




 这篇博客探讨了如何使用深度优先搜索(DFS)前序遍历、后序遍历和广度优先搜索(BFS)来解决比较两个二叉树是否相同的算法问题。作者通过三种不同的方法展示了实现细节,包括递归和迭代的方式,并指出在解决树相关问题时,遍历策略并不局限于明确的树遍历题目,而是可以灵活运用到各种场景中。
这篇博客探讨了如何使用深度优先搜索(DFS)前序遍历、后序遍历和广度优先搜索(BFS)来解决比较两个二叉树是否相同的算法问题。作者通过三种不同的方法展示了实现细节,包括递归和迭代的方式,并指出在解决树相关问题时,遍历策略并不局限于明确的树遍历题目,而是可以灵活运用到各种场景中。
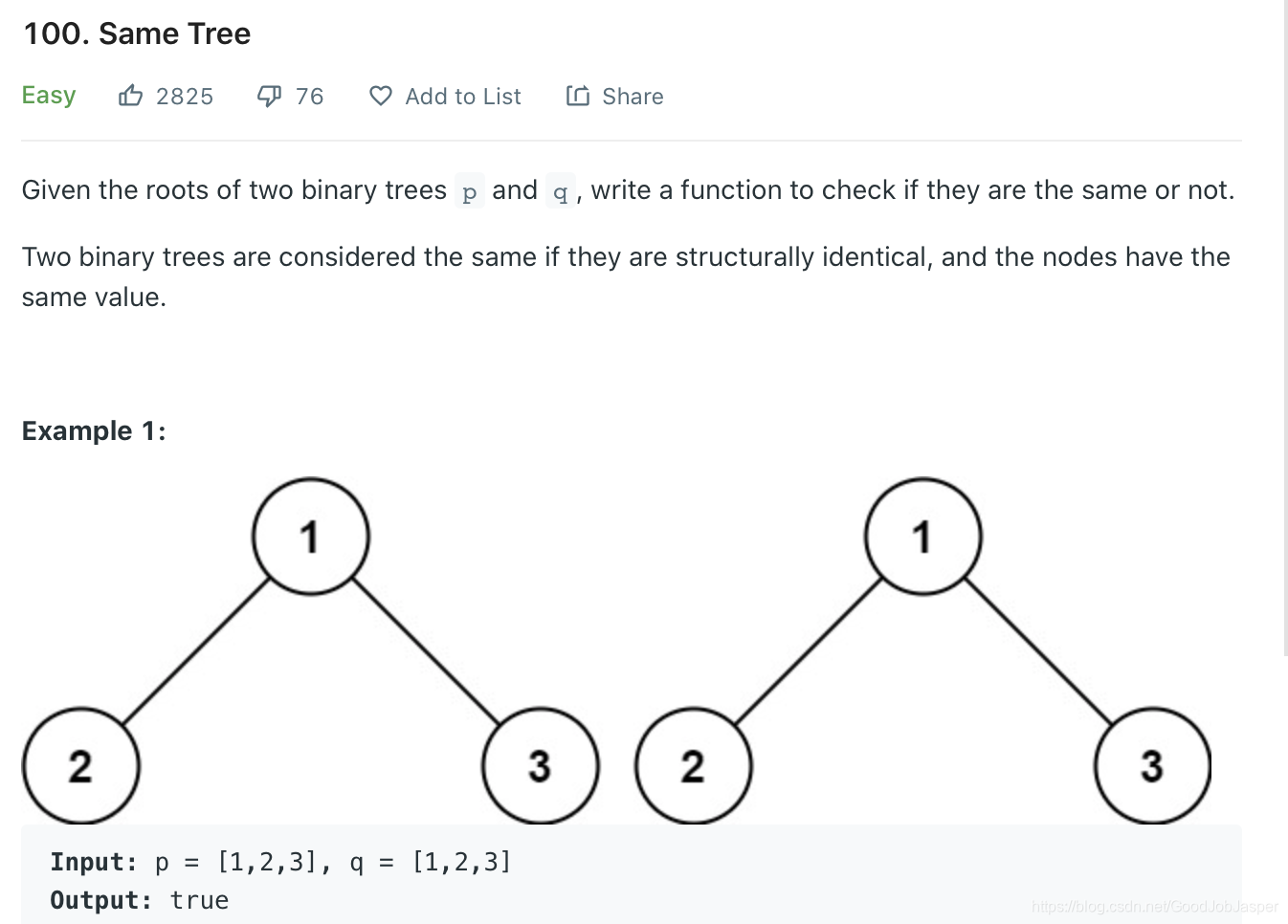
方法1: 我第一反应是用dfs-preorder来做,后来发现错了,dfs-preorder只能判断一个唯一的bst,可是这题是bt。但是稍微改一下就可以适用于这道题目了。实际上这道题不需要一定用preorder来做,inorder,postorder都行。一开始我认为inorder不行,是因为inorder不能用来判断一个唯一的bst,可是这题是bt,所以无所谓了,用哪种traversal都行了就。时间复杂n,空间复杂h。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();
dfsPreorder(p, list1);
dfsPreorder(q, list2);
return list1.equals(list2);
}
public void dfsPreorder(TreeNode root, List<Integer> list){
if(root == null) {
list.add(10001);
return;
}
list.add(root.val);
dfsPreorder(root.left, list);
dfsPreorder(root.right, list);
}
}
方法2: recursion。其实也能叫做dfs-preorder-recursion。时间复杂n,空间复杂h。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
if(p == null && q == null) return true;
if(p == null ^ q == null) return false;
if(p.val != q.val) return false;
return isSameTree(p.left, q.left) && isSameTree(p.right, q.right);
}
}
方法3: bfs-iteration-one queue。时间复杂n,空间复杂n。
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
Queue<TreeNode> queue = new LinkedList<>();
if (p == null && q == null)
return true;
else if (p == null || q == null)
return false;
if (p != null && q != null) {
queue.offer(p);
queue.offer(q);
}
while (!queue.isEmpty()) {
TreeNode first = queue.poll();
TreeNode second = queue.poll();
if (first == null && second == null)
continue;
if (first == null || second == null)
return false;
if (first.val != second.val)
return false;
queue.offer(first.left);
queue.offer(second.left);
queue.offer(first.right);
queue.offer(second.right);
}
return true;
}
}
总结:
- 前几天traversal题目做多了,以为只有题干上明确写了traversal的题目才会用到dfs,bfs。其实要明白并不是只有traversal的题目会用到dfs,bfs,其是很多题目是比较隐晦的要你去traversal a tree。

















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









