



1.2 Hadoop
1.2.1 Hadoop常用端口号
hadoop2.x Hadoop3.x
访问HDFS端口 50070 9870
访问MR执行情况端口 8088 8088
历史服务器 19888 19888
客户端访问集群端口 9000 8020
1.2.2 Hadoop配置文件以及简单的Hadoop集群搭建
(1)配置文件:
Hadoop2.x core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml slaves
Hadoop3.x core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml workers
(2)简单的集群搭建过程:
JDK安装
配置SSH免密登录
配置hadoop核心文件:
格式化namenode
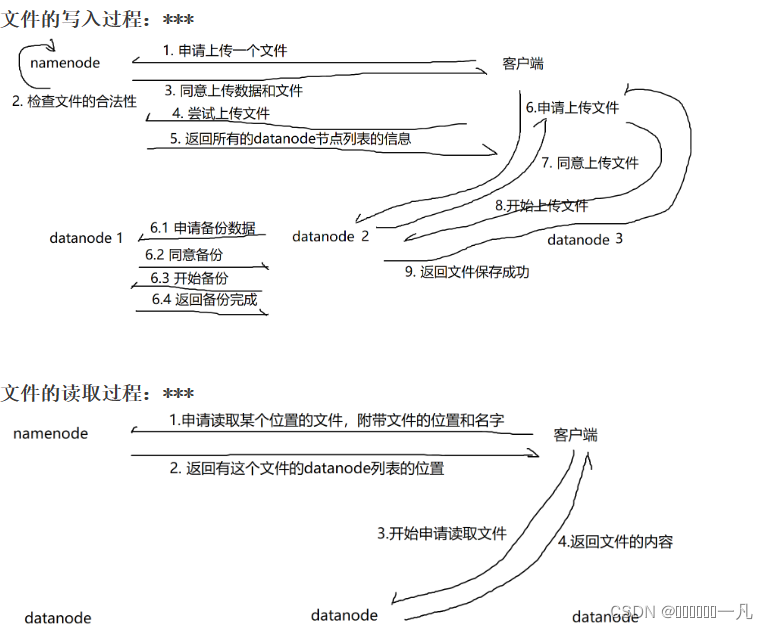
1.2.3 HDFS读流程和写流程
1.2.4 HDFS小文件处理
1)会有什么影响
(1)1个文件块,占用namenode多大内存150字节
1亿个小文件150字节
1 个文件块 * 150字节
128G能存储多少文件块? 128 * 10241024*1024byte/150字节 = 9亿文件块
2)怎么解决
(1)采用har归档方式,将小文件归档
(2)采用CombineTextInputFormat
(3)有小文件场景开启JVM重用;如果没有小文件,不要开启JVM重用,因为会一直占用使用到的task卡槽,直到任务完成才释放。
JVM重用可以使得JVM实例在同一个job中重新使用N次,N的值可以在Hadoop的mapred-site.xml文件中进行配置。通常在10-20之间
mapreduce.job.jvm.numtasks
10
How many tasks to run per jvm,if set to -1 ,there is no limit
1.2.4.1hdfs分布式的文件管理系统
hadoop 2.x的版本中,文件是使用128M的空间进行保存的,hadoop 1.x的版本中,文件是用64M的空间保存的。
文件在hdfs中,都会保存3份。
文件如果是129M,那么会拆分成两个128M的空间进行保存。
SecondaryNameNode 辅助的名称节点:
收集整个平台,所有的机器的运行状态,将运行的状态传递给NameNode
NameNode 名称节点
负责沟通和客户端之前的通信
DataNode 数据节点
负责存储数据
1.2.5Hadoop解决数据倾斜方法
1)提前在map进行combine,减少传输的数据量
在Mapper加上combiner相当于提前进行reduce,即把一个Mapper中的相同key进行了聚合,减少shuffle过程中传输的数据量,以及Reducer端的计算量。
如果导致数据倾斜的key大量分布在不同的mapper的时候,这种方法就不是很有效了。
2)导致数据倾斜的key 大量分布在不同的mapper
(1)局部聚合加全局聚合。
第一次在map阶段对那些导致了数据倾斜的key 加上1到n的随机前缀,这样本来相同的key 也会被分到多个Reducer中进行局部聚合,数量就会大大降低。
第二次mapreduce,去掉key的随机前缀,进行全局聚合。
思想:二次mr,第一次将key随机散列到不同reducer进行处理达到负载均衡目的。第二次再根据去掉key的随机前缀,按原key进行reduce处理。
这个方法进行两次mapreduce,性能稍差。
(2)增加Reducer,提升并行度
JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将key均匀分配到不同Reducer
在这里插入图片描述
HDFS 在读取文件的时候,如果其中一个块突然损坏了怎么办
客户端读取完 DataNode 上的块之后会进行 checksum 验证,也就是把客户端读取到本地的块与 HDFS 上的原始块进行校验,如果发现校验结果不一致,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的 DataNode 继续读。
. HDFS 在上传文件的时候,如果其中一个 DataNode 突然挂掉了怎么办
客户端上传文件时与 DataNode 建立 pipeline 管道,管道的正方向是客户端向DataNode 发送的数据包,管道反向是 DataNode 向客户端发送 ack 确认,也就是正确接收到数据包之后发送一个已确认接收到的应答。当 DataNode 突然挂掉了,客户端接收不到这个 DataNode 发送的 ack 确认,客户端会通知 NameNode,NameNode 检查该块的副本与规定的不符,NameNode 会通知 DataNode 去复制副本,并将挂掉的 DataNode 作下线处理,不再让它参与文件上传与下载
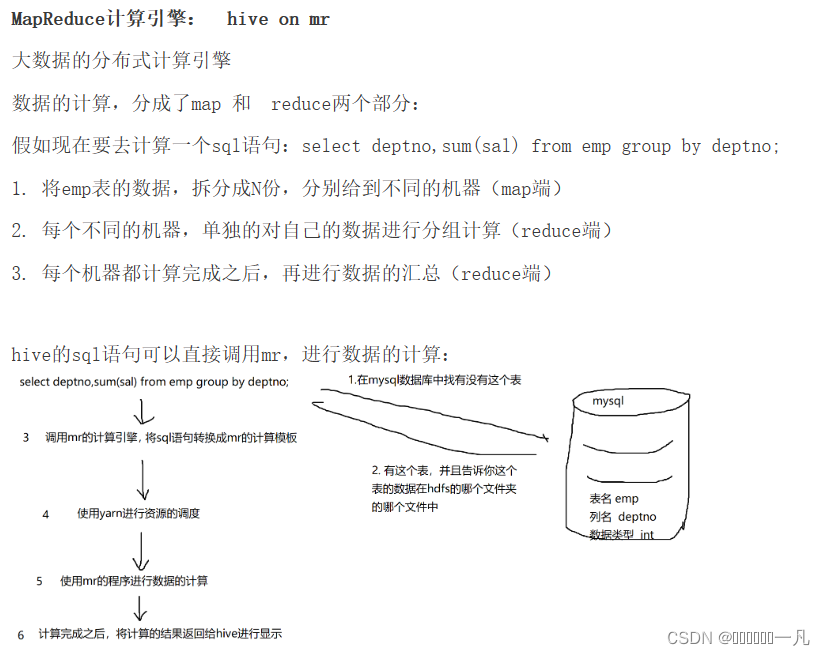
mapreduce的基本原理:
分成map和reduce两个部分,首先是在map端对需要计算的数据进行拆分,分配到不同的计算资源上,分别进行计算,然后在reduce端对计算好的数据进行整合(采用hash分发)


















 3901
3901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











