



 本文介绍了一个关于Web安全的练习,重点是理解robots.txt协议的工作原理和目的。robots.txt是一个用于指示搜索引擎哪些页面可抓取、哪些禁止抓取的文件。虽然该协议不具备强制执行力,但通常被搜索引擎遵循。通过访问提供的链接并了解如何利用robots.txt,你可以学习如何保护网站的隐私并控制搜索引擎的抓取行为。完成练习后,你将能够更好地理解和应用robots协议。
本文介绍了一个关于Web安全的练习,重点是理解robots.txt协议的工作原理和目的。robots.txt是一个用于指示搜索引擎哪些页面可抓取、哪些禁止抓取的文件。虽然该协议不具备强制执行力,但通常被搜索引擎遵循。通过访问提供的链接并了解如何利用robots.txt,你可以学习如何保护网站的隐私并控制搜索引擎的抓取行为。完成练习后,你将能够更好地理解和应用robots协议。
攻防世界web练习
十四、Training-WWW-Robots(训练网站robots协议)
http://111.200.241.244:63550/
【原理】
robots.txt
robotsrobots.txt一般指robots协议。
协议也称爬虫协议、爬虫规则,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。但是,这个robots协议不是防火墙,也没有强制执行力,搜索引擎完全可以忽视robots.txt文件去抓取网页的快照。
如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
【目的】
学习robots.txt
【环境】
windows
【工具】
浏览器
【步骤】
-
输入/robots.txt
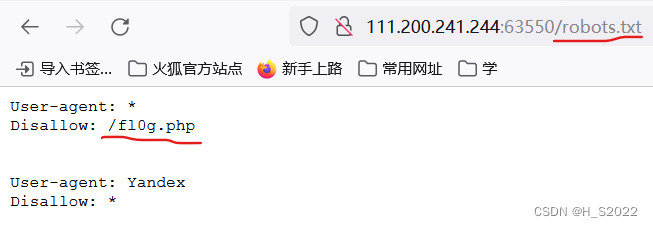
-
然后打开fl0g.php就可以看到flag
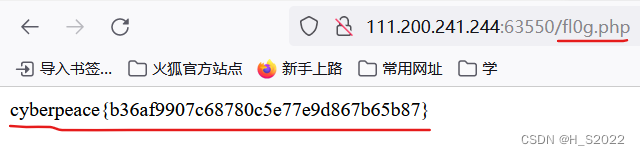


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









