




 本文介绍了分布式ID及雪花算法。随着业务扩展,传统ID生成方式无法满足需求,雪花算法应运而生。它由Twitter开源,生成的ID由64位二进制组成,分四部分。文中还给出Java实现及常见问题解答,该算法能解决分布式架构下ID唯一性等问题。
本文介绍了分布式ID及雪花算法。随着业务扩展,传统ID生成方式无法满足需求,雪花算法应运而生。它由Twitter开源,生成的ID由64位二进制组成,分四部分。文中还给出Java实现及常见问题解答,该算法能解决分布式架构下ID唯一性等问题。
分布式ID
分布式ID,也称为全局唯一ID,是在分布式系统中用于标识数据的唯一标识符。随着业务量的不断扩展,传统的UUID和数据库自增ID无法满足需求,需要进行分库分表,而分表后,每个表中的数据都会按自己的节奏进行自增,很有可能出现ID冲突。此时就需要一个单独的机制来负责生成唯一ID,生成出来的ID也可以叫做分布式ID,或全局ID。这个ID应满足全局唯一性、高性能和趋势递增等要求。
一、雪花算法起源
Snowflake中文的意思是“雪花”(因为在大自然中,不可能存在两片一模一样的雪花),所以被翻译成雪花算法。它最早是twitter内部使用的分布式环境下的唯一ID生成算法,在2014年开源。
二、雪花算法的原理
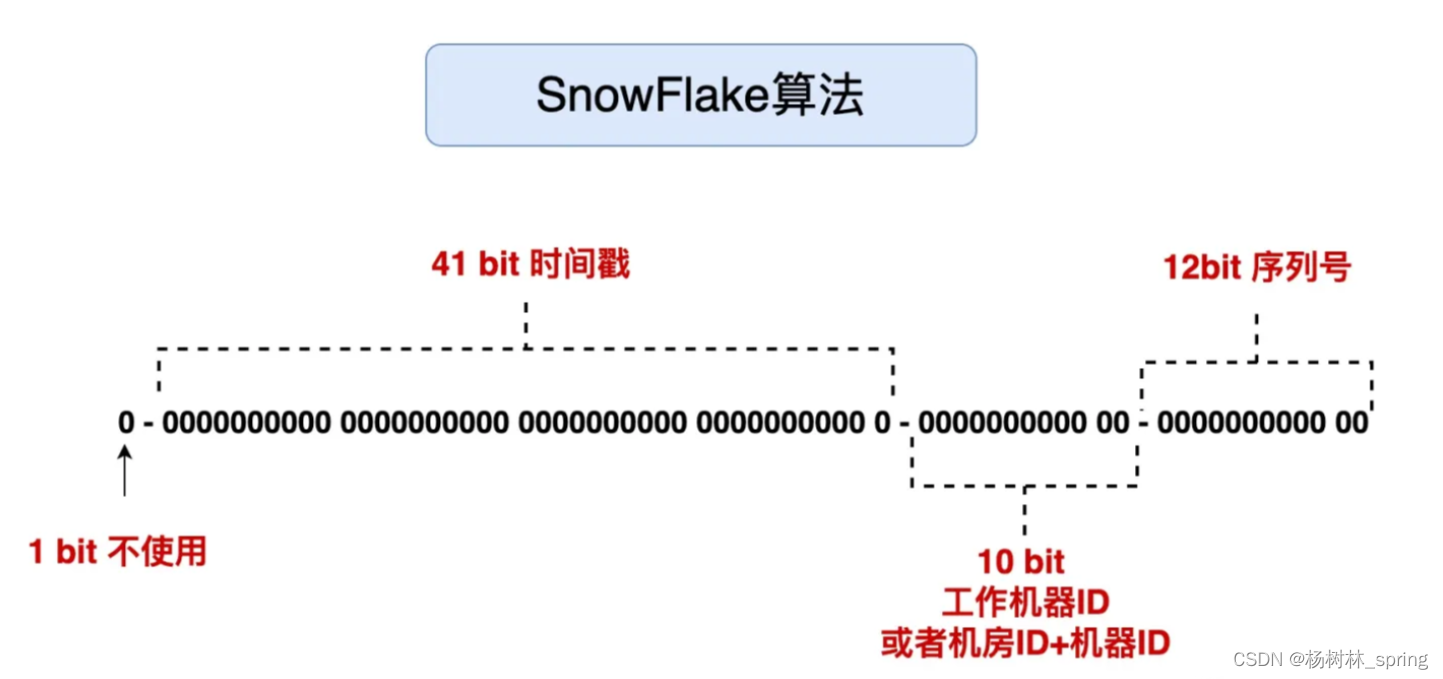
Snowflake产生的ID由 64 bit 的二进制数字组成,被分成了4个部分,每一部分存储的数据都有特定的含义:
> 第 0 位: 符号位(标识正负),始终为 0;
> 第 1~41 位 :一共 41 位,用来表示时间戳,单位是毫秒,可以支撑2 ^41 毫秒(约 69 年)2^41/1000*60*60*24*365 = 69年
> 第 42~52 位 :一共 10 位,工作机器id,一般用前 5 位表示机房ID,后 5 位表示机器ID,用于区分不同集群/机房的节点,10位的长度,可以表示1024个不同节点。
> 第 53~64 位 :一共12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大ID 数(2^12 =4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID,最大可以支持400w左右的并发量。
具体结构如下:
三、java实现雪花算法
package snow;
/**
* @author 杨树林
* @version 1.0
* @since 24/10/2023
*/
public class SnowFlake {
// 机房(数据中心)ID
private long datacenterId;
// 机器ID
private long workerId;
// 同一时间的序列号
private long sequence;
// 开始时间戳
private long twepoch = 1634393012000L;
// 机房ID所占的位数: 5个bit
private long datacenterIdBits = 5L;
// 机器ID所占的位数:5个bit
private long workerIdBits = 5L;
// 最大机器ID:5bit最多只能有31个数字,就是说机器id最多只能是32以内
// 最大:11111(2进制) --> 31(10进制)
private 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









