




初识指针(引入地址的概念)
首先:我们知道,一个变量的四个要素(变量名、变量的数据类型、变量的值、内存地址)。我们平时做的事就是使用变量的名来访问变量的值,也可以通过取地址符&来获取变量的地址,就比如下面这张图:

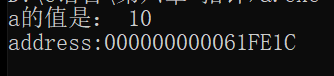
根据上面的代码展示,我们清晰的知道了怎么从变量中获取它的值(原样输出)和地址,那么思考一个问题:能不能根据变量的地址来获取变量的值?
引入一个运算符:*,星号又叫取值运算符,它就能根据变量的地址获取对应变量的值,如下面这串的代码:

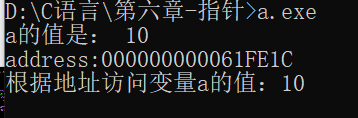
根据地址来访问变量的值,就是指针的操作。没错,指针就是地址,地址就是指针:
举个例子:将指针的概念放到实际生活中的游标卡尺,那个位于尺子下方的那个小三角就是指针,尺子上的刻度就是地址,刻度对应的数字就是变量值
总结:我们既可以根据变量名来获取变量值(直接访问),也可以根据变量的内存地址也就是指针来获取变量的值(简介访问)
指针变量
根据上面我们知道了指针这个概念(指针与地址绑定),那我们再思考一下:平时那些变量都是用来存放数据的,那么有没有一种变量可以存放地址的?
答案是有的,就是指针变量,写法格式: 数据类型 *变量名;所谓指针变量,就是存放别人地址的变量。
那么上面变量的四要素提及了三个(变量名、变量值、便量的内存地址),那么变量的数据类型与指针又有什么练习?
让我们看下面这个例子:
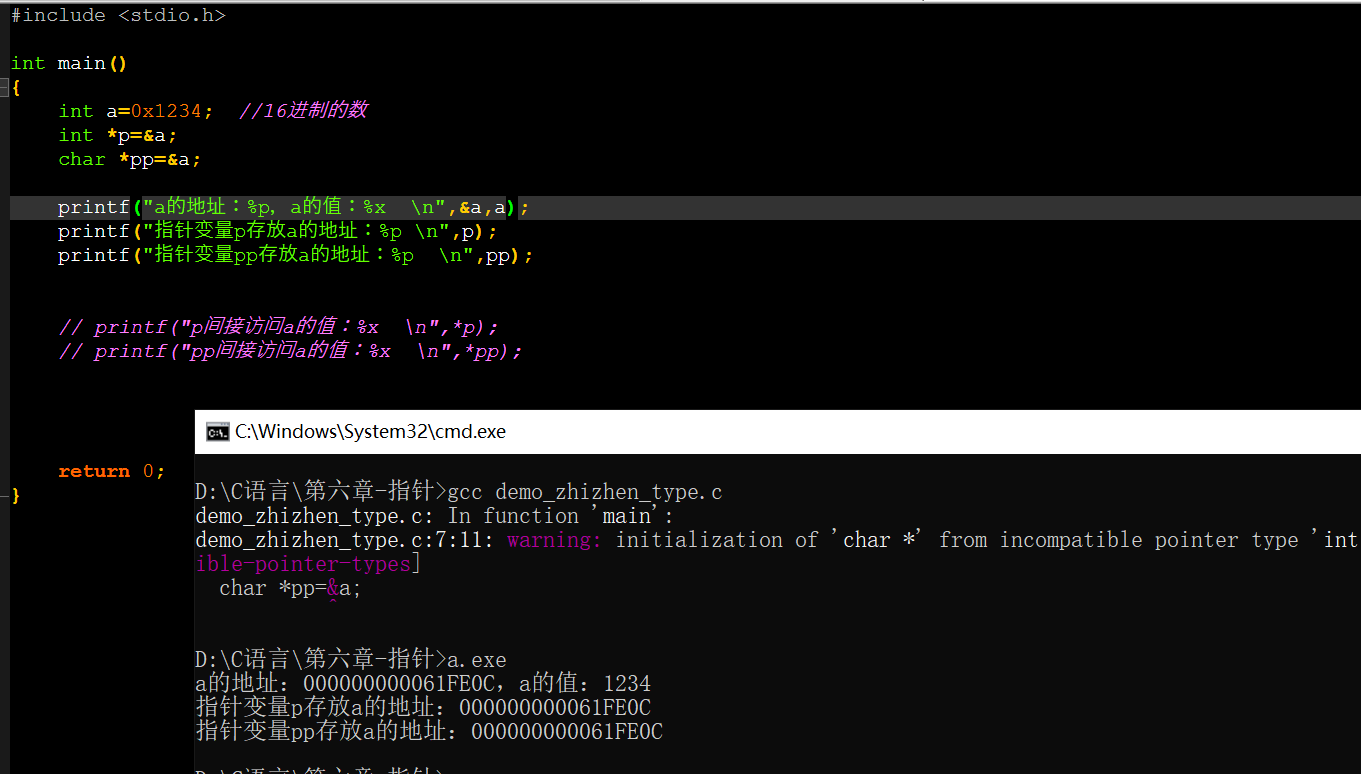
我们编译结果有一个警告:pp指针变量的类型不匹配。但是指针变量p和pp虽然数据类型不同,但继续编译出来的结果没有错,看起来并没有问题,那我们继续往下看:
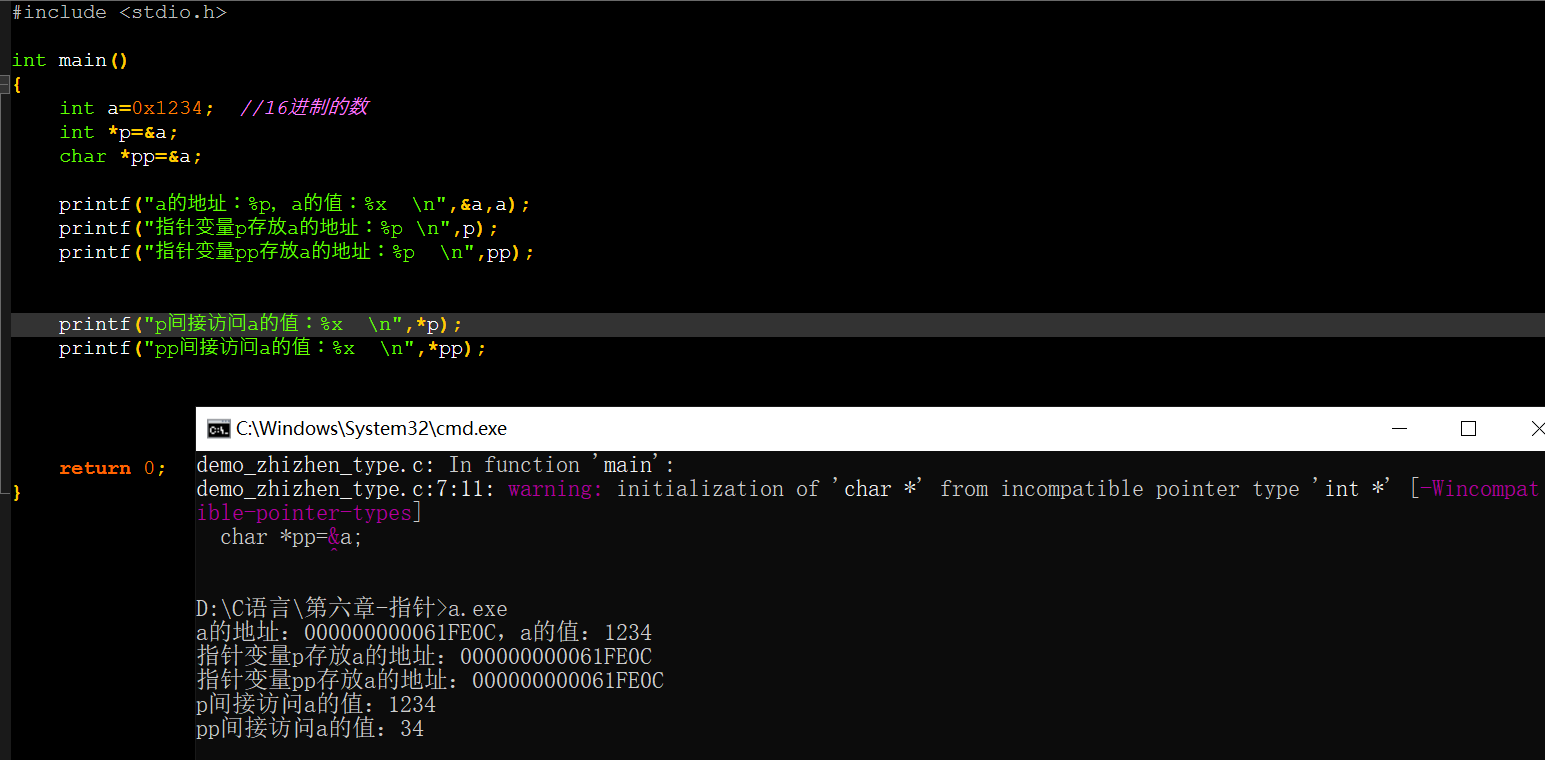
从这个编译结果看到,明明编译出来的地址是一致的,那为什么访问出来的值并不一致?
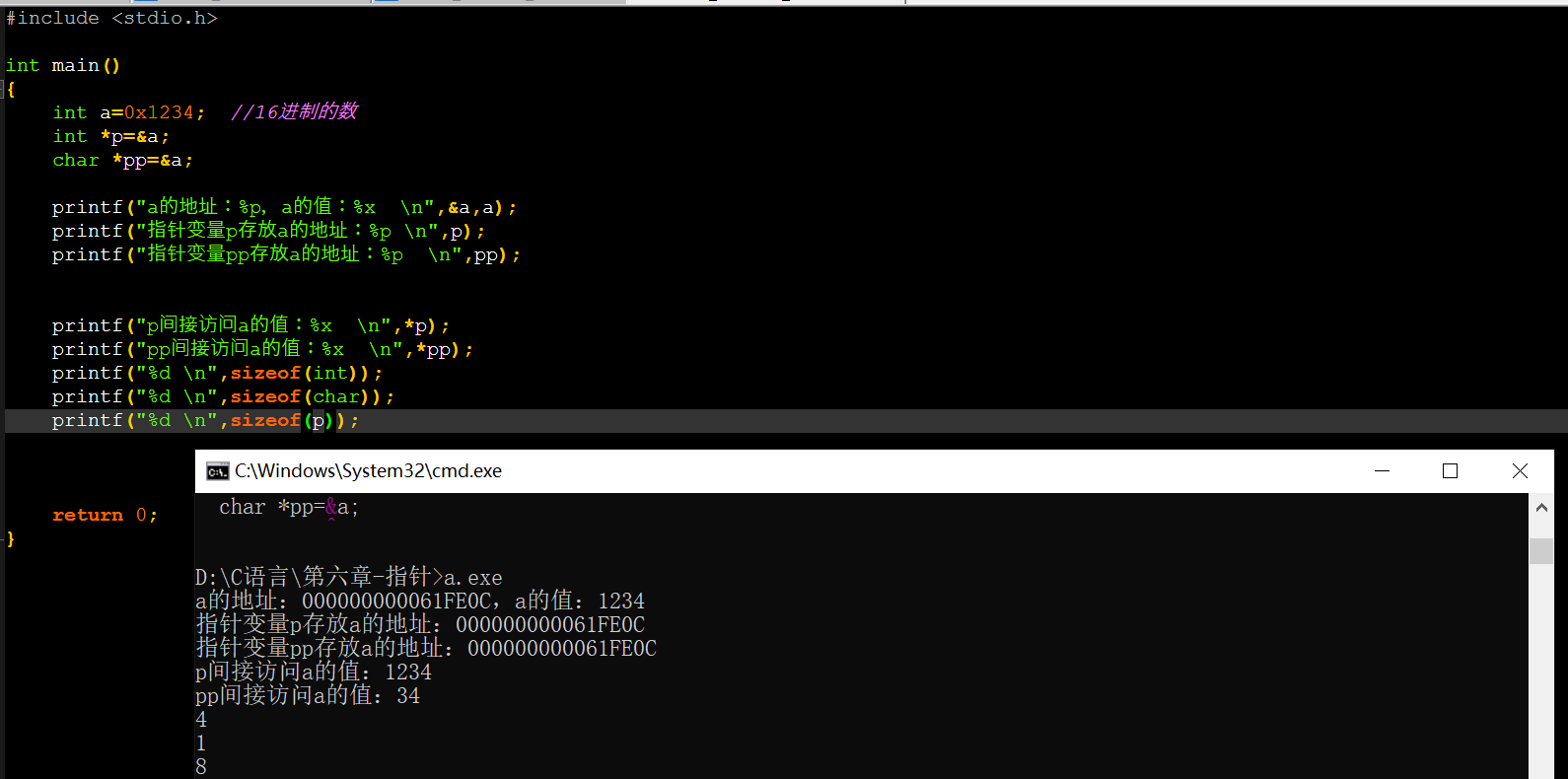
我们通过sizeof关键字来获取了char、int和指针变的大小,int占4字节(32位),char占1字节(8位),指针变量占8字节(64位)。(一个字节占8位)。
提及一个概念:取值运算符*会根据指针类型来进行取值,int型在内存空间中占4个字节(32位),char占1个字节(8位),而a定义的值是16进制的:因此该值需要16位来进行存储(补充:16进制的数在内存中需要四位来进行存储):示意图:
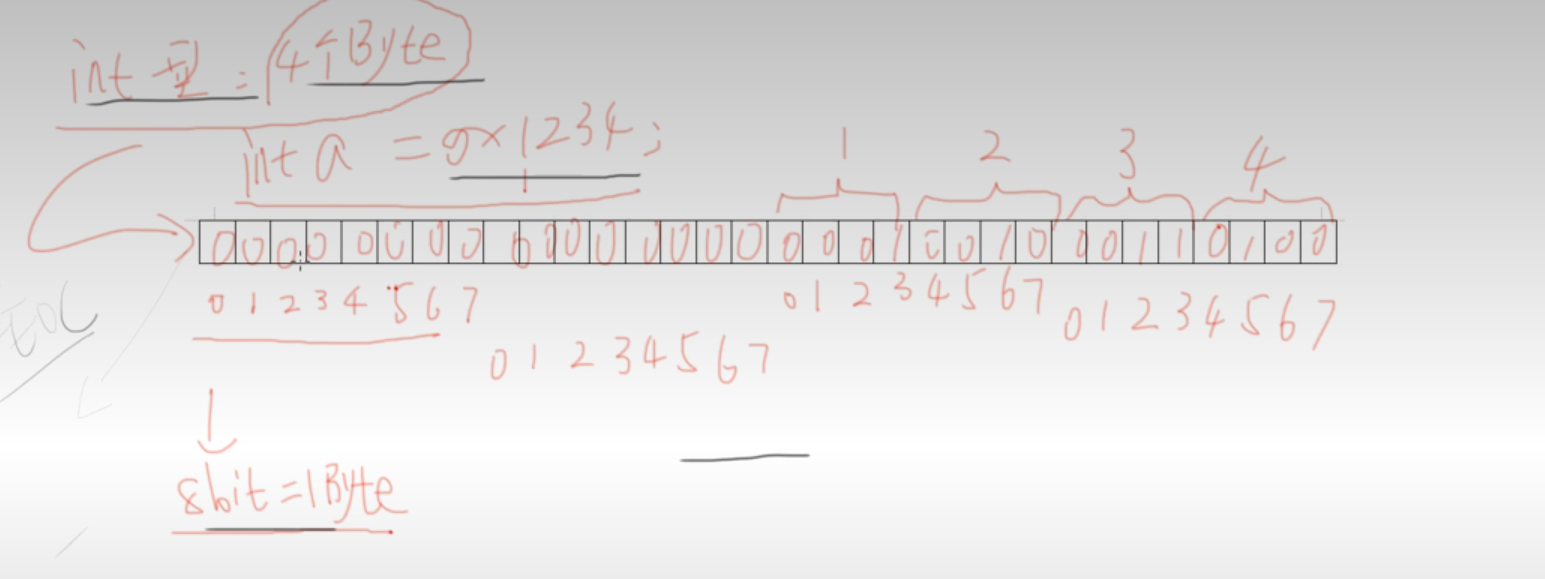
内存的读取顺序是从右往左,所以取值运算符能完整访问出来int *p,而char *pp只有八位因此只能访问出34。也就是说,指针变量的数据类型与被存放地址变量的类型不一致时,取值运算符访问取值的时候跨度也是不一样的,因此要求指针变量类型一致。
再接着往下看地址的跨度:
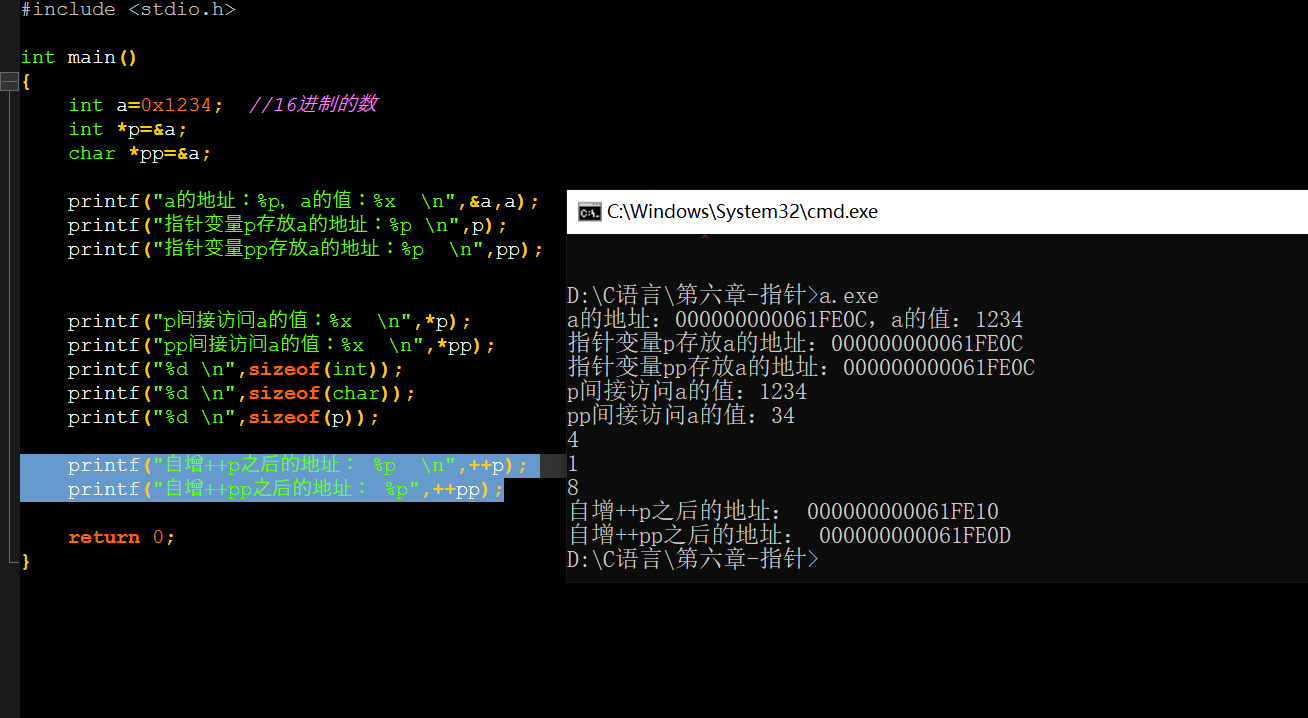
高亮的部分是进行地值自增的操作,可以看到p自增与pp自增之后得到的地址是不一致的。因为p是int类型4个字节(32位),pp是char类型1个字节(8位),(地址也是16进制的),a也是int类型32位,因此刚开始地址都是FE0C,p进行自增后具有增一位补0也就是FE10;pp进行自增就只能是FE0D。
总结:定义指针变量时,类型也要一致,因为它指向内存空间的大小,也决定增量
为什么需要指针变量
知道了指针变量之后,我们来思考为什么需要指针变量?
看下面这个案例:
用函数封装的方式来进行两个值的交换
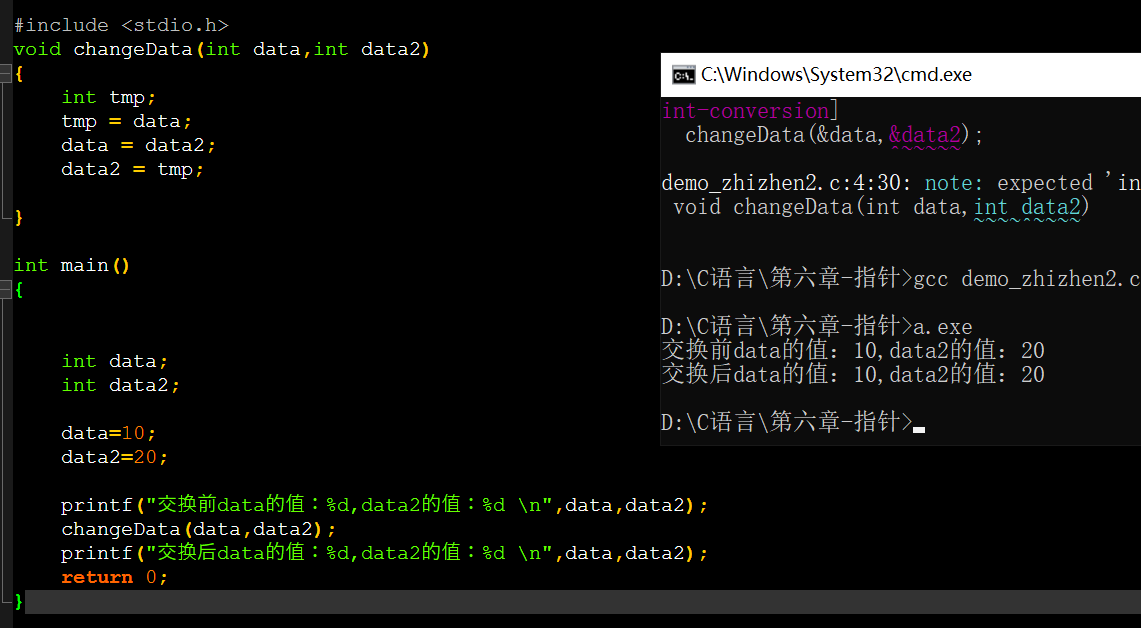
我们可以看到,实际数据并没有交换成功。可以提及一个概念(形参的生命周期:形参只有在函数被调用时才会被系统临时赋予内存空间,并且他是会有属于自己的内存地址,也就说,尽管形参与实参名字一致,但从地址来说,并不是一个东西,在函数调用结束后形参的内存会被系统回收释放)。
也就是说,实参的值通过值传递(值拷贝)给了形参,并在函数中也确实进行了改变,但是函数调用结束时这个改变的值也跟随着形参被释放而被释放了,因此main中实参的值并没有进行交换,而是原样输出。
你可能想说在函数中将交换过的值直接return回来,但是答案是,返回值不支持多个值。
所以这个时候就要用到我们的指针变量:
将实参的内存地址传给形参(存放地址需要指针变量地址,形参得定义成指针变量并且类型一致),在进行交换就可以得到交换后的结果。
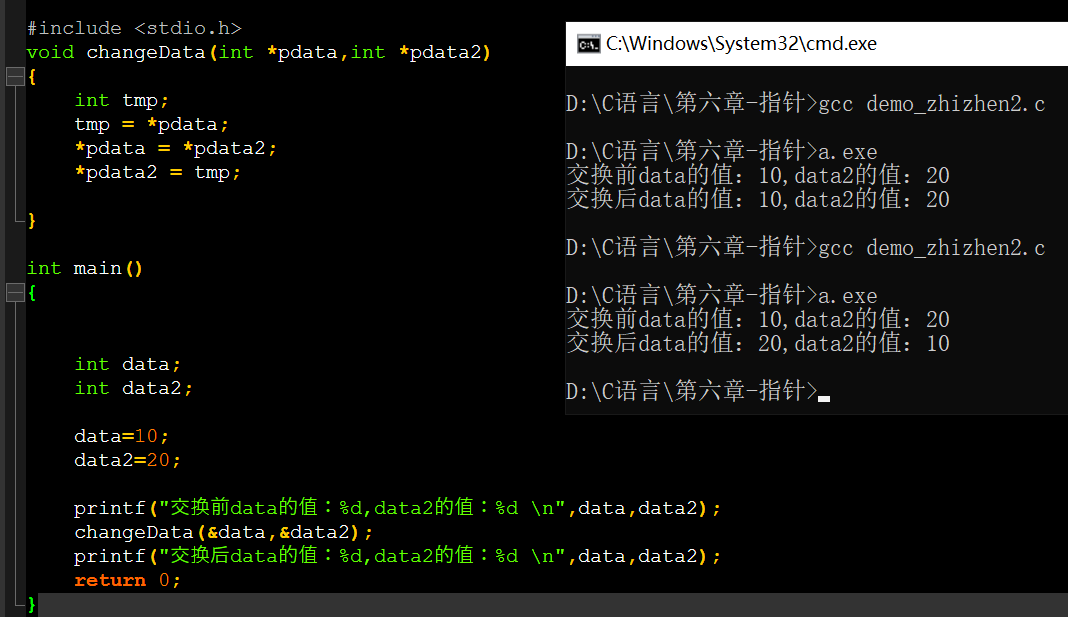
为什么指针变量就可以呢?因为指针变量是过地址间接访问实参的值
我们来看一下传递过程:
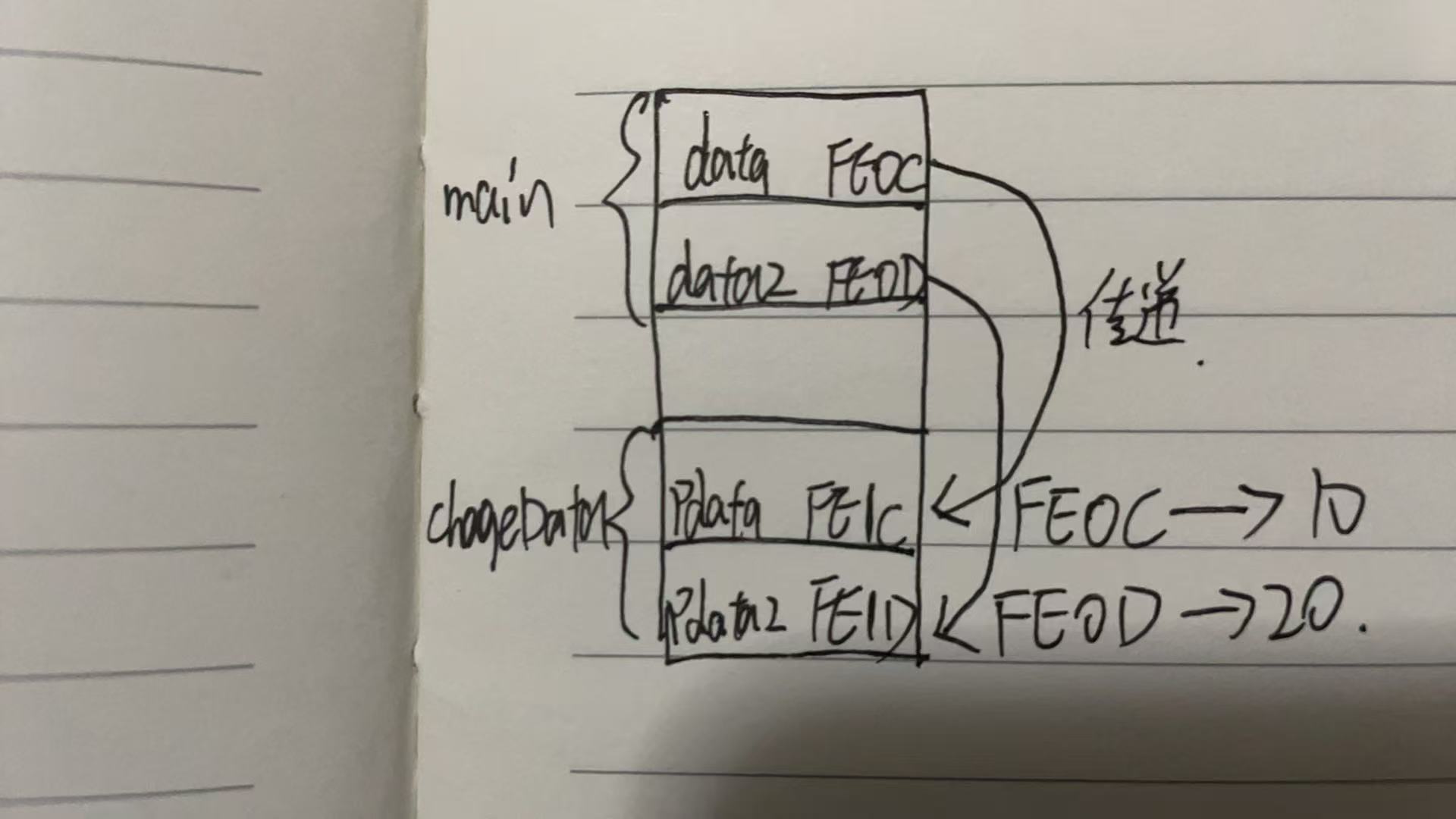
指针变量接收到值了(也就是main中实参的地址),那么通过取值运算符*就能访问到传过来对应地址的值,也就是说*pdata=10,*pdata2=20,尽管形参最后会被释放,但是因为他操作的就是main中data和data2内存地址其对应的值,所以,最终main中data和data2的值进行了交换。
总结:指针==地址;指针的数据类型要与之一致

















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









