




 本文深入探讨了主成分分析(PCA)的两种实现方法:利用numpy库和sklearn包。详细介绍了PCA的工作原理,包括数据预处理、协方差矩阵计算、特征值分解等关键步骤。通过具体案例展示了如何使用PCA进行数据降维,并比较了两种实现方法的一致性。
本文深入探讨了主成分分析(PCA)的两种实现方法:利用numpy库和sklearn包。详细介绍了PCA的工作原理,包括数据预处理、协方差矩阵计算、特征值分解等关键步骤。通过具体案例展示了如何使用PCA进行数据降维,并比较了两种实现方法的一致性。
主成分分析(Principal Component Analysis,PCA)。在PCA中,数据从原来的坐标系转换到了新的坐标系,新坐标系的选择是由数据本身决定的。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴的选择和第一个坐标轴正交且具有最大方差的方向。该过程一直重复,重复次数为原始数据中特征的数目。我们会发现,大部分方差都包含在最前面的几个新坐标轴中。因此,我们可以忽略余下的坐标轴,即对数据进行了降维处理。

1、pca的第一种实现方式(运用numpy的函数)
将数据转换成前N个主成分的伪码大致如下:
去除平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值从大到小排序
保留最上面的N个特征向量
将数据转换到上述N个特征向量构建的新空间中
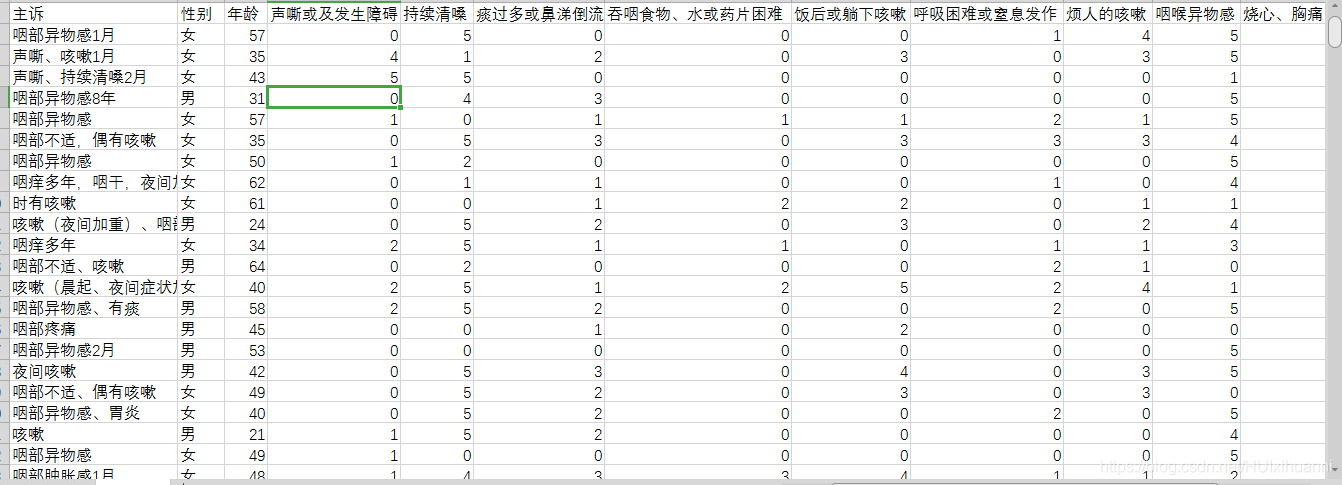
我的数据是这种样子的,我主要对第三列之后的特征进行主成分分析:
代码如下:
from numpy import *
import pandas as pd
a = pd.read_excel(r'C:\Users\lenovo\Documents\WeChat Files\aiwohaiaini\FileStorage\File\2019-05\统计表(截止至五月一日全).xlsx')
X= mat(a.iloc[:,3:-1]) #不选择姓名 性别 和最后一列
X[isnan(X)] = mean(X[~isnan(X)]) #将矩阵中的nan替代为平均值
def pca(dataMat,topNfeat = 7):
meanVals = mean(dataMat,axis= 0) #对axis = 0 上的数据求平均
meanRemoved = dataMat - meanVals #每列的数据
covMat = cov(meanRemoved,rowvar=0) #将每列作为特征求协方差矩阵
eigVals,eigVects = linalg.eig(mat(covMat)) #求协方差矩阵的特征值 和 特征向量
eigValInd = argsort(eigVals) #将特征值按照从小到大排序
eigValInd = eigValInd[:-(topNfeat+1):-1] #取从大到小(上面排序的逆序)去前topNfeat个数,如果topNfeat大于 列表的长度的话,取全部
redEigVects = eigVects[:,eigValInd] #特征向量
lowDDataMat = meanRemoved * redEigVects #将数据转换到新空间
return lowDDataMat
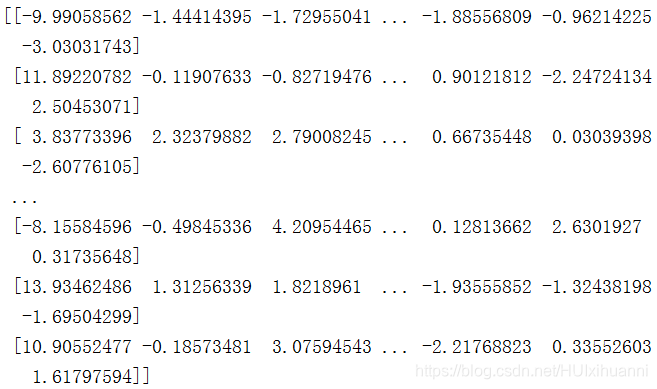
print(pca(X))
当需要进行主成分分析的矩阵中有NaN的时候,可以将NaN转化成这个矩阵其余非NaN部分的平均值。
2、pca的第二种实现方式(运用Python的sklearn包中自带的pca函数)
from sklearn.decomposition import PCA
a = pd.read_excel(r'C:\Users\lenovo\Documents\WeChat Files\aiwohaiaini\FileStorage\File\2019-05\统计表(截止至五月一日全).xlsx')
X= mat(a.iloc[:,3:-1]) #不选择姓名 性别 和最后一列
X[isnan(X)] = mean(X[~isnan(X)]) #将矩阵中的nan替代为平均值
#第一种方法
pca = PCA(n_components='mle') # 此时PCA类会用MLE算法根据特征的方差分布情况自己去选择一定数量的主成分特征来降维
pca.fit(X)
print(pca.explained_variance_ratio_)
#xplained_variance_ratio_:array, [n_components]返回 所保留的n个成分各自的方差百分比,这里可以理解为单个变量方差贡献率,
#[0.86047295 0.02638764 0.02244028 0.02159876 0.0179959 0.01677725 0.01176986]
print(pca.n_components_)
print(pca.fit_transform(X))
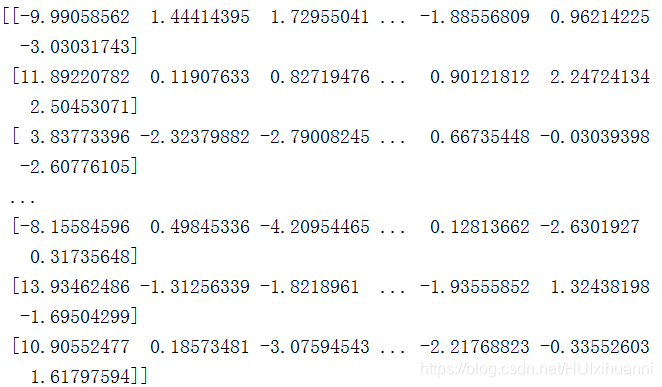
两种方法产生的结果一致~

















 1464
1464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









