?
原因就是:防止第1个机架突然断电情况,此时可以到别的机架上获取数据的备份
6,client向DN写数据的详细流程
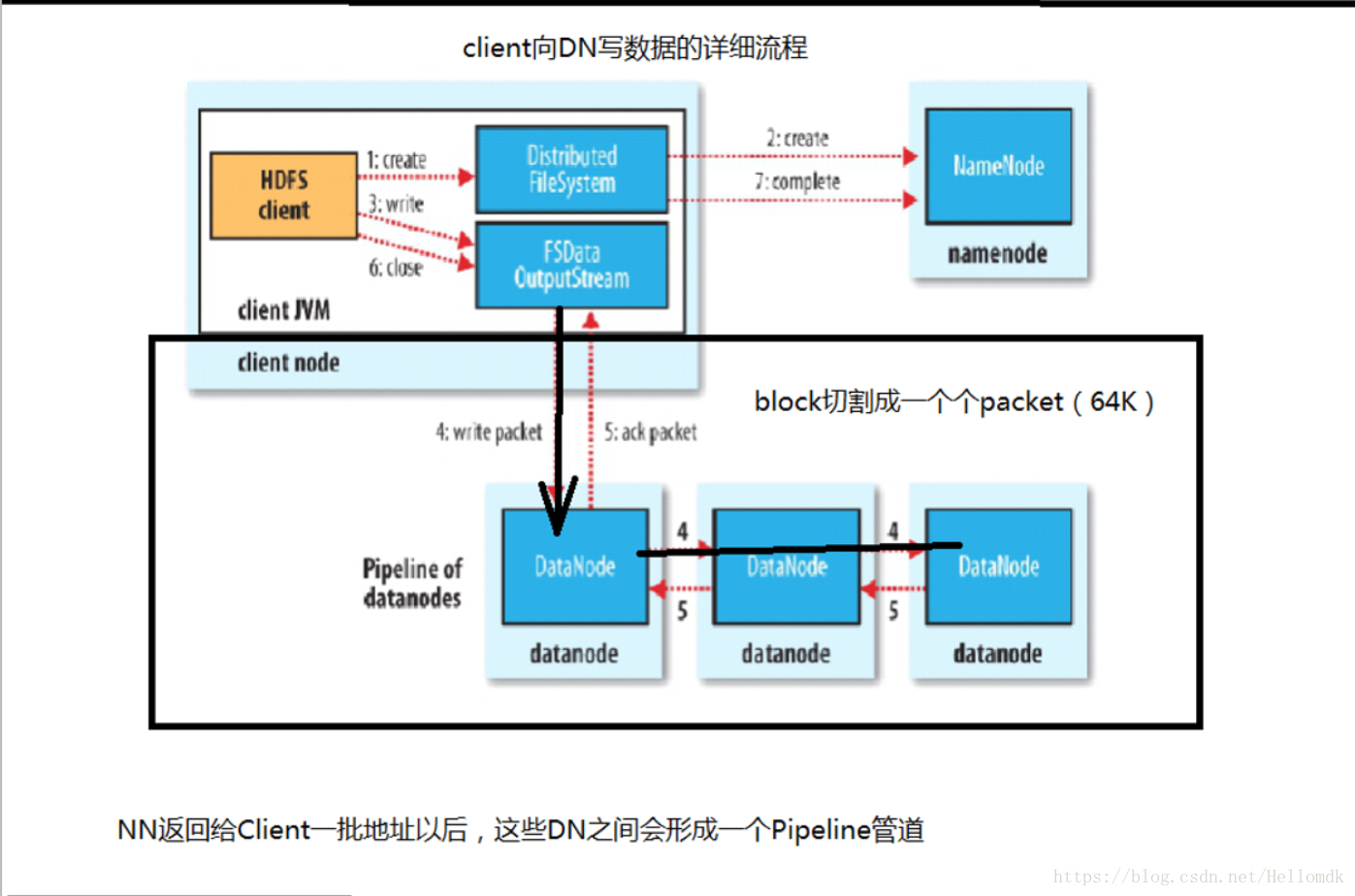
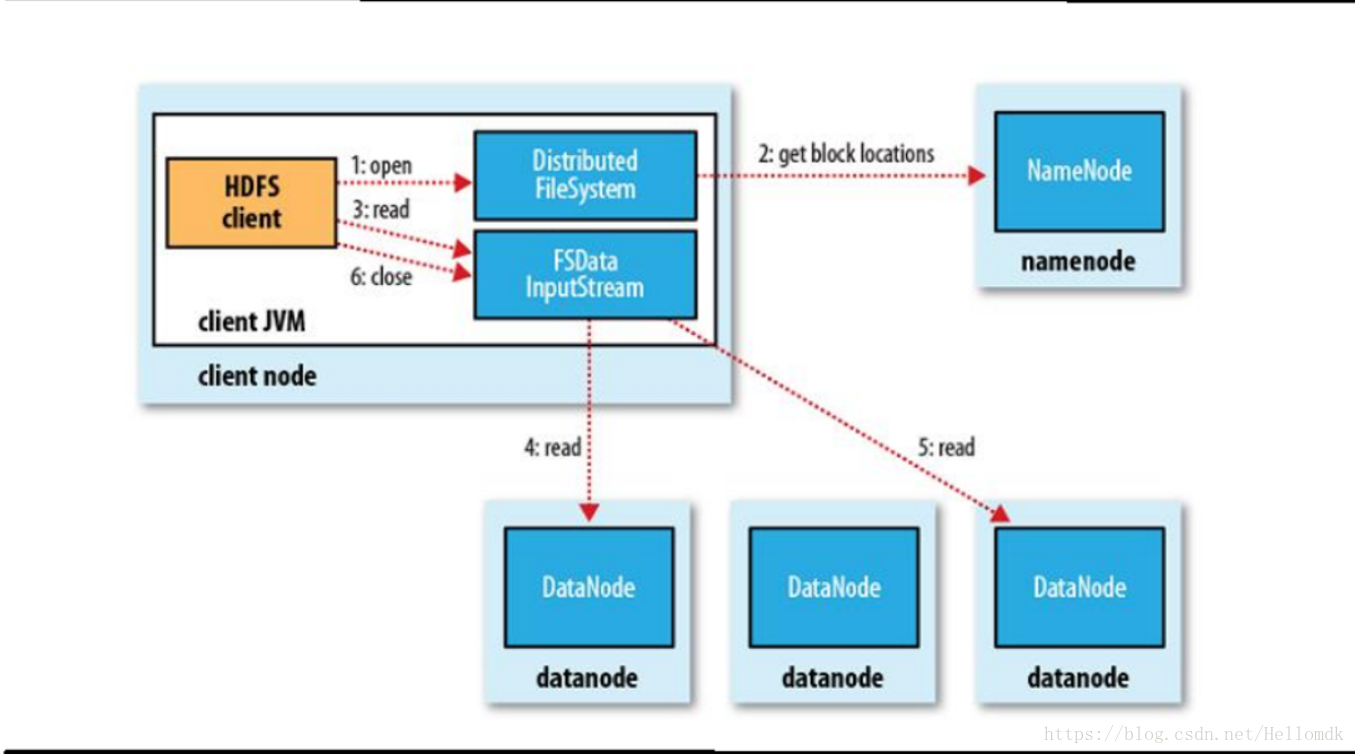
7,持久化

为什么要持久化呢?
nameNode元数据如果存储到内存中,内存是不稳定的,那么遇到断电等异常情况,再次启动时,元数据就丢失了,所以我们要持久化到硬盘中存储。
持久化存储,要存储哪些信息呢?
①文件拥有者
②权限
③文件大小
④上传时间
⑤Block列表:BlockID
⑥Block以及副本的存储位置
注意:角色在集群中都是用进程来表现的
为什么说node01服务器为NameNode节点呢?
因为在node01节点上启动了一个NameNode进程
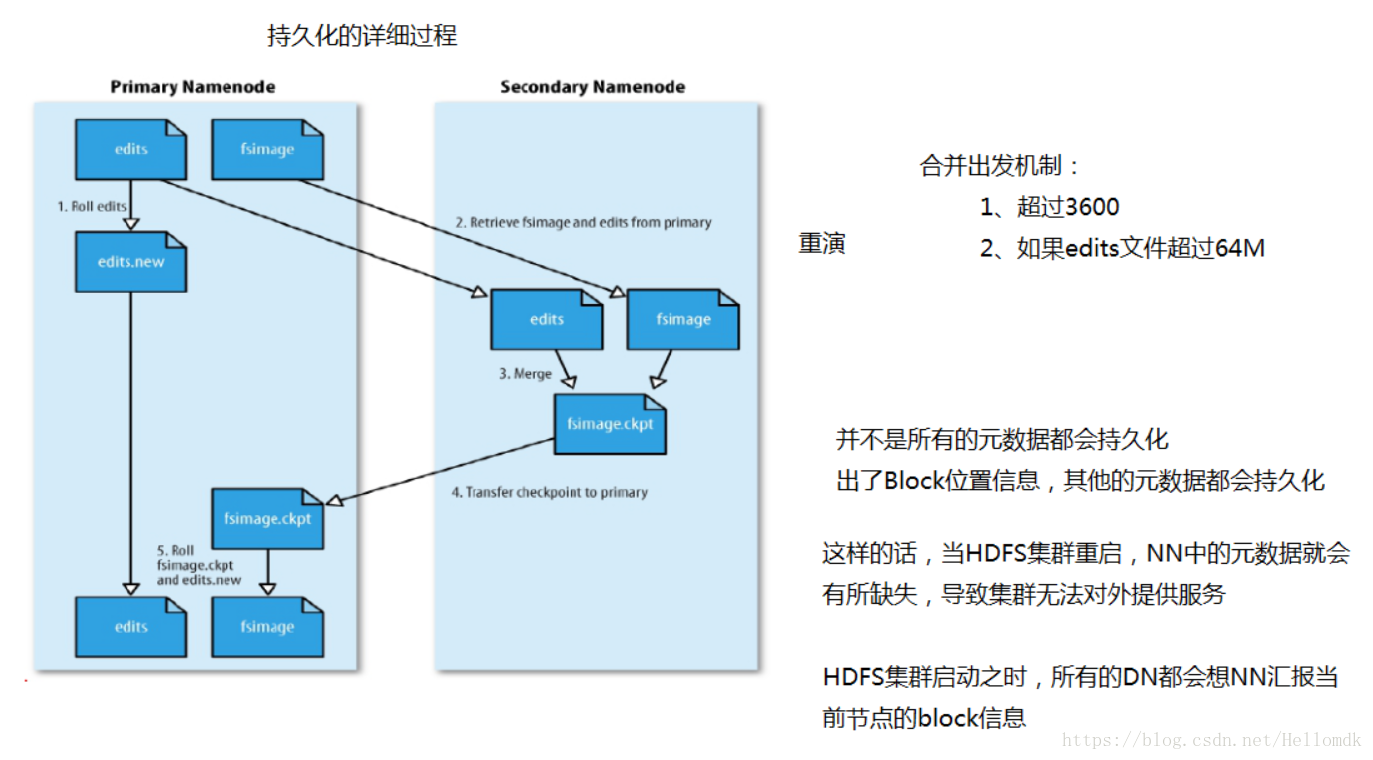
持久化的详细过程中
产生两个文件:edits和fsimage两个文件
edits:用于存储对元数据的操作
fsimage:用于存储元数据
Secondary NameNode的产生
首先,不要错误的以为Secondary NameNode是NameNode的一个备份,可以理解为是助理。
我们都知道,只有在NameNode重启时,edit logs才会合并到fsimage文件中,从而得到一个文件系统的最新快照。但是在产品集群中NameNode是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
①edit logs文件会变的很大,怎么去管理这个文件是一个挑战。
②NameNode的重启会花费很长时间,因为在edit logs中有很多改动要合并到fsimage文件上。
③如果NameNode挂掉了,那我们就丢失了很多改动因为此时的fsimage文件非常旧。
因此为了解决以上问题,我们产生了Secondary NameNode来解决这些问题。
它的职责是合并NameNode的edit logs到fsimage文件中。
Secondary NameNode的工作流程
1,首先,它定时到NameNode去获取edit logs,并更新到fsimage上,
2,一旦它有了新的fsimage文件,它将其拷贝回NameNode中。
3,NameNode在下次重启时会使用这个新的fsimage文件,从而减少重启的时间。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









