



一、基础Sql
SELECT * FROM Websites
WHERE alexa > 15
AND (country='CN' OR country='USA')
ORDER BY alexa DESC;
INSERT INTO Websites (name, url, alexa, country)
VALUES ('百度','https://www.baidu.com/','4','CN'); UPDATE Websites
SET alexa='5000', country='USA'
WHERE name='菜鸟教程'; DELETE FROM Websites
WHERE name='百度' AND country='CN'; CREATE DATABASE my_db; CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int, PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
) DROP TABLE table_name二、进阶Sql
1.分页
①.Top
SELECT TOP number|percent column_name(s)
FROM table_name;注意:并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
②.Mysql
SELECT *
FROM Persons
LIMIT 5;③.Oracle
SELECT *
FROM Persons
WHERE ROWNUM <=5;2.模糊查询
SELECT * FROM Websites
WHERE name NOT LIKE '%oo%';3.通配符

以Mysql为例:
过滤名字以A到H开头的结果,第二段反之。中括号中是正则表达式
SELECT * FROM Websites
WHERE name REGEXP '^[A-H]'; SELECT * FROM Websites
WHERE name REGEXP '^[^A-H]';4.连接
分为内连接(连接),左右连接,全连接。其实就是对于集合的在取交集的时候,只取交集,还是既去交集又 取左边,又取右边。如下图

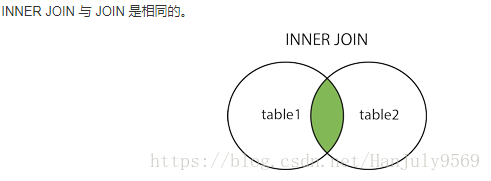
代码示例:
SELECT tb_student.*,tb_class.name
FROM tb_student INNER JOIN tb_class
ON tb_student.classID=tb_class.id; SELECT tb_student.name,tb_class.name
FROM tb_student LEFT OUTER JOIN tb_class
ON tb_student.classID=tb_class.id;5.Having 和 Group by
由于where子句中不能使用聚合函数所以,出现了having.
SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log
INNER JOIN Websites
ON access_log.site_id=Websites.id)
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;6.创建索引加快查询速度
CREATE INDEX PIndex
ON Persons (LastName)三、触发器
当发生预料的操作时,去进行其他的操作。
触发器分为After,before和Insert,update,delete两大类,然后组合后变为六种。同一张表,同样的触发器只能创建一个
new字段代表插入时数据,更新的新数据,old字段表示更新的旧数据,删除的数据。
触发器具有事务支持
1.如果BEFORE触发器执行失败,SQL无法正确执行。
2.SQL执行失败时,AFTER型触发器不会触发。
3.AFTER类型的触发器执行失败,SQL会回滚。
CREATE TRIGGER test_tt AFTER DELETE ON `test` FOR EACH ROW
BEGIN
DECLARE s VARCHAR(20) DEFAULT 'hello';
SET s = 'world';
UPDATE `member` SET `name` = s WHERE id = OLD.id;
END四、存储过程
存储过程用来封装一系列的sql,提高代码可读性和可维护性,和函数差不多。
比较如下截图。
复杂一点的过程, 根据用户id获取该用户的所有订单价格, 并动态的选择是否加税。代码设计如下
create procedure getTotalByUser2(
in userId int,
in falg boolean, -- 是否加税标记
out total decimal(8,2)
)
begin
DECLARE tmptotal DECIMAL(8,2);
DECLARE taxrate int DEFAULT 6;-- 默认的加税的利率
select SUM(r.price) from order r
where r.u_id = userId
into tmptotal;
if taxable then
select tmptotal + (tmptotal/1000*taxrate) into tmptotal;
end if;
select tmptotal into total;
END;该过程传入三个参数, 用户id, 是否加税以及返回的总价格,在过程内部, 定义两个局部变量tmptotal和taxrate,把查询出来的结果赋给临时变量, 在判断是否加税。最后把局部变量的值赋给输出参数。
call getTotalByUser2(1, false, @total); -- 不加税
call getTotalByUser2(1, true, @total); -- 加税
select @total;定义一个返回字符串的自定义函数:
DELIMITER // CREATE FUNCTION getName(id INT) RETURNS CHAR(50) RETURN (SELECT name FROM t WHERE id=id); // DELIMITER ;
函数的调用
定义函数后,可以通过SELECT语句来调用函数:
SELECT getName(1); +----------------+ | getName(1) | +----------------+ | itbilu.com | +----------------+ 1 row in set (0.00 sec)
参考:存储过程与函数
五、范式
1.1NF
属性的原子性,不可分割。
所有的关系型数据库,都不允许的。
2.2NF
有关键字唯一确定一列,并且非主属性必须完全依赖关键字。
比如:把符合范式的两张表合并,两个id作为主键,就会出现非主属性对主键的部分依赖,并产生冗余。
3.NF
不存在传递依赖。
比如:上面的情况,只用一个id作为主键,就会出现,主键id决定另一个id,另一个id决定其他属性的传递依赖
(学号,姓名,班级,班主任)如果学号作为主键。
学号--->班级---->班主任
4.BCNF
不存在关键字决定关键字的情况。
一般的设计都是符合3范式以上的。

















 2767
2767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









