



 文章详细介绍了SpringBoot和SpringCloud的关系,重点讲解了SpringCloudEureka在微服务中的服务治理作用,包括服务注册、发现和续约机制。接着,阐述了Ribbon作为客户端负载均衡工具的工作原理和使用,包括RestTemplate的负载均衡能力和Ribbon的几种负载均衡算法。最后,通过代码示例展示了如何在SpringBoot应用中集成和使用Eureka和Ribbon进行服务调用。
文章详细介绍了SpringBoot和SpringCloud的关系,重点讲解了SpringCloudEureka在微服务中的服务治理作用,包括服务注册、发现和续约机制。接着,阐述了Ribbon作为客户端负载均衡工具的工作原理和使用,包括RestTemplate的负载均衡能力和Ribbon的几种负载均衡算法。最后,通过代码示例展示了如何在SpringBoot应用中集成和使用Eureka和Ribbon进行服务调用。
由springBoot谈及springCloud
Spring Boot可以离开Spring Cloud独立使用开发项目,但是Spring Cloud离不开Spring Boot,属于依赖的关系。
Spring Cloud Eureka
1.Spring Cloud Eureka的概述
Spring Cloud Eureka实现微服务架构中的服务治理功能,使用 Netflix Eureka 实现服务注册与发现,包含客户端组件和服务端组件。服务治理是微服务架构中最为核心和基础的模块。
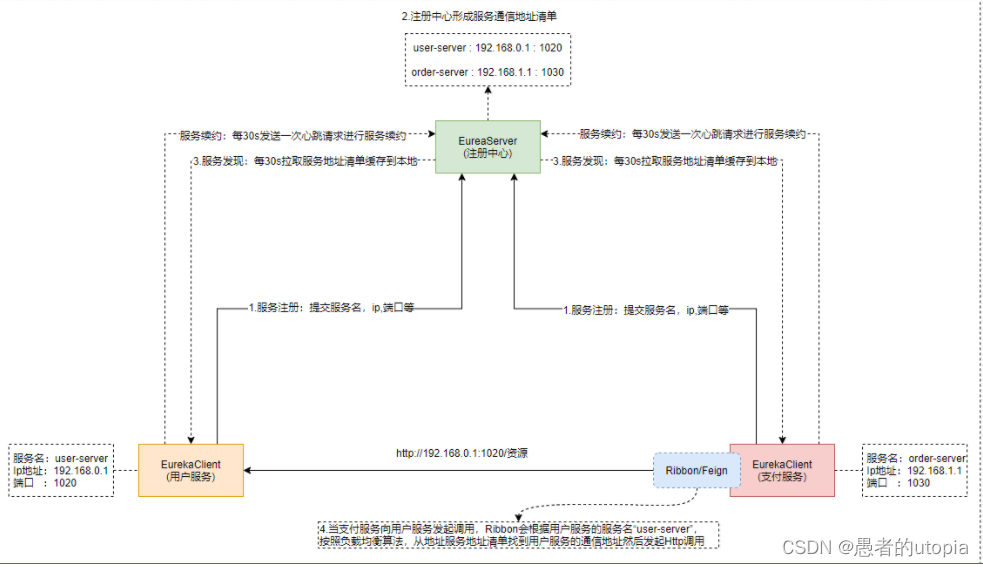
Eureka 服务端就是服务注册中心。Eureka 客户端用于处理服务的注册和发现。客户端服务通过注解和参数配置的方式,嵌入在客户端应用程序的代码中, 在应用程序运行时,Eureka客户端向注册中心注册自身提供的服务并周期性地发送心跳来更新它的服务租约。同时,它也能从服务端查询当前注册的服务信息并把它们缓存到本地并周期性地刷新服务状态。Eureka就是用来管理微服务的通信地址清单的,有了Eureka之后我们通过服务的名字就能实现服务的调用。
2.Eureka的工作原理
服务注册
提交自己的服务名称、IP、Port注册到注册中心
服务发现
每三十秒拉服务地址清单缓存到本地
服务续约
每三十秒发送一次心跳,保证让注册中心知道自己还活着
服务下线
注册中心检测到服务已经死了,并且满足剔除条件那么就会将服务的所有信息进行清除
3.代码实战
- SpringBoot专注于快速方便的开发单个个体微服务。
- SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务整合并管理起来,为各个微服务之间提供,配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等集成服务
- SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系。
- SpringBoot专注于快速、方便的开发单个微服务个体,SpringCloud关注全局的服务治理框架。
服务注册:在微服务架构中往往会有一个注册中心,每个微服务都会向注册中心去注册自己的地址及端口信息,注册中心维护着服务名称与服务实例的对应关系。每个微服务都会定时从注册中心获取服务列表,同时汇报自己的运行情况,这样当有的服务需要调用其他服务时,就可以从自己获取到的服务列表中获取实例地址进行调用。
服务发现:服务间的调用不是通过直接调用具体的实例地址,而是通过服务名发起调用。调用方需要向服务注册中心咨询服务,获取服务的实例清单,从而访问具体的服务实例。
操作过程如下:
添加依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
启动服务注册中心功能:
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication
{
public static void main( String[] args )
{
SpringApplication.run(EurekaServerApplication.class);
}
}在配置文件application.yml中添加Eureka注册中心的配置:
server:
port: 10010
eureka:
instance:
hostname: localhost
client:
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
server:
enable-self-preservation: false #关闭自我保护运行EurekaServerApplication,访问地址http://localhost:10010/可以看到Eureka注册中心的界面。
Spring Cloud Ribbon
Spring Cloud Ribbon 是基于HTTP和TCP的客户端负载均衡工具,基于Netflix Ribbon实现。Spring Cloud Ribbon 会将REST请求转换为客户端负载均衡的服务调用。
在客户端节点会维护可访问的服务器清单,服务器清单来自服务注册中心,通过心跳维持服务器清单的健康性。
1.RestTemplate
基本的微服务环境搭建,由 provider 提供服务, consumer 通过 DiscoveryClient 先去 eureka 上获取 provider 的服务的地址,获取到地址之后再去调用相关的服务。在服务的调用过程中,使用到了一个工具,叫做 RestTemplate,RestTemplate 是由 Spring 提供的一个 HTTP 请求工具。
RestTemplate 是从 Spring3.0 开始支持的一个 HTTP 请求工具,它提供了常见的REST请求方案的模版,例如 GET 请求、POST 请求、PUT 请求、DELETE 请求以及一些通用的请求执行方法 exchange 以及 execute。RestTemplate 继承自 InterceptingHttpAccessor 并且实现了 RestOperations 接口,其中 RestOperations 接口定义了基本的 RESTful 操作,这些操作在 RestTemplate 中都得到了实现。接下来我们就来看看这些操作方法的使用。
使用@LoadBalanced注解赋予RestTemplate负载均衡的能力。
@Bean//方法名称必须是容器名称
@LoadBalanced//负载均衡能力
public RestTemplate restTemplate(){
return new RestTemplate();
}创建OrderController,注入RestTemplate:
@Autowired
private RestTemplate restTemplate;
@GetMapping("/{id}")
public User getOrder(@PathVariable("id") Long id) {
return restTemplate.getForObject("http://user-server/user/" + id, User.class);
}2.为什么要使用Ribbon
假设我们有很多服务(设有集群),并且服务端都已经注册到Eureka中,接下来就是客户端调用服务。那么问题来了,我们该怎么调用?理论上来说写上服务的地址确实是可以调用的。但是同一个服务如果有多个服务器,即同一个服务设有集群,那么我们又该调用哪个。你如果把地址写死,那么设置集群便没有了意义。我们必须有一种策略,让它能自动选择合适的服务去调用。Ribbon就是解决这个问题而生的!
3.什么是Ribbon
Spring Cloud Ribbon是一个基于HTTP和TCP的客户端负载均衡工具,它基于Netflix Ribbon实现。通过Spring Cloud的封装,可以让我们轻松地将面向服务的REST模版请求自动转换成客户端负载均衡的服务调用。Spring Cloud Ribbon虽然只是一个工具类框架,它不像服务注册中心、配置中心、API网关那样需要独立部署,但是它几乎存在于每一个Spring Cloud构建的微服务和基础设施中。因为微服务间的调用,API网关的请求转发等内容,实际上都是通过Ribbon来实现的,包括后续我们将要介绍的Feign,它也是基于Ribbon实现的工具。所以,对Spring Cloud Ribbon的理解和使用,对于我们使用Spring Cloud来构建微服务非常重要。
4.Ribbon怎么用?
开启客户端负载均衡调用:
简而言之就是
- 服务提供者启动多个服务实例注册到服务注册中心;
- 服务消费者直接通过调用被@LoadBalanced 注解修饰过的RestTemplate 来实现面向服务的接口调用。
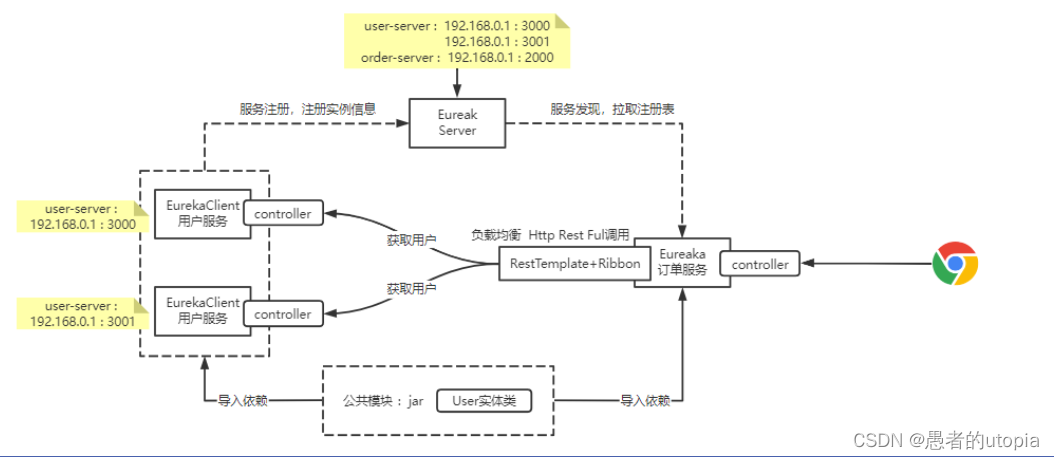
我们将user-server(用户服务)做集群处理,增加到2个节点(注意:两个user-server(用户服务)的服务名要一样,ip和端口不一样),在注册中心的服务通信地址清单中user-server(用户服务)这个服务下面会挂载两个通信地址 。 order-server(订单服务)会定时把服务通信地址清单拉取到本地进行缓存, 那么当order-server(订单服务)在向user-server(用户服务)发起调用时,需要指定服务名为 user-server(用户服务);那么这个时候,ribbon会根据user-server(用户服务)这个服务名找到两个order-server的通信地址 , 然后ribbon会按照负载均衡算法(默认轮询)选择其中的某一个通信地址,发起http请求实现服务的调用
Ribbon集成官方文档:16. Client Side Load Balancer: Ribbon
5.代码实例
1.提供者user-server(用户服务)集群
添加依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>cn.hc</groupId>
<artifactId>springcloud-netflix-poj-user</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>修改 application.yml
server:
port: 10030 # user服务端口号
eureka:
client:
serviceUrl: # Eureka客户端配置,指向注册中心地址
defaultZone: http://localhost:10010/eureka/
instance: # 打开IP注册
instance-id: ${spring.application.name}:${server.port} # 设置实例名称
prefer-ip-address: true # 开启IP注册
# 指定服务名称,此服务下的集群所有服务都叫此服务名
spring:
application:
name: user-server修改启动类:
@SpringBootApplication
// 表名此服务是Eure客户端,开启Eureka客户端功能,不加此注解默认也开启客户端功能
@EnableEurekaClient
public class UserServerApplication
{
public static void main( String[] args )
{
SpringApplication.run(UserServerApplication.class,args);
}
}修改controller:
@RestController
@RequestMapping("/user")
public class UserController {
@Value("${server.port}")
private String port;
@GetMapping("/{id}")
public User getUser(@PathVariable("id") Long id) {
return new User(id,"天生我才","会须当饮三百杯" + port);
}
}2.消费者Order-server集成Ribbon
添加依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>cn.hc</groupId>
<artifactId>springcloud-netflix-poj-user</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
</dependencies>修改 application.yml
server:
port: 10020 # user服务端口号
eureka:
client:
serviceUrl: # Eureka客户端配置,指向注册中心地址
defaultZone: http://localhost:10010/eureka/
instance: # 打开IP注册
instance-id: ${spring.application.name}:${server.port} # 设置实例名称
prefer-ip-address: true # 开启IP注册
# 指定服务名称,此服务下的集群所有服务都叫此服务名
spring:
application:
name: order-server修改启动类:
@SpringBootApplication
// 表名此服务是Eure客户端,开启Eureka客户端功能,不加此注解默认也开启客户端功能
@EnableEurekaClient
public class OrderServerApplication
{
public static void main(String[] args) {
SpringApplication.run(OrderServerApplication.class,args);
}
@Bean//方法名称必须是容器名称
@LoadBalanced//负载均衡能力
public RestTemplate restTemplate(){
return new RestTemplate();
}
}修改controller:
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/{id}")
public User getOrder(@PathVariable("id") Long id) {
return restTemplate.getForObject("http://user-server/user/" + id, User.class);
}
}6.负载均衡算法
当一台机器不能承受访问压力时,我们大多会通过横向增加两台、或者多台服务器,来共同承担访问压力,来极大的降低后端的访问压力,提升用户的访问性能。
但是,从一台扩展到多台服务器后,如何将客户端的流量、分发到具体的服务器呢?是通过服务器 1 ?还是服务器 2?这就需要我们下面谈到的负载均衡算法。
1.负载均衡算法的类型
我们常用的负载均衡算法有5种,轮询 ,加权随机,随机,加权轮询法,源地址哈希法。
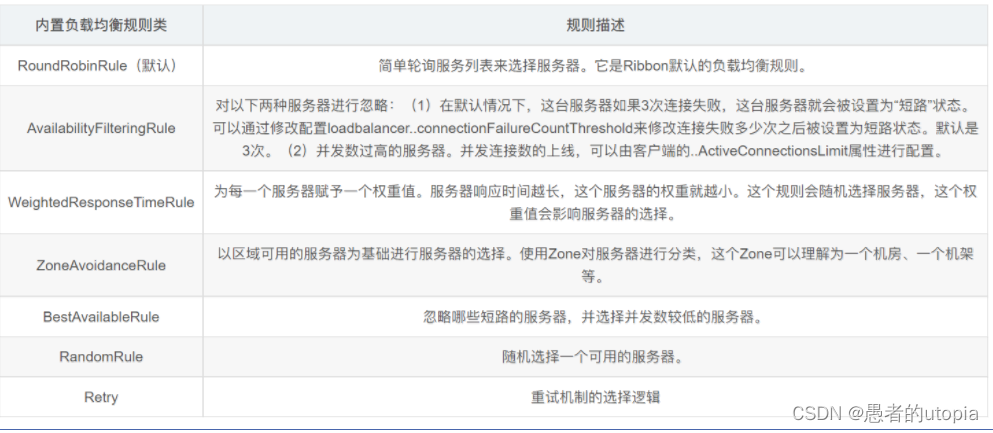
1.1 轮询
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
适合场景:适合于应用服务器硬件都相同的情况。
底层代码:
@SuppressWarnings({"RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE"})
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
} else {
Server server = null;
while(server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int index = this.chooseRandomInt(serverCount);
server = (Server)upList.get(index);
if (server == null) {
Thread.yield();
} else {
if (server.isAlive()) {
return server;
}
server = null;
Thread.yield();
}
}
return server;
}
}
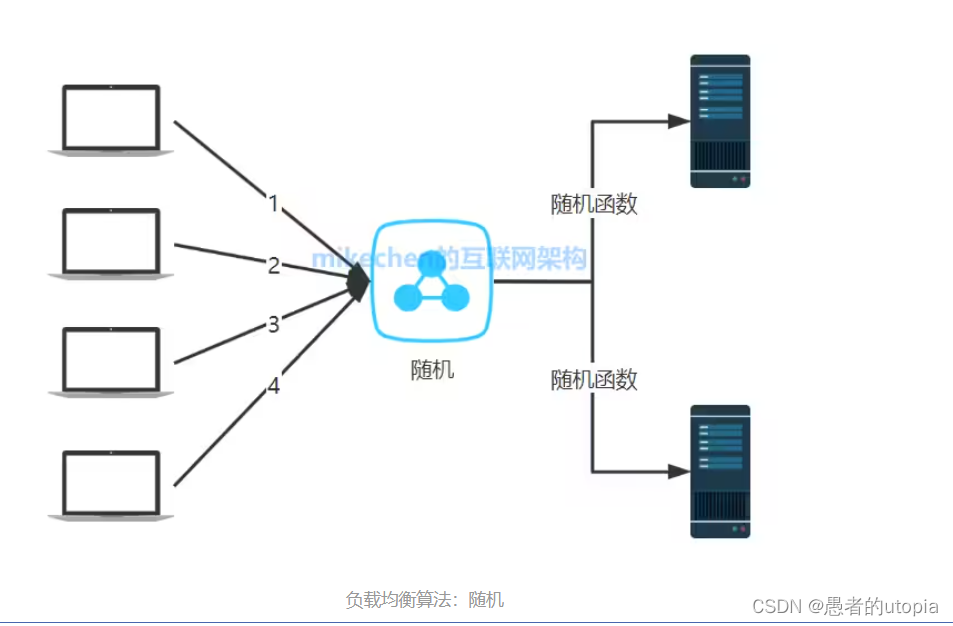
1.2 随机
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
底层代码:
@SuppressWarnings({"RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE"})
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
} else {
Server server = null;
while(server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();
List<Server> allList = lb.getAllServers();
int serverCount = allList.size();
if (serverCount == 0) {
return null;
}
int index = this.chooseRandomInt(serverCount);
server = (Server)upList.get(index);
if (server == null) {
Thread.yield();
} else {
if (server.isAlive()) {
return server;
}
server = null;
Thread.yield();
}
}
return server;
}
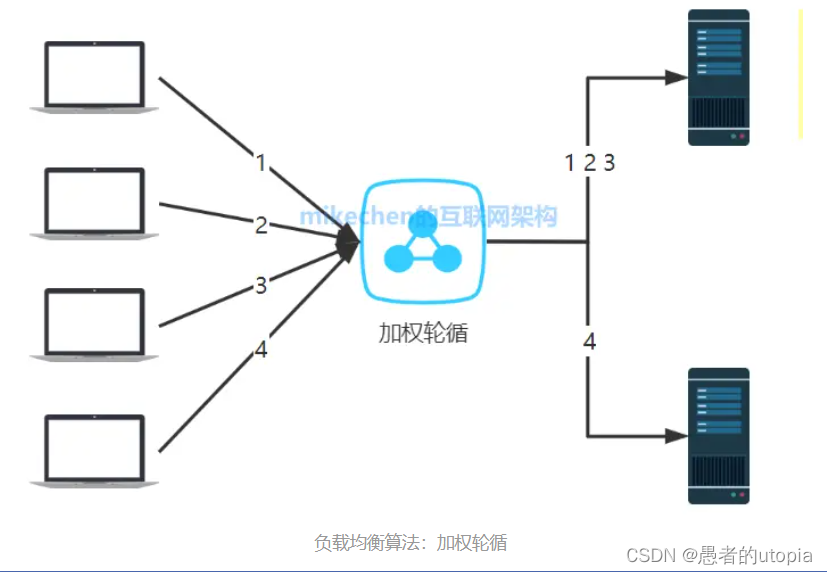
}1.3 加权轮询
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
底层代码:
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
public class TestWeightRobin {
// 1.map, key-ip,value-weight
static Map<String,Integer> ipMap= new HashMap<>();
static {
ipMap.put("192.168.13.1",1);
ipMap.put("192.168.13.2",2);
ipMap.put("192.168.13.3",4);
}
Integer pos=0;
public String WeightRobin(){
Map<String,Integer> ipServerMap=new ConcurrentHashMap<>();
ipServerMap.putAll(ipMap);
Set<String> ipSet=ipServerMap.keySet();
Iterator<String> ipIterator=ipSet.iterator();
//定义一个list放所有server
ArrayList<String> ipArrayList=new ArrayList<String>();
//循环set,根据set中的可以去得知map中的value,给list中添加对应数字的server数量
while (ipIterator.hasNext()){
String serverName=ipIterator.next();
Integer weight=ipServerMap.get(serverName);
for ( int i = 0;i < weight ;i++){
ipArrayList.add(serverName);
}
}
String serverName=null;
if (pos>=ipArrayList.size()){
pos=0;
}
serverName=ipArrayList.get(pos);
//轮询+1
pos ++;
return serverName;
}
public static void main(String[] args) {
TestWeightRobin testWeightRobin=new TestWeightRobin();
for ( int i =0;i<10;i++){
String server=testWeightRobin.WeightRobin();
System.out.println(server);
}
}
}
1.4 加权随机
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
底层代码:
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
public class TestRobinRandom {
// 1.定义map, key-ip,value-weight
static Map<String,Integer> ipMap= new HashMap<>();
static {
ipMap.put("192.168.13.1",1);
ipMap.put("192.168.13.2",2);
ipMap.put("192.168.13.3",4);
}
public String RobinRandom(){
Map<String,Integer> ipServerMap=new ConcurrentHashMap<>();
ipServerMap.putAll(ipMap);
Set<String> ipSet=ipServerMap.keySet();
Iterator<String> ipIterator=ipSet.iterator();
//定义一个list放所有server
ArrayList<String> ipArrayList=new ArrayList<String>();
//循环set,根据set中的可以去得知map中的value,给list中添加对应数字的server数量
while (ipIterator.hasNext()){
String serverName=ipIterator.next();
Integer weight=ipServerMap.get(serverName);
for ( int i=0;i<weight;i++){
ipArrayList.add(serverName);
}
}
//循环随机数
Random random=new Random();
//随机数在list数量中取(1-list.size)
int pos=random.nextInt(ipArrayList.size());
String serverNameReturn= ipArrayList.get(pos);
return serverNameReturn;
}
public static void main(String[] args) {
TestRobinRandom testRobinRandom=new TestRobinRandom();
for ( int i =0;i<10;i++){
String server=testRobinRandom.RobinRandom();
System.out.println(server);
}
}
}
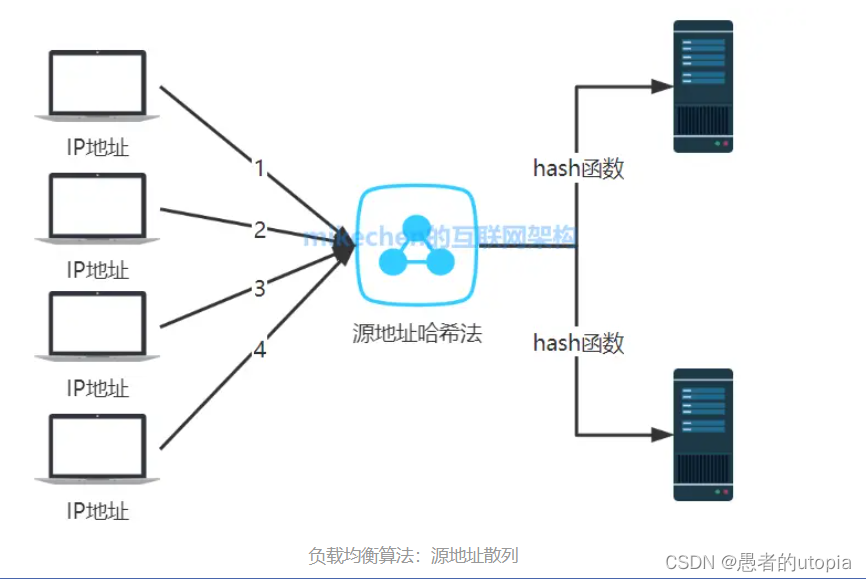
1.5 源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
底层代码:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ConcurrentHashMap;
public class ipHash {
// 1.定义map, key-ip,value-weight
static Map<String,Integer> ipMap= new HashMap<>();
static {
ipMap.put("192.168.13.1",1);
ipMap.put("192.168.13.2",2);
ipMap.put("192.168.13.3",4);
}
public String ipHash(String clientIP){
Map<String,Integer> ipServerMap=new ConcurrentHashMap<>();
ipServerMap.putAll(ipMap);
// 2.取出来key,放到set中
Set<String> ipset=ipServerMap.keySet();
// 3.set放到list,要循环list取出
ArrayList<String> iplist=new ArrayList<String>();
iplist.addAll(ipset);
//对ip的hashcode值取余数,每次都一样的
int hashCode=clientIP.hashCode();
int serverListsize=iplist.size();
int pos=hashCode%serverListsize;
return iplist.get(pos);
}
public static void main(String[] args) {
ipHash iphash=new ipHash();
String servername= iphash.ipHash("192.168.21.2");
System.out.println(servername);
}
}
2. 如何使用负载均衡算法
Ribbon可以进行全局负载均衡算法配置,也可以针对于具体的服务做不同的算法配置。同时可以使用注解方式和yml配置方式来实现上面两种情况。
2.1 yml配置方式
配置全局Ribbon算法
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule配置某个服务的Ribbon算法
user-server:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule2.2 注解全局配置
//负载均衡算法
@Bean
public RandomRule randomRule(){
return new RandomRule();
}测试
重启订单服务,访问http://localhost:1030/order/1 ,发送多次请求应该可以看到结果中的端口随机变动。


















 4666
4666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











