




python复习
python的应用场景:获取抽取源数据(包括文件内容、数据库数据、接口数据);进行数据的转换和清洗(包括json数据、正则表达式、时间格式等等);进行数据的存储(将数据存入各种文件、写入数据到数据库);使用Python分析ETL的过程和数据计算的过程中日志的步骤数据(例如可以使用python分析kettle最后日志的结果,查看每个步骤的平均时间,找出时间消耗最多的步骤等、也可以分析hive数据库运行过程中yarn log错误信息等)
大纲
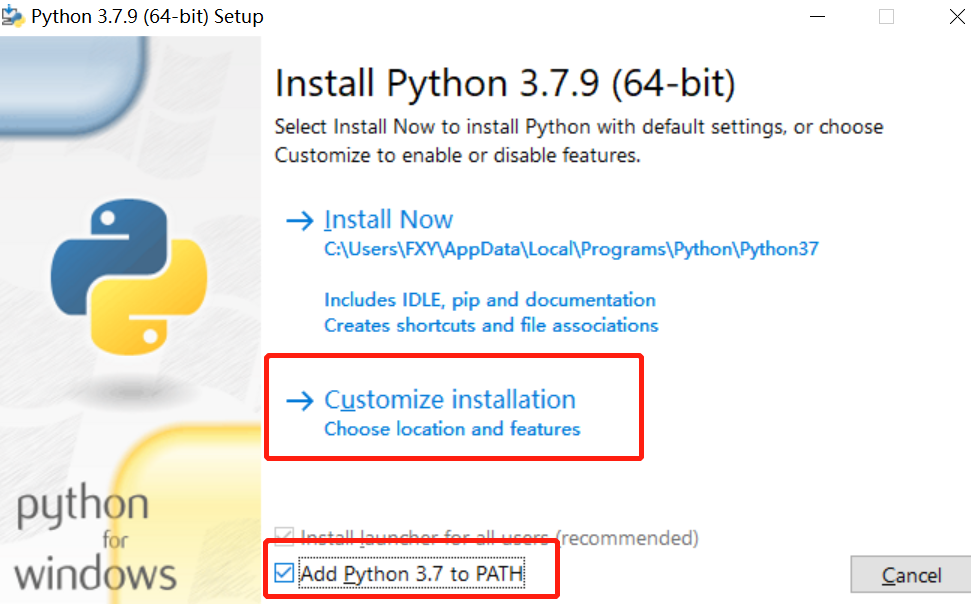
PYTHON 3.7.9(64-BIT) SETUP
INSTALL PYTHON 3.7.9 (64-BIT)
SELECT INSTALL NOW TO INSTALL PYTHON WITH DEFAULT SETTINGS,OR CHOOSE
CUSTOMIZE TO ENABLE OR DISABLE FEATURES.
INSTALL NOW
C:\USERS\FXY\APPDATA\LOCAL\PROGRAMS\PYTHON\PYTHON37
INCLUDES IDLE, PIP AND DOCUMENTATION
CREATES SHORTCUTS AND FILE ASSOCIATIONS
CUSTOMIZE INSTALLATION
个
CHOOSE LOCATION AND FEATURES
PYTHON
FOR
(RECOMMENDED)
WINDOWS
ADD PYTHON 3.7 TO PATH
CANCEL
PYTHON 3.7.9(64-BIT) SETUP
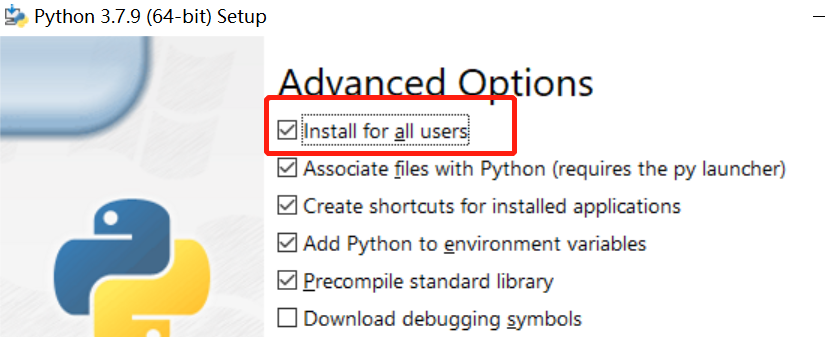
ADVANCED OPTIONS
LNSTALL FOR
R ALL USERS
ASSOCIATE FILES WITH PYTHON (REQUIRES THE
S THE PY LAUNCHER)
CREATE SHORTCUTS FOR INSTALLED APP
APPLICATIONS
ADD PYTHON TO ENVIRONMENT VARIABLES
PRECOMPILE STANDARD LIBRARY
DOWNLOAD DEBUGGING SYMBOLS
需要有一个编辑python的窗口:
官方自带了一个编辑窗口 IDLE
第三方的工具 eclipse vscode pycharm
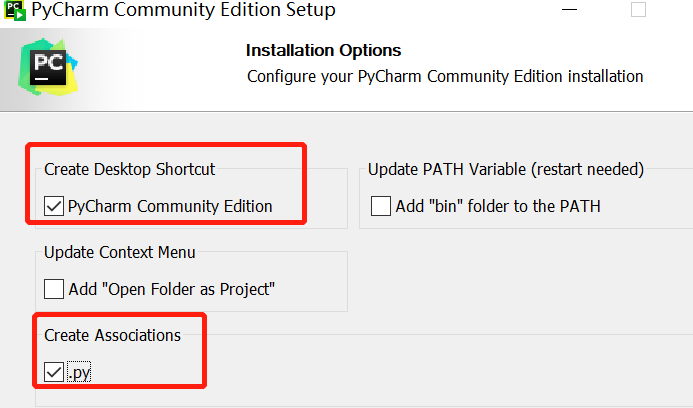
PYCHARM COMMUNITY EDITION SETUP
INSTALLATION OPTIONS
CONFIGURE YOUR PYCHARM COMMUNITY EDITION INSTALLATION
CREATE DESKTOP SHORTCUT
UPDATE PATH VARIABLE(RESTART NEEDED)
PYCHARM COMMUNITY EDITION
ADD"BIN"FOLDER TO THE PATH
UPDATE CONTEXT MENU
ADD"OPEN FOLDER AS PROJECT"
CREATE ASSOCIATIONS
PC
PYCHARM
COMMUNITY
EDITION
2022.3.2
1创建一个project项目
2在项目的文件夹中,创建一个Python文件
3在文件里面编辑Python的脚本
4第一行一般都会指定当前脚本的编码格式
#coding=utf-8
变量
Plain Text复制代码
1
2
a=10
b='hello'
变量名=值
变量名是由 英文、下划线、数字组成,数字不能开头,不要使用系统关键字。
输入输出
输出
print()方法
print(要打印输出的内容)
print(内容1, 内容2, 内容3, ...)
Plain Text复制代码
1
2
3
4
5
6
a=10
b='hello'
c=19.666
print(a)
print(a,b,c)
end在打印的括号里面,默认是换行回车,如果自己写end='',那么就是说要用某个内容去替换默认的换行回车,那么换行的效果就消失了,变成了用某个符号来连接输出打印
print(内容1) 默认end='\n'
print(内容2)
那么输出就应该是
内容1
内容2
print(内容1, end='--') 就是用 -- 替换了 \n
print(内容2)
那么输出就应该是
内容1--内容2
输入
input()方法
变量名=input(提示语句) 将用户输入的数据赋值给变量进行保存
input()方法,接收的所有的数据都是字符串,就算输入一个10,也是字符串。
如果要输入整数的10,那么要写成 int(input()),如果要输入小数的10,那么要写成 float(input())
数据类型和操作方法
普通类型
1数字类型
1.1 int整数
a=10
1.2 float小数
a=1.66
2bool类型
只有真和假的类型,任何的数据都是有真假的。例如数字只有0是False,其他的任何数字都是True。例如其他的类型,空的都是False,只要有值,都是True。
a=True
a=False
3str字符串类型
python里面,单引号和双引号是没有区别的。
\ 是转义符,将其他的字符内容转义成特殊符号,从而失去原本的表达含义。
如果要让\失去转义的效果:
用转义符将 \ 转义成普通的符号,或者在字符串的前面加上 r
字符串操作的方法:
字符串函数,不是操作和修改字符串本身,只是操作字符串的过程而已,所以字符串原本的内容不会发生改变。
转换大小写:
str.upper()
str.lower()
str.title()
内容替换:
str.replace(旧内容, 新内容)
内容查找:
str.find(查找的数据)
切割字符串:
str.split(切割内容)
将列表或者元组连接成一个字符串:
str.join(列表或者元组)
判断开头和结尾的内容:
str.startswith()
str.endswith()
判断字符串的构成:
str.isalpha()
str.isdigit()
统计字符串某个内容的数量:
str.count()
统一字符串输出的格式:
str.format()
去除左右两边的空格:
str.strip()
有一个和oracle的translate类似的一个函数:
str.translate(str.maketrans('被替换的字符串', '一一对应的新的字符串'))
集合类型
有序集合
1list列表
列表常用的函数:
只有字符串的函数是不对原有数据进行修改和操作的,其他的所有类型包括了列表在内,函数都是直接操作和作用在原有数据上的。
添加数据:
list.append() 将数据添加到列表的最后面
list.insert() 将数据按照位置进行插入添加
删除数据:
list.remove() 按照内容删除匹配的第一个数据
list.pop() 按照位置和序号删除数据
list.clear() 清空列表的内容
排序列表:
list.sort() 升序排序列表内容
list.sort(reverse=True) 降序排序列表内容
统计列表的数据:
list.count()
对列表进行反向的查看:
list.reverse()
查询列表的元素:
list.index() 显示匹配内容的第一个所在的序号
2tuple元组 不可变类型
元组没有任何的操作方法和函数。
无序集合
1dict字典 键值对的元素类型,由关键字和值组成的,关键字不能重复,值可以重复。
字典中常用到的函数方法:
添加字典的新数据:
dict[新的关键字]=值
删除字典的数据:
dict.pop() 根据关键字删除数据
dict.clear()
查看字典的数据:
dict.keys() 查询所有的关键字
dict.values() 查询所有的值
dict.get() 通过关键字获取对应的值
2set集合 集合的内容是不会出现重复数据的
集合中常用的函数:
添加数据到集合中:
set.add()
删除集合中的数据:
set.discard()
set.pop()
set.clear()
集合中有几个相关的运算:
- 差集,第一个有第二个没有的数据
| 并集,第一个和第二个不重复的所有数据
& 交际,第一个和第二个共有的数据部分
^ 第一个和第二个都没有重复的数据部分,第一个独有的和第二个独有的数据
判断和循环
判断
if 条件判断:
执行语句
if 条件判断:
执行语句
elif 条件判断:
执行语句
if 条件判断:
执行语句
else:
执行语句
if 条件判断:
执行语句
elif 条件判断:
执行语句
else:
执行语句
循环
for 变量名 in 循环范围:
执行语句
while 条件判断:
执行语句
练习:
固定模块操作
不同类型的文件的读写
文本文档
.txt 普通的文本文件
.log 日志文件
.dat 数据文件
.json json数据的文件
...
1文件的读取
-- 将整个文件当成一个整体,将所有的数据放在一个字符串中进行展示:
-- 每次读取文件的一行内容
-- 一次读取整个文件的所有内容放入到一个列表里面,将每一行都当成列表的一个元素
-- 用一句话来实现读取的操作,简化文件读取的步骤
2文件写入
写入同样可以使用with as的语法:
文件的读取可以是其他的格式:
练习:读取这个文件,查询出4月到6月,apple的平均价格
如果还是上面这个文件,要查询出每一种水果的平均价格,可以怎么写?
CSV文件的读写
1csv文件的读取
用列表的方式来查看每一行的数据
用字典的方式来查看每一行的数据
同样也可以使用with as来实现:
2将数据写入到csv的文件中去
csv文件的写入,一次写入一行,写入的时候数据是元组或者是列表的格式
以字典的方式来写入数据
EXCEL文档的操作
excel操作的模块有好几种,例如 xlrd xlwt pandas ...
pandas模块不是python自带的,来自于第三方库的模块,所以需要手动安装这个模块:
在cmd命令行的窗口中输入 pip install pandas,因为这个库安装速度比较慢,所以我们一般会添加一个国内的镜像网站:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pandas
pandas需要支持旧版本的xlrd模块:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd==1.2.0
在pandas模块里面,Series指的是一行数据,DataFrame是一个表格。
将数据写入到excel文件中
把e1表读取出来写入到e2表:
接口数据的读取
https://www.tianqi.com/tianqi/mapdata_new.json
例如要将这个天气系统的接口数据,写入到excel文件进行保存。
接口的操作,一般会使用第三方库 requests 库进行数据操作。
pip install requests
网络访问返回的状态码:
200 访问成功
403 地址没有问题,但是没有权限做这个事情
404 访问的地址不存在
5xx 例如501 502 503这些都是服务器本身出了问题,例如服务器挂机了
如果访问出现了403的现象,那么需要在访问过程中将Python模拟成浏览器的访问。
这个时候,就要添加Http的header头部的信息。
1需要从微博上,获取某个关键字对应的当天前十条微博的数据
2将这些数据写入到一个excel表格中
3将excel表格,发送到邮箱中
1要先去了解微博传输数据的方式是什么
用谷歌浏览器,打开F12进入到控制台的页面,打开NETWORK的标签,去刷新当前这个页面,获取页面所有的接口地址,然后一个个查看。
首先我们可以看 Fetch/XHR,这里是json格式返回的数据;
如果上面没有这个数据,那么我们找 doc 这个标签,找有没有页面的数据。
找到了页面需要的数据之后,复制左侧的对应的链接地址:
https://s.weibo.com/weibo?q=%E6%B5%81%E6%B5%AA%E5%9C%B0%E7%90%832
在传输的过程中,需要添加cookie和user-agent两个信息
2对微博返回的html数据进行解析的操作,使用正则表达式
因为获取的数据格式比较杂乱,我们先使用最粗暴的方式,只保留中文和基本的标点符号,其他的数据全部都删除掉,使用ascii码的方法。
3将当前得到的excel,用邮件的方式发送出去
需要的模块有 openpyxl
pip install openpyxl
需要smtplib
操作思路:
-- 先尝试对某个关键字的页面进行数据的捕获,发现微博页面,无法直接获取数据,所以我们添加了浏览器信息 user-agent 和用户访问信息 cookie
-- 使用正则表达式,通过左右边界的方式,在微博返回的html数据中进行内容的查询和获取
-- 因为页面的页面非常的多,有很多的干扰内容,所以通过ascll码,对英文、数字、特殊符号进行删除
-- 将每一个获取的数据,放入到一个列表中,当成DataFrame的对象进行存储,方便通过pandas模块进行excel文件的写入
-- 通过smtplib模块,进行了有附件功能添加的邮件信息的发送(必须要保证你发送的邮箱,smtp功能是打开的,并且获取到邮箱的验证码:秘钥)
数据库数据的读写
python对数据库的操作和使用
oracle:cx_Oracle
hive:pyhive
mysql:mysqllib
pip install cx_Oracle
使用python读取某个excel表格,完成自动建表:
例如,将文件的名字当成表名,第一行当成列名,从第二行开始就是表格的数据。
1先获取当成表格中所有的列名
●使用数据库的模块,例如上面拼接出的列名的建表sql,创建表格
3解析excel每一行的数据,写入到oracle当前的表格中
函数和类
将一个大的脚本和代码,分成多个不同的步骤,来分开实现功能,方便我们维护代码,也方便进行逻辑的描述。
我们可以使用函数来完成每个小步骤的功能编写。
def 函数名字(入参):
函数执行的内容
return返回计算的结果
函数就是一个可以被反复执行的拥有单一功能的代码结构。
函数一定有返回值,通过return返回出来,return可以不写,如果return没有写,那么函数返回的是 None。
我们将刚才写的数据库的操作,各个部分编写成函数,来完成独立的调用:
创建一个 func.py 的文件:
修改获取文件,进行表格创建和数据导入的脚本:
在hive中使用python进行UDF函数的编辑
udf是user defined function,是用户自定义函数。
hive本身没有像oracle或者mysql一样的存储过程以及自定义函数的操作,复杂的数据处理需要借用外部的语言来实现,UDF可以是python也可以是java。
users.id users.name users.card
1001 lilei 756473199807217372
1002 xiaohong 847622199908308642
1003 xixi 768574199705128641
读取这个表格,然后展示四个列,分别是原有的id, name, card 以及性别 gender
使用hive sql的实现方式:
select id,name,card,
case when cast(substr(card,-2,1) as int)%2=1 then '男'
else '女'
end gender
from users;
使用 python 来实现相同的操作:
1编辑一个相同逻辑的Python脚本
2将这个脚本上传到Linux服务器
3在hive中添加这个users.01.py 的python脚本
在hive窗口中运行:
add file 文件的位置和名字;
add file /root/users01.py;
4将文件的执行放入到sql语句
select transform(被查询和计算的列名)
using 'python 函数所在的python文件的名字'
as (新字段的别名)
from 表名;
select transform(id,name,card)
using 'python users01.py'
as (id,name,card,gender)
from users;
现在将表格的读取,逻辑改变一下,要先判断身份证是否符合规则(18位长度全部都是数字,或者18位长度前面是17个数字最后一个是x),如果不符合规则,那么先打印输出 '错误的身份证',符合规则再去判断性别。
select id,name,card,
case when status=0 then '错误的身份证'
when status=1 and cast(substr(card,-2,1) as int)%2=1 then '男'
else '女'
end gender
from(
select id,name,card,
case when length(regexp_replace(card, '[0-9]{17}[0-9x]' , ''))=0 then 1
else 0
end status
from users) t1;
使用python来实现相同的逻辑:
select transform(id,name,card)
using 'python user02.py'
as (id,name,card,gender)
from users;
现在在Hive的表格中,有一个复杂的json,json内容如下:
fruits.id fruits.info
1 {"month":"2020-01","datas":[{"day":"01","apple":9.8,"banana":8.7},{"day":"02","apple":9.7,"banana":8.5},{"day":"03","apple":9.2,"banana":8.8}]}
2 {"month":"2020-02","datas":[{"day":"01","apple":9.5,"banana":8.1},{"day":"02","apple":10,"banana":8.9},{"day":"03","apple":9,"banana":8.3}]}
要对表格的数据进行格式化的操作,这种操作在ods到dws的过程中是非常常见的操作,对字段进行格式的拆分和统一:
dt fruit price
2020-1-1 apple 9.8
2020-1-1 banana 8.7
2020-1-2 apple 9.7
2020-1-2 banana 8.5
2020-1-3 apple 9.2
2020-1-3 banana 8.8
使用python完成:
select transform(id,info)
using 'python f.py'
as (dt,fruit,price)
from fruits;

Adblocker


















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











