



 本文介绍了NoSQL数据库的概念、特点以及与关系型数据库的对比,并深入探讨了HBase的物理架构、逻辑架构和其作为列存储数据库的特性。通过MapReduce和Sharding等技术,HBase提供了高扩展性和实时查询能力,适用于大数据场景。
本文介绍了NoSQL数据库的概念、特点以及与关系型数据库的对比,并深入探讨了HBase的物理架构、逻辑架构和其作为列存储数据库的特性。通过MapReduce和Sharding等技术,HBase提供了高扩展性和实时查询能力,适用于大数据场景。
安装hbase
把安装包拖进linux里面的opt目录下
########## 安装hbase ##########
// 解压安装包
tar -zxf hbase-1.2.0-cdh5.14.2.tar.gz
// 移动解压完成后的安装包
mv hbase-1.2.0-cdh5.14.2 soft/hbase120
cd /opt/soft/hbase120/conf
vi hbase-env.sh
1.export JAVA_HOME=/usr/local/softwave/jdk1.8.0_111
2.export HBASE_MANAGES_ZK=false //使用外部zookeeper
vi hbase-site.xml
vi /etc/profile
source /etc/profile
cd ../bin
hbase shell
!quit
start-hbase.sh
jps
hbase shell
hbase-site.xml
<property>
<name>>hbase.rootdir</name>
<value>hdfs://192.168.220.129:9000/hbase</value>
</property>
<!—单机模式不需要配置,分布式配置此项为true-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!—单机模式不需要配置 分布是配置此项为zookeeper指定的物理路径名-- >
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/cm/hbase</value>
</property>
配置文件
i.Export HBASE_HOME=/usr/local/softwave/hbase-1.2.1
ii.Export PATH=….:$HBASE_HOME/bin
NoSql
NoSQL:not only SQL,菲关系型数据库
- NoSQL是一个通用术语
指不遵循传统RDBMS模型的数据库
数据是菲关系的,且不使用SQL作为主要查询语句
解决数据库的可伸缩性和可用性问题
不针对原子性或一致性问题
为什么使用NoSQL
互联网的发展,传统关系型数据库存在瓶颈
高并发读写、高存储量、高可用性、高扩展性、低成本
NoSQL和关系型数据库对比
| 对比 | NoSQL | 关系型数据库 |
|---|---|---|
| 常用数据库 | Hbase、MongoDB、Redis | Oracle、DB2、MySQL |
| 存储格式 | 文档、键值对、图结构 | 表格式、行和列 |
| 存储规范 | 鼓励冗余 | 规范性、避免重复 |
| 存储扩展 | 横向扩展、分布式 | 纵向扩展(横向扩展有限) |
| 查询方式 | 结构化查询语言SQL | 非结构化查询 |
| 事务 | 不支持事务一致性 | 支持事务 |
| 性能 | 读写性能高 | 读写性能差 |
| 成本 | 简单易部署,开源,成本低 | 成本高 |
数据库三大范式:
第一范式(确保每列保持原子性)
是最基本的范式,如果数据库表中的所有字段值都是不可分割的原子值,就说明该数据库表满足了第一范式。
第二范式(确保表中的每列都和主键相关)
在第一范式的基础之上更进一层,第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言),也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据表中。
第三范式(确保每列都和主键直接相关,而不是间接相关)
需要确保数据表中的每一列数据都和主键之间相关,而不是间接相关。
NoSQL的特点
最终一致性
应用程序增加了维护一致性和处理事务等职责
冗余数据存储
- NoSQL != 大数据
NoSQL产品是为了帮助解决大数据存储问题
大数据不仅仅包含数据存储问题- hadoop
kafka
spark,etc
- hadoop
NoSQL和BI、大数据关系
- BI(Business Intelligence):商务智能
它是一套完整的解决方案
BI应用涉及模型,模型依赖于模式
BI主要支持标准SQL,对NoSQL支持弱于关系型数据库 - NoSQL和大数据相关性较高
通常大数据场景采用列存储数据库
如:HBase和Hadoop
NoSQL基本概念
三大基石:cap、base、最终一致性
Indexing(索引)、Query(查询)
MapReduce
Sharding
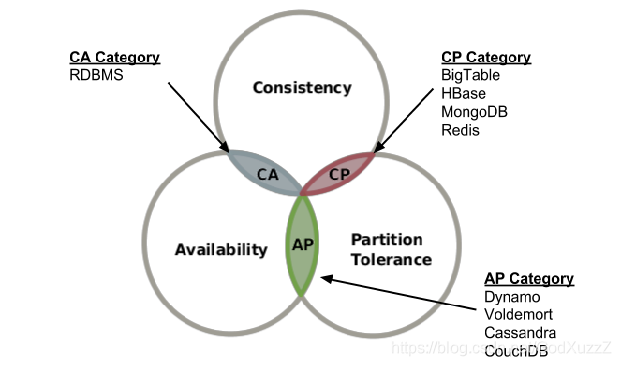
cap理论
一个分布式系统不能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Tolerance of network Partition)。鱼和熊掌不可兼得。
- Consistency(一致性):任何一个读操作总是能读取到之前完成的写操作结果,也就是在分布式环境中,多点的数据是一致的。
- Availability(可用性):每一个操作总是能在确定的时间内返回,也不是系统随时都是可用的。
- Partition Tolerance(分区容错性):在出现网络分区(如断网)的情况下,分离的系统也能正常运行。
NoSQL不保证“ACID”
事务管理的四个特性:
- 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 - 一致性(Consistency)
事务前后数据的完整性必须保持一致。 - 隔离性(Isolation)
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。 - 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
提供“最终一致性”
BASE
- Basically Availble(基本可用)
保证核心可用 - Soft-state(软状态)
状态可以有一段时间不同步 - Eventual Consistency(最终一致性)
系统经过一定时间后,数据最终能够达到一致的状态
核心思想是即使无法做到强一致性,但应用可以选择适合的方式达到最终一致性
最终一致性
最终结果保持一致性,而不是时时一致
如账户余额,库存量等数据需强一致性
如catalog等信息不需要强一致性
- Causal consistency(因果一致性)
Read-your-writes consistency
Session consistency
索引和查询
- Indexing(索引)
大多数NoSQL是按key进行索引
部分NoSQL允许二级索引
HBase使用HDFS,append-only- 批处理写入Logged
重新创建排序文件
- 批处理写入Logged
- Query(查询)
没有专门的查询语言,通常使用脚本语言查询
有些开始支持SQL查询
有些开始使用MapReduce代码查询
MapReduce、Sharding
- MapReduce
不是Hadoop的MapReduce,概念相关
可进行数据的处理查询 - Sharding(分片)
一种分区模式
可以复制分片- 有利于灾难恢复
NoSQL分类
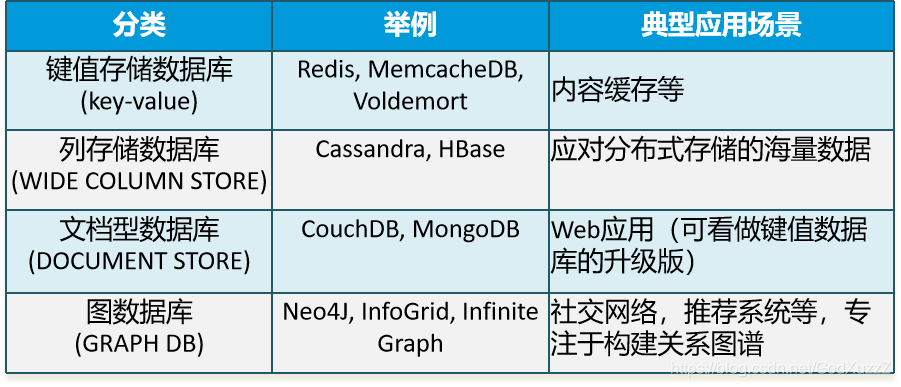
键值存储数据库
列存储数据库
文档型数据库
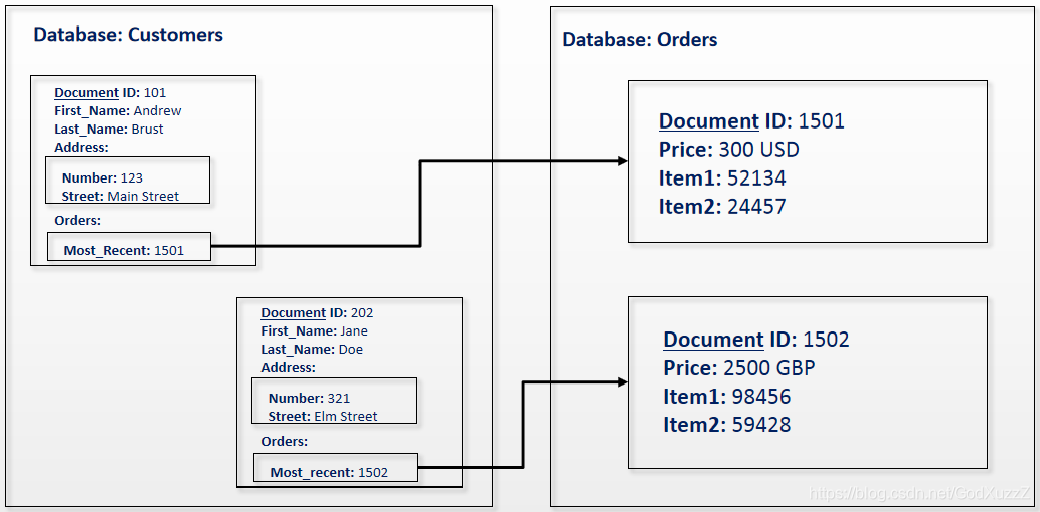
图数据库
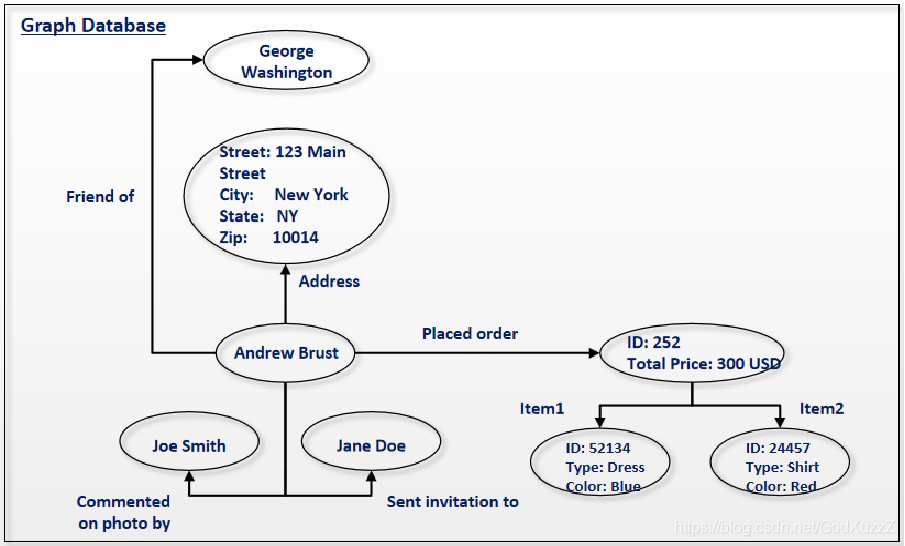
Hbase概述
- Hbase是一个领先的NoSQL数据库
是一个面向存储的数据库
是一个分布式hash map
基于Google Big Table论文
使用HDFS作为存储并利用其可靠性 - HBase特点
数据访问速度快,响应时间约2-20毫秒
支持随机读写,每个节点20k~100k+ops/s
可扩展性,可扩展到20,000+节点
Hbase物理架构
HBase实时查询的原理
HBase 的实时查询,可以认为是从内存中查询,一般响应时间在 1 秒内。
HBase 的机制是数据先写入到内存中,当数据量达到一定的量(如 128M),再写入磁盘中,
在内存中,是不进行数据的更新或合并操作的,只增加数据,
这使得用户的写操作只要进入内存中就可以立即返回,保证了 HBase I/O 的高性能。
采用Master/Slave架构
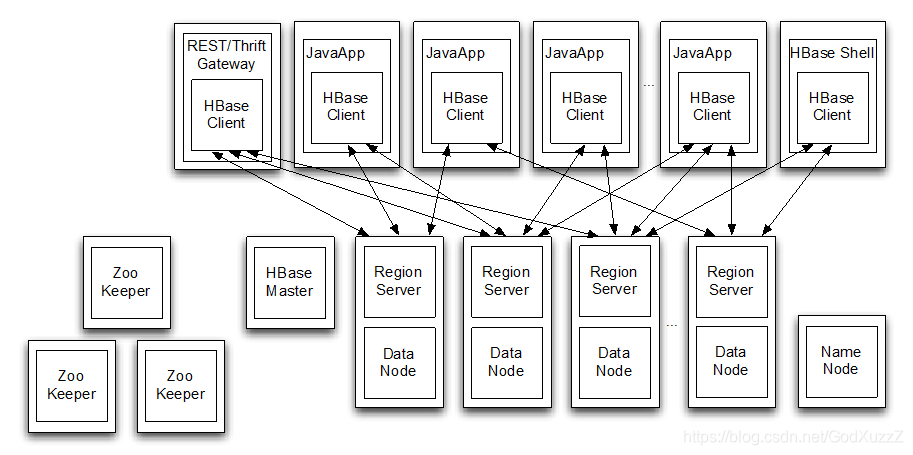
HMaster
HMaster的作用
是HBase集群的主节点,可以配置多个,用来实现HA
管理和分配Region
负责RegionServer的负载均衡
发现失效的RegionServer并重新分配其上的Region
RegionServer
RegionServer负责管理维护Region
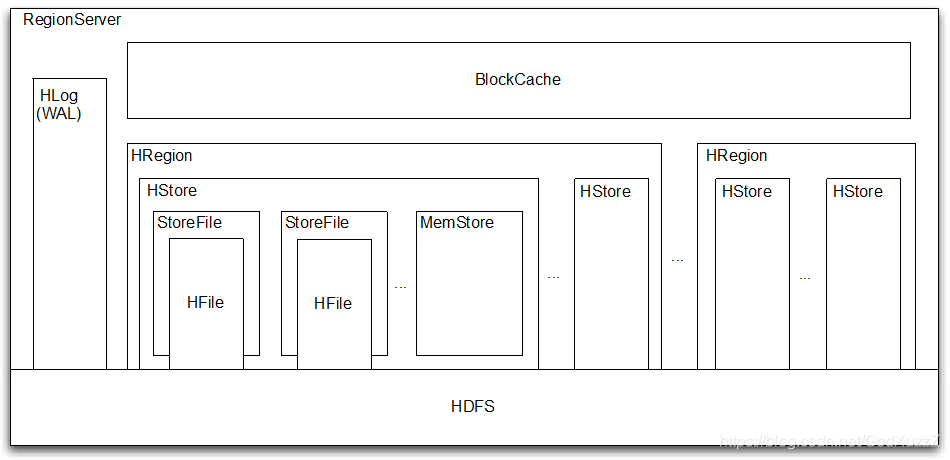
Region和Table
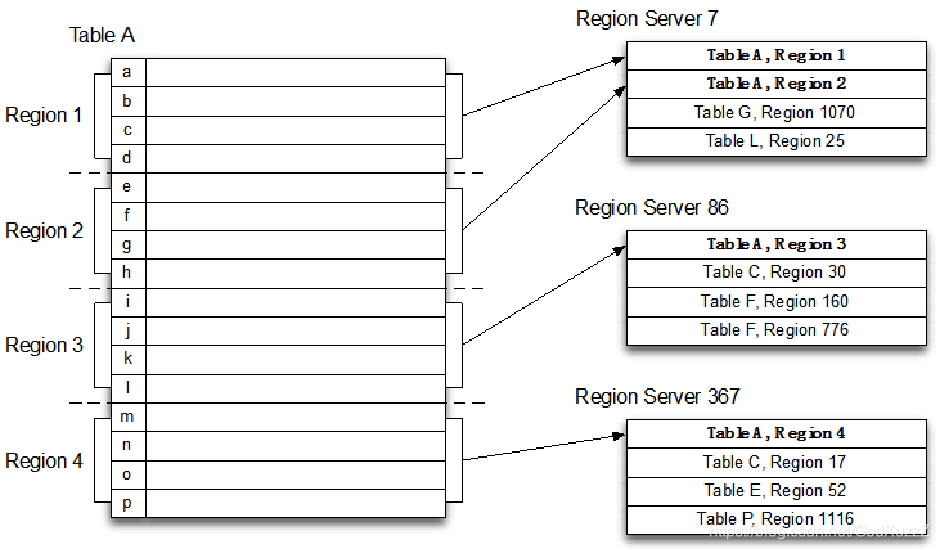
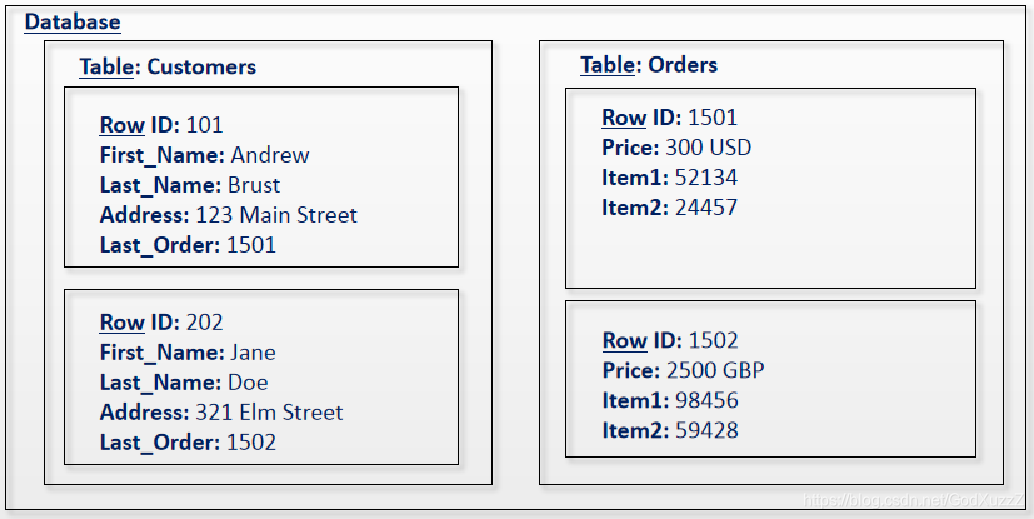
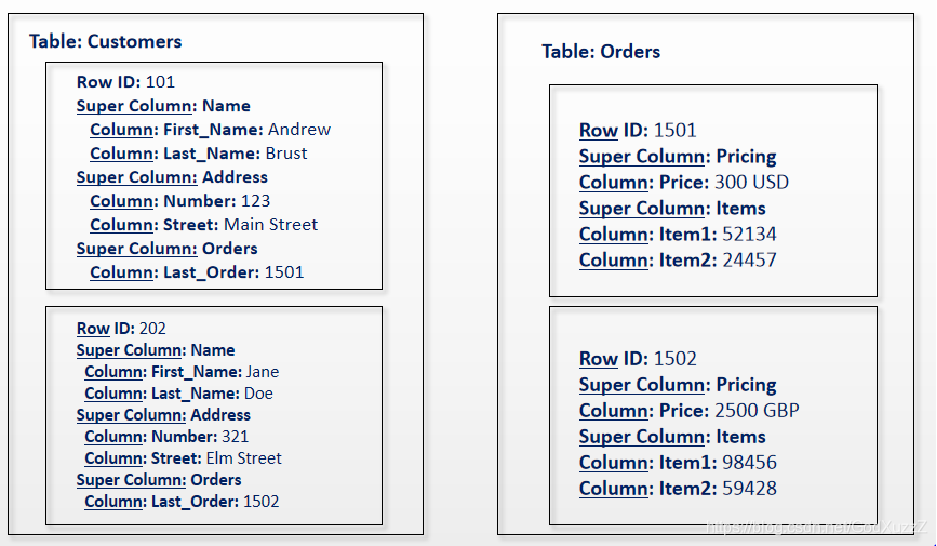
HBase逻辑架构-Row
- Rowkey(行键)是唯一的并己排序
- Schema可以定义何时插入记录
- 每个Row都可以定义自己的列,即使其他Row不适用
相关列定义为列簇 - 使用唯一时间戳维护多个Row版本
在不同版本中值类型可以不同 - HBase数据全部以字节存储
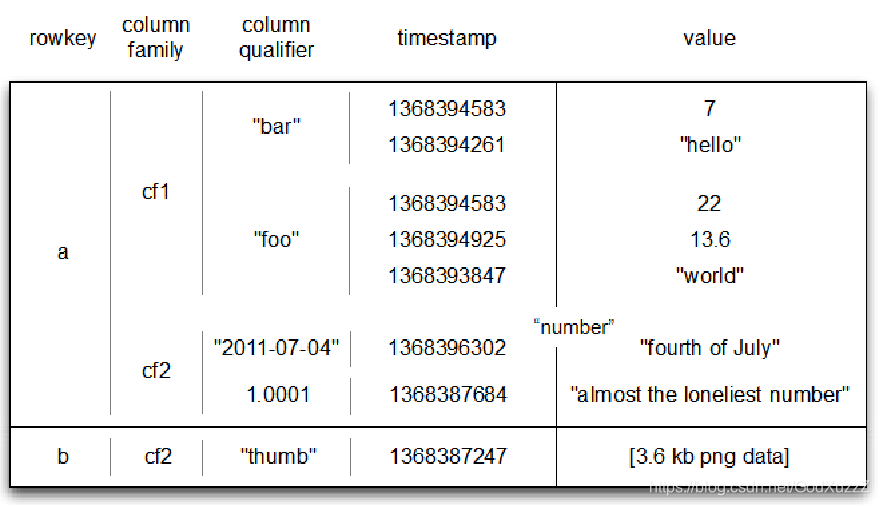
HBase数据管理
- 数据管理目录
系统目录表hbase:meta
存储元数据等
HDFS目录中的文件
Servers上的region实例 - HBase数据在HDFS上
可以通过HDFS进行修复File
修复路径:RegionServer->Table->Region->RowKey->列簇
HBase架构特点
- 强一致性
- 自动扩展
当Region变大会自动分割
使用HDFS扩展数据并管理空间 - 写恢复
使用WAL(Write Ahead Log) - 与Hadoop集成
HBase Shell
HBase Shell是一种操作HBase的交互模式
支持完整的HBase命令集

🌰
https://blog.youkuaiyun.com/vbirdbest/article/details/88236575
help 'list' // 查看命令list的使用描述
version // 查看版本号
status // 返回hbase集群的状态信息
whoami // 我是谁
table_help // 查看如何操作表
list // 列出hbase中存在的所有表
create // 创建表
create 'mydemo','base' // 创建表 mydemo表名 base列名
alter // 修改列簇
添加一个列簇:alter '表名','列簇名'
alter 'mydemo','external' // 添加列external
alter 'mydemo',{NAME=>'external',METHOD=>'delete'} // 删除列external
describe 'mydemo' // 查看表结构mydemo
exists 'mydemo' // 检查表是否存在
disable 'mydemo' // 禁用表
drop 'mydemo' // 先禁用表再删除
enable 'mydemo' // 开启表
describe_namespace 'default' // 查看表空间
create_namespace 'mydemo' // 创建表空间
create 'mydemo:userinfos','base' // 创建列簇base
create 'mydemo:scores','info' // 创建列簇info
list_namespace_tables 'mydemo' // 查看以mydemo为命名空间的表
put 'mydemo:userinfos','1','base:username','zhangsan' //表空间mydemo,表userinfos,'1'表示行键,列簇base,列username,列值zhangsan
alter 'mydemo:userinfos','externals' // 添加列簇externals
put 'mydemo:userinfos','1','externals:likes','player,eat' // 添加列likes
put 'mydemo:userinfos','2','base:username','lisi' // 添加列值lisi
put 'mydemo:userinfos','2','base:age','30' // 添加列age,列值30
scan 'mydemo:userinfos' // 全表扫描
scan 'mydemo:userinfos',{COLUMN=>'base'} // 扫描列簇base
get 'mydemo:userinfos','1' // 取值列簇
get 'mydemo:userinfos','1','externals' // 取值externals列簇
create 'mydemo:mytest',{NAME=>'base',VERSIONS=>3}
put 'mydemo:mytest','1','base:xxx','1'
put 'mydemo:mytest','1','base:xxx','11'
put 'mydemo:mytest','1','base:xxx','111'
get 'mydemo:mytest','1',{COLUMN=>'base',VERSIONS=>3}
put 'mydemo:mytest','1','base:xxx','1111'
取base列簇的三个值
get 'mydemo:mytest','1',{COLUMN=>'base',VERSIONS=>3}
取base列簇时间戳为1592806020017的值
get 'mydemo:mytest','1',{COLUMN=>'base',TIMESTAMP=>1592806020017}
put 'mydemo:userinfos','3','base:username','zhangsanfeng'
scan 'mydemo:userinfos'
https://www.cnblogs.com/mayidudu/p/6056772.html
show_filters 显示过滤器方式
create 'test1','lf','sf'
put 'test1', 'user1|ts1', 'sf:c1', 'sku1'
put 'test1', 'user1|ts2', 'sf:c1', 'sku188'
put 'test1', 'user1|ts3', 'sf:s1', 'sku123'
put 'test1', 'user2|ts4', 'sf:c1', 'sku2'
put 'test1', 'user2|ts5', 'sf:c2', 'sku288'
put 'test1', 'user2|ts6', 'sf:s1', 'sku222'
一个用户(userX),在什么时间(tsX),作为rowkey
scan 'test1'
找出值等于sku188的
scan 'test1',FILTER=>"ValueFilter(=,'binary:sku188')"
找出值包含88的
scan 'test1',FILTER=>"ValueFilter(=,'substring:88')"
scan 'mydemo:userinfos',FILTER=>"ColumnPrefixFilter('username') AND ValueFilter(=,'substring:zhang')" 找出修饰符为c2且值包含张的
scan 'test1',{STARTROW=>'user1|ts2'} // 从user1|ts2开始查
scan 'test1',{STARTROW=>'user1|ts2',FILTER=>"PrefixFilter('user1')"} // 从user1|ts2开始查user1为前缀的
count 'mydemo:userinfos'
scan 'mydemo:userinfos'
incr 'mydemo:userinfos','1','base:stuno',1 加入一个自增列,单元格的自增
scan 'mydemo:userinfos',{COLUMNS=>['base:username','base:age']} 查username、age列
scan 'mydemo:userinfos',{COLUMN=>'base',TIMESTAMP=>1592813668123}
scan 'mydemo:userinfos',{LIMIT=>2} 取前两行
scan 'mydemo:userinfos',{STARTROW=>'2',LIMIT=>2} 从第二行开始,取2,3两行

















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









