现在没有报错了,但是跟我想要的功能不太一样,我想要的主要是以下3个功能:1、调用winmerge生成报告,将报告中比较出来有不同的文件的路径,将其粘贴到GA_D82DD83D_00-00-08_QAC.xlsx的sheet:ファイル差分的A列中。2、按照GA_D82DD83D_00-00-08_QAC.xlsx的sheet:_org_fm 第一行的列名,在func_met.csv中寻找,并将找到的内容复制到GA_D82DD83D_00-00-08_QAC.xlsx的sheet:_org_fm 中,按照GA_D82DD83D_00-00-08_QAC.xlsx的sheet:warn中第一行的列名Source,Line #,Level,Warn #,Message与warn.csv中第一行的列名:File,Line ,Grp,Nbr,Description进行一一对应,将warn.csv中的内容复制到GA_D82DD83D_00-00-08_QAC.xlsx的sheet:warn中。3、根据前面复制的内容,逐行分析,首先根据第一行Source列中的路径提取文件名,并查看该文件名是否为第一步差分出来的文件,如果不是则在第一行WarnFilter(变更有无)列的单元格中填充No,如果是,则再根据第一行Line #列单元格中的行数去查找该文件中对应的行数是否有实际变更,如果有则在第一行WarnFilter(变更有无)列的单元格中填充Yes,如果没有在第一行WarnFilter(变更有无)列的单元格中填充No,后面的行都以这种方式去分析,可能比较多有1.5万行左右,但大部分都是不在差分的文件中的。以下是代码:import os
import re
import subprocess
import pandas as pd
from openpyxl import load_workbook, Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import difflib
import sys
import io
import time
import shutil
# 设置系统标准输出为UTF-8
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
sys.stderr = io.TextIOWrapper(sys.stderr.buffer, encoding='utf-8', errors='replace')
def get_changed_files(old_dir, new_dir, winmerge_path):
"""使用WinMerge获取变更文件列表及具体变更行号"""
# 创建临时目录存放报告
temp_dir = os.path.join(os.path.dirname(__file__), "temp")
os.makedirs(temp_dir, exist_ok=True)
report_file = os.path.join(temp_dir, "winmerge_diff_report.txt")
print(f"报告文件路径: {report_file}")
# 移除路径结尾的反斜杠
old_dir = old_dir.rstrip('\\')
new_dir = new_dir.rstrip('\\')
print(f"正在比较目录: {old_dir} 和 {new_dir}")
# 更新WinMerge命令参数 - 使用标准输出捕获
cmd = [
f'"{winmerge_path}"',
'/u', # 使用Unicode
'/r', # 递归比较子目录
'/nl', # 不比较行尾差异
'/noprefs', # 不加载GUI偏好设置
'/noninteractive', # 非交互模式
f'"{old_dir}"',
f'"{new_dir}"'
]
full_cmd = ' '.join(cmd)
print(f"执行命令: {full_cmd}")
changed_files = []
change_map = {} # {filename: set(changed_lines)}
try:
# 直接捕获输出作为报告内容
result = subprocess.run(
full_cmd,
shell=True,
timeout=600, # 10分钟超时
capture_output=True,
text=True,
encoding='utf-16', # WinMerge默认使用UTF-16输出
errors='ignore'
)
# 检查WinMerge退出代码 (0=相同, 1=有差异, >1=错误)
print(f"WinMerge退出代码: {result.returncode}")
print(f"WinMerge输出长度: {len(result.stdout)}字符")
if result.returncode not in (0, 1): # 0-无差异 1-有差异
print(f"WinMerge执行异常")
return changed_files, change_map
# 使用输出作为报告内容
report_content = result.stdout
print(f"报告内容片段: {report_content[:200]}...")
if not report_content.strip():
print(f"警告: WinMerge报告内容为空")
return changed_files, change_map
# 提取所有差异文件
diff_files = set()
# 增强的正则表达式
patterns = [
re.compile(r'文件\s+["\']?(.+?)["\']?\s+和\s+["\']?(.+?)["\']?\s+不同'), # 中文格式
re.compile(r'Files\s+["\']?(.+?)["\']?\s+and\s+["\']?(.+?)["\']?\s+differ'), # 英文格式
re.compile(r'Comparing\s+["\']?(.+?)["\']?\s+and\s+["\']?(.+?)["\']?'),
re.compile(r'File\s+["\']?(.+?)["\']?\s+and\s+["\']?(.+?)["\']?\s+are different')
]
for line in report_content.splitlines():
matched = False
for pattern in patterns:
match = pattern.search(line)
if match:
# 提取新版本文件路径
new_file = match.group(2).strip()
# 规范化路径
new_file = os.path.normpath(new_file)
print(f"识别到差异文件: {new_file}")
diff_files.add(new_file)
matched = True
break
if not matched and ("不同" in line or "differ" in line or "different" in line or "Comparing" in line):
print(f"[未匹配行] {line}")
print(f"发现 {len(diff_files)} 个差异文件")
# 获取变更行号
for file_path in diff_files:
filename = os.path.basename(file_path)
# 构建旧文件路径
rel_path = os.path.relpath(file_path, new_dir)
old_file_path = os.path.join(old_dir, rel_path)
# 检查文件是否存在
if not os.path.isfile(old_file_path):
print(f"旧文件不存在: {old_file_path}")
continue
if not os.path.isfile(file_path):
print(f"新文件不存在: {file_path}")
continue
# 比较文件内容差异
changed_lines = set()
try:
print(f"比较文件: {old_file_path} vs {file_path}")
with open(old_file_path, 'r', encoding='utf-8', errors='ignore') as f_old:
content_old = f_old.readlines()
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f_new:
content_new = f_new.readlines()
diff = difflib.unified_diff(
content_old,
content_new,
fromfile=old_file_path,
tofile=file_path,
n=0 # 不显示上下文
)
for line_diff in diff:
if line_diff.startswith('@@'):
# 提取变更行号
match_diff = re.search(r'\+(\d+)(?:,(\d+))?', line_diff)
if match_diff:
start_line = int(match_diff.group(1))
line_count = int(match_extras.group(2)) if match_diff.group(2) else 1
changed_lines.update(range(start_line, start_line + line_count))
except Exception as e:
print(f"错误比较文件 {old_file_path} 和 {file_path}: {str(e)}")
changed_files.append(filename)
change_map[filename] = changed_lines
print(f"变更文件: {filename} - {len(changed_lines)} 行变更")
except subprocess.TimeoutExpired:
print("WinMerge执行超时,强制终止")
except Exception as e:
print(f"处理报告文件时出错: {str(e)}")
import traceback
traceback.print_exc()
return changed_files, change_map
def detect_encoding(file_path):
"""检测文件编码"""
# 常见编码类型列表(可根据需要扩展)
encodings = ['utf-8', 'shift_jis', 'cp932', 'latin1', 'iso-8859-1', 'euc-jp']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
f.read(1024) # 仅读取部分内容测试
return encoding
except UnicodeDecodeError:
continue
return None
def update_excel_sheets(csv_folder, output_excel, changed_files, change_map):
"""更新Excel表格标记变更文件"""
try:
print(f"开始更新Excel: {output_excel}")
print(f"变更文件数: {len(changed_files)}")
# 加载或创建Excel文件
if os.path.exists(output_excel):
print(f"发现现有Excel文件: {output_excel}")
try:
wb = load_workbook(output_excel)
print("成功加载现有Excel文件")
except Exception as e:
print(f"加载Excel失败: {e},将创建新文件")
# 改进备份策略 - 复制而非重命名
timestamp = time.strftime("%Y%m%d_%H%M%S")
backup_name = f"{output_excel}.bak_{timestamp}"
try:
# 复制文件而非重命名
shutil.copy2(output_excel, backup_name)
print(f"已将损坏文件复制至: {backup_name}")
# 尝试删除原文件(可选)
try:
os.remove(output_excel)
print(f"已删除原损坏文件")
except PermissionError:
print(f"无法删除原文件,可能仍被占用")
except Exception as backup_error:
print(f"备份文件时出错: {backup_error}")
# 创建新工作簿
wb = Workbook()
else:
print("创建新的Excel文件")
wb = Workbook()
# 确保至少有一个sheet存在
if not wb.sheetnames:
wb.create_sheet("默认Sheet")
print("创建默认Sheet以避免空工作簿错误")
# 处理每个CSV文件
csv_files = [f for f in os.listdir(csv_folder) if f.endswith('.csv')]
if not csv_files:
print(f"警告: 在 {csv_folder} 中未找到任何CSV文件")
# 保存工作簿(包含默认Sheet)
wb.save(output_excel)
print(f"成功保存Excel: {output_excel}")
return True
for csv_file in csv_files:
csv_path = os.path.join(csv_folder, csv_file)
sheet_name = os.path.splitext(csv_file)[0][:30] # 限制sheet名称长度
print(f"处理CSV: {csv_file} -> Sheet '{sheet_name}'")
try:
# 检测文件编码
detected_encoding = detect_encoding(csv_path)
if detected_encoding:
print(f"检测到编码: {detected_encoding}")
df = pd.read_csv(csv_path, encoding=detected_encoding)
else:
print(f"警告: 无法检测编码,使用utf-8并忽略错误")
df = pd.read_csv(csv_path, encoding='utf-8', errors='replace')
# 添加变更标记列
if 'Changed' not in df.columns:
df['Changed'] = 'No'
if 'Changed Lines' not in df.columns:
df['Changed Lines'] = ''
# 标记变更文件
changed_count = 0
for index, row in df.iterrows():
if 'File' not in row:
continue
# 提取文件名(不带路径)
filename = os.path.basename(str(row['File']))
if filename in changed_files:
changed_count += 1
df.at[index, 'Changed'] = 'Yes'
if filename in change_map and change_map[filename]:
lines = sorted(change_map[filename])
df.at[index, 'Changed Lines'] = ','.join(map(str, lines))
print(f"标记 {changed_count} 个变更文件")
# 写入Excel
if sheet_name in wb.sheetnames:
print(f"删除现有Sheet: {sheet_name}")
del wb[sheet_name]
ws = wb.create_sheet(sheet_name)
print(f"创建新Sheet: {sheet_name}")
# 写入DataFrame数据
for row in dataframe_to_rows(df, index=False, header=True):
ws.append(row)
except Exception as e:
print(f"处理CSV文件 {csv_file} 出错: {str(e)}")
import traceback
traceback.print_exc()
# 保存Excel
wb.save(output_excel)
print(f"成功保存Excel: {output_excel}")
return True
except Exception as e:
print(f"更新Excel出错: {str(e)}")
import traceback
traceback.print_exc()
return False
def main():
# 配置路径(根据实际情况修改)
old_code_dir = r"E:\system\Desktop\项目所需文件\工具\ffff\code\old\GA_D82DD83D_00-00-07\mainline\spa_traveo\src"
new_code_dir = r"E:\system\Desktop\项目所需文件\工具\ffff\code\new\GA_D82DD83D_00-00-08\mainline\spa_traveo\src"
csv_folder = r"E:\system\Desktop\项目所需文件\工具\ffff\APL\Tool出力結果"
output_excel = r"E:\system\Desktop\项目所需文件\工具\ffff\GA_D82DD83D_00-00-08_QAC.xlsx"
winmerge_path = r"E:/App/WinMerge/WinMerge/WinMergeU.exe"
print("="*50)
print("开始文件比较...")
try:
changed_files, change_map = get_changed_files(old_code_dir, new_code_dir, winmerge_path)
print(f"找到 {len(changed_files)} 个变更文件")
print("="*50)
print("更新Excel表格...")
success = update_excel_sheets(csv_folder, output_excel, changed_files, change_map)
if success:
print(f"处理完成! 输出文件: {output_excel}")
else:
print("处理失败,请检查错误日志")
except Exception as e:
print(f"处理过程中发生错误: {str(e)}")
import traceback
traceback.print_exc()
print("="*50)
print("程序结束")
if __name__ == "__main__":
main()
最新发布




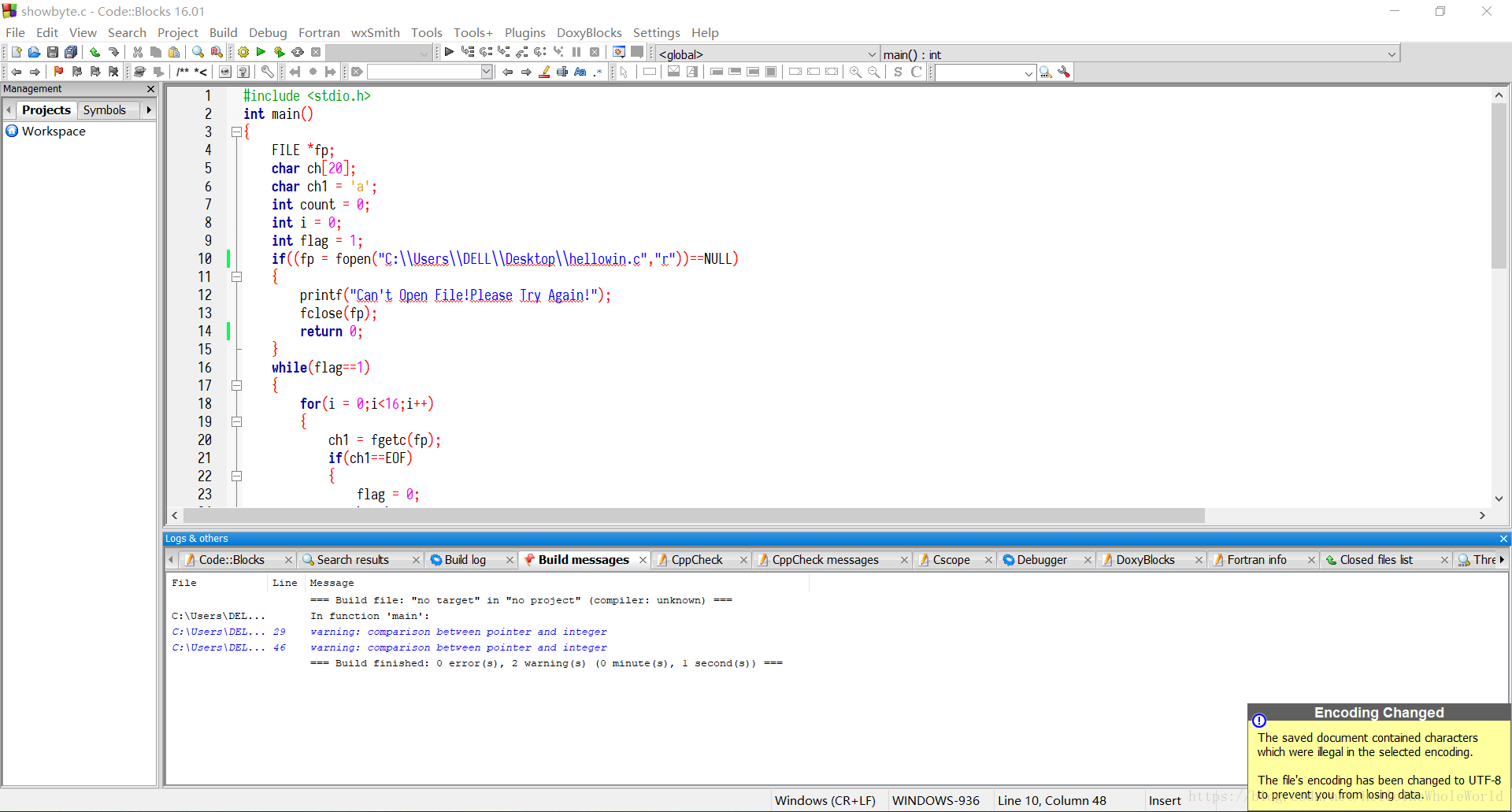
 本文通过一个实际案例探讨了在文件操作过程中遇到的编码问题。当从一个文件中拷贝内容到另一个文件时,若源文件与目标文件的编码类型不一致,则可能导致文件保存失败或出现乱码。文章建议在进行拷贝操作前,最好先将所有内容统一到相同的编码格式,避免因编码问题引发的错误。
本文通过一个实际案例探讨了在文件操作过程中遇到的编码问题。当从一个文件中拷贝内容到另一个文件时,若源文件与目标文件的编码类型不一致,则可能导致文件保存失败或出现乱码。文章建议在进行拷贝操作前,最好先将所有内容统一到相同的编码格式,避免因编码问题引发的错误。

















 4394
4394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









