




环境描述
首先来说下本文的背景信息,主要是从原先用了多年的 NebulaGraph v1.0.0 版本升级到悦数图数据库的 v3.6.0 版本。下面是本文可能会用到的前提信息:
- 当前 NebulaGraph 版本:v1.0.0
- 目标悦数图数据库版本:v3.6.0
相信有很多和我类似用着非最新发行版的企业用户,因为为了保障业务的稳定运行,依旧用着 v2.x.0 版本,或者是和我们一样用着 v1.0.0 版本。所以,很多人会问:升级?为什么要升级呢?
这是我的答案:v3.6.0 版本,或者说最新发行版,会比 v1.0.0 版本具有更高的可维护性和稳定性、更完善的周边生态。此外 NebulaGraph v1.0.0 版本出问题基本上很难得到解决,另外扩缩容比较麻烦。
升级需要考虑的点
和许多依旧用着老版本的用户一样,我们其实也是做了一段时间的挣扎选择了升级。下面是我们想到的升级需要考虑到的点:
1.nGQL 的兼容性;
2.原地升级 or 导出导入的方式?这里我们测试过,原地升级经测试不可用,而且还会影响在线业务,风险大;
3.如何保证升级不影响线上的业务;
4.如何处理升级时产生的增量数据;
5.升级后如何数据一致性比对;
6.如何进行新老数据库替换;
如果要排个优先级的话,第 3,5,6 相比其他几点会更重要。
升级方案
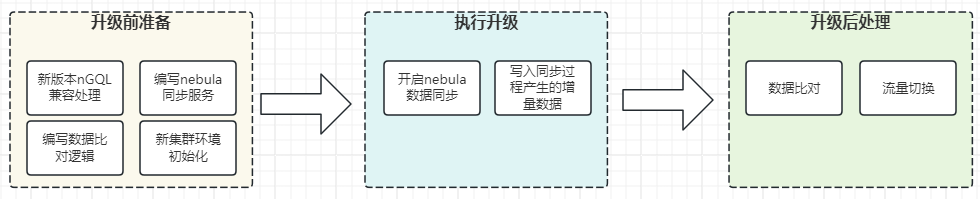
这是大致的升级方案,大体分为三个部分:
升级前准备
有些准备工作需要完成:
1.收集、整合业务线相关的所有 nGQL 并进行 v3.6.0 版本测试,修改 nGQL 以兼容 v3.6.0 版本悦数图数据库。
2.编写 nebula 同步服务,这里无法使用 nebula-spark-connector 进行同步,因为 nebula 版本跨的太大了。
3.编写数据流量比对逻辑。
4.搭建悦数图数据库 v3.6.0 版本新集群环境,这里可以临时关闭自动 Compaction 功能,来加快写入速度。
注意:这里并非在原来的业务应用上进行更新,而是复制一个新的出来,因为同一个应用无法兼容两套不同版本的 nebula。
执行升级
我们这里是借助了 MQ(消息队列,Message Queue)来中间处理了下数据。涉及到 MQ 的步骤有:
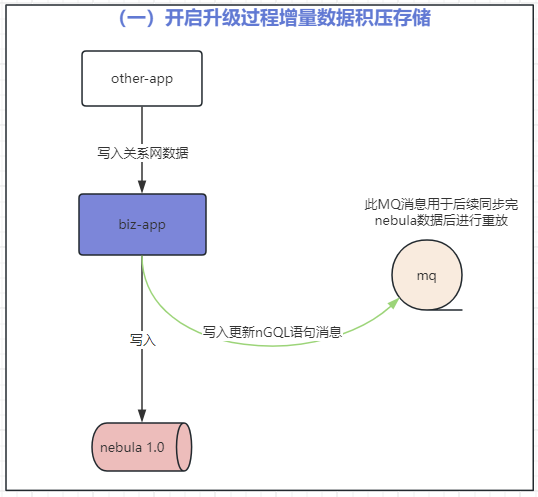
1.开启同步过程增量数据写入 MQ 进行积压;
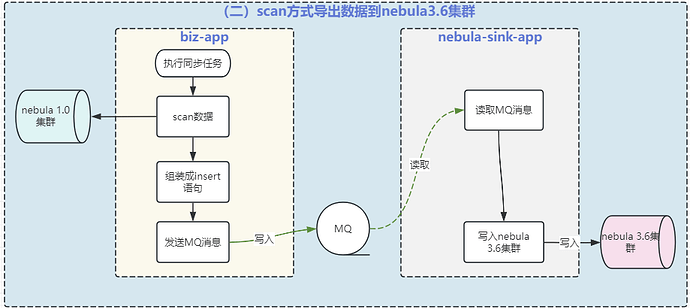
2.开启 nebula 数据同步,应用 A 从 nebula v1.0.0 中读取出来发送到 MQ,然后应用 B 消费 MQ 消息写入到 nebula v3.6.0;
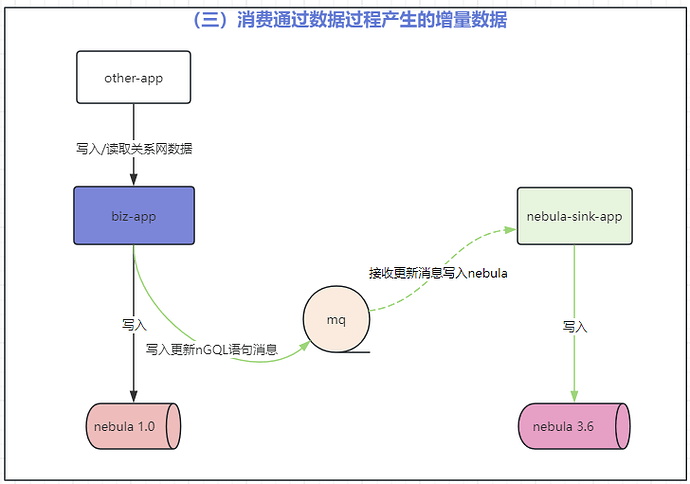
3.同步完毕后将 MQ 中积压的增量数据写入悦数图数据库 v3.6.0;
升级后处理
这里再简述下升级之后需要做的操作:
1.数据一致性比对,通过流量复制的方式发送到新的应用上进行重放结果比对;
2.逐步切流量到新悦数图数据库 v3.6.0 集群;
内核升级的详细设计
名词说明:
-
biz-app:业务应用 App,作用连接 nebula v1.0.0 进行图数据操作;
-
biz-app-new:biz-app 的复制版本,只不过改成了连接 v3.6.0 版本悦数图数据库,并更新 nGQL 以兼容悦数图数据库 v3.6.0;
-
nebula-sink-app:用于接收悦数图数据库v3.6.0 版本的更新语句消息,并写入到悦数图数据库 v3.6.0 集群;
第一步:开启增量数据写入 MQ 积压
第二步:同步 nebula v1.0.0 数据到 v3.6.0 集群
第三步:同步完毕后消费增量数据
第四步:数据一致性比对
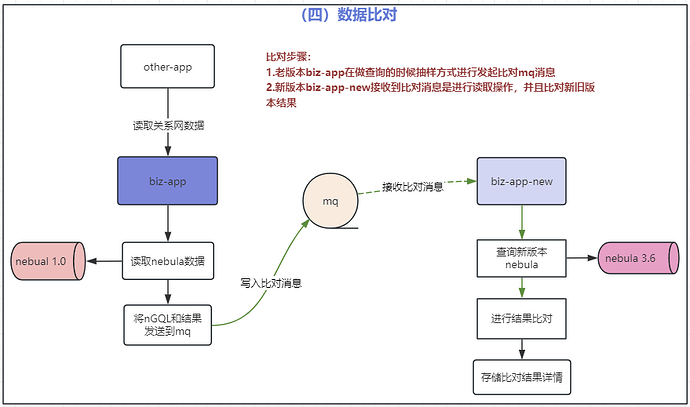
第五步:悦数图数据库v3.6.0 集群切流

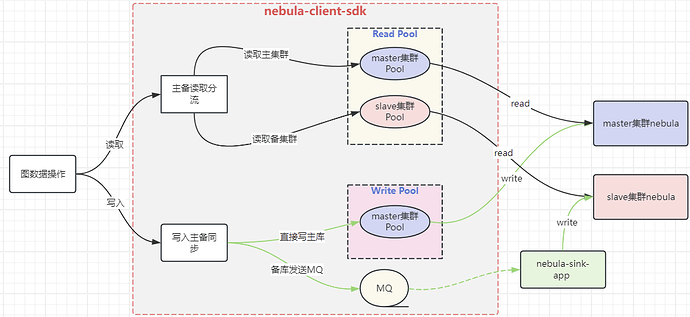
yueshu-client v3.6.0 版本 SDK 改造
本次客户端的改造,主要是支持下面功能:主备写入同步、主备读取分流、读写 SessionPool 隔离、连接池监控、nGQL 执行监控。
遇到的问题以及解决方案
当然升级不是一步到位,我们也遇到了不少的问题。这里罗列了几个印象深刻的错误:
-
导出 Timestamp 属性字段报错
-
无法导出多版本数据(Schema 发生更改)
-
每次 Scan 中断只能从头开始,无法接着上次的 cursor 继续导出
-
指定扫描单个 Edge 或者 Tag 出现磁盘 IO 使用率100%(见:nebula v1.0.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









