




 本文详细介绍了Hadoop大数据的特点,包括其4V特征和固有特征,并深入探讨了Hadoop的分布式计算、起源、优缺点、与传统数据库的对比。还解析了Hadoop架构中的HDFS、MapReduce、YARN以及Zookeeper的角色和功能。同时,讨论了HDFS的读写文件机制和副本策略,展现了Hadoop在大数据处理领域的核心优势。
本文详细介绍了Hadoop大数据的特点,包括其4V特征和固有特征,并深入探讨了Hadoop的分布式计算、起源、优缺点、与传统数据库的对比。还解析了Hadoop架构中的HDFS、MapReduce、YARN以及Zookeeper的角色和功能。同时,讨论了HDFS的读写文件机制和副本策略,展现了Hadoop在大数据处理领域的核心优势。
这里写目录标题
Hadoop大数据
大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。
大数据特征:
4V特征:
Volume(大数据量):90%的数据是过去两年产生
Velocity(速度快):数据增长速度快,时效性高
Variety(多样化):数据种类和来源多样化
结构化数据、半结构化数据、非结构化数据
Value(价值密度低):需要挖掘数据价值
固有特征:
时效性
不可变性
分布式计算
分布式计算将较大的数据分成小的部分进行处理
| 项目 | 传统分布式计算 | 新的分布式计算-Hadoop |
|---|---|---|
| 计算方式 | 将数据复制到计算节点 | 在不同数据节点并行计算 |
| 可处理数据量 | 小数据量 | 大数据量 |
| Cpu性能限制 | 受cpu限制较大 | 受单台设备限制小 |
| 提升计算能力 | 提升单台机器计算能力 | 扩展低成本服务器集群 |
hadoop
Hadoop是一个开源分布式系统架构
- 分布式文件系统HDFS——解决大数据存储
- 分布式计算框架MapReduce——解决大数据计算
- 分布式资源管理系统YARN
处理海量数据的架构首选
非常快的完成大数据计算任务
已发展成为一个Hadoop生态圈
起源
- Hadoop起源于搜索引擎Apache Nutch
- 创始人:Dong Cutting
2004年——最初版本实施
2008年——成为Apache顶级项目
- 创始人:Dong Cutting
- Hadoop发行版本
- 社区版:Apache Hadoop
Cloudera发行版:CDH
Hortonworks发行版:HDP
- 社区版:Apache Hadoop
优缺点
- 使用Hadoop的优点:
- 高扩展性、可伸缩
高可靠性
多副本机制。容错高
低成本
无共享架构
灵活,可存储任意数据类型
开源,社区活跃
- 高扩展性、可伸缩
与传统数据库对比
Hadoop与关系型数据库对比
| 项目 | RDBMS | Hadoop |
|---|---|---|
| 格式 | 写数据时要求 | 读数据时要求 |
| 速度 | 读数据速度快 | 写数据速度快 |
| 数据监管 | 准结构化 | 任意数据结构 |
| 数据处理 | 有限的处理能力 | 强大的处理能力 |
| 数据类型 | 结构化数据 | 结构化、半结构化、非结构化 |
| 应用场景 | 交互式OLAP分析、ACID事务处理、企业业务系统 | 处理非结构化数据、海量数据存储计算 |

Zookeeper
- 是一个分布式应用程序协调服务
解决分布式集群中应用系统的一致性问题 - 提供的功能
配置管理、命名服务、分布式同步、队列管理、集群管理 - 特性
- 全局数量一致
可靠性、顺序性、实时性
数据更新原子性
- 全局数量一致
- Zookeeper集群
角色:Leader、Follower、Observer
Hadoop架构
- HDFS(Hadoop Distributed File System)
分布式文件系统,解决分布式存储 - MapReduce
分布式计算框架 - YARN
分布式资源管理系统、在Hadoop 2.x中引入 - Common
支持所有其他模块的公共工具程序
HDFS特点
- HDFS优点
支持处理超大文件
可运行在廉价机器上
高容错性
流式文件写入 - HDFS缺点
不适合低延时数据访问场景
不适合小文件存取场景
不适合并发写入,文件随机修改场景
HDFS CLI(命令行)
- 基本格式
hdfs dfs -cmd
hadoop fs -cmd (已过时) - 命令和linux相似:-ls、-mkdir、-put、-rm、-help
hdfs dfs -put /opt/sed.txt /mydemo 把opt里面的sed.txt上传到mydemo文件夹里面
hdfs dfs -text /mydemo/sed.txt 查看sed.txt
hdfs dfs -mkdir -p /mydemo/xuxu 递归创建目录mydemo/xuxu
hdfs dfs -rmr /mydemo 递归删除mydemo目录
hdfs dfs -get /mydemo/xuxu/sed.txt /opt/ 把xuxu里面的sed.txt文件下载到/opt里面
使用HDFS shell处理移动通讯数据
创建存放数据文件的目录:
hdfs dfs -mkdir /hdfs/shell
hdfs dfs -ls/hdfs/shell
将通讯数据上传到HDFS并查看
hdfs dfs -put /home/hadoop/data/mobile.txt/hdfs/shell
hdfs dfs -text /hdfs/shell/mobile.txt
下载文件到本地
hdfs dfs -get /hdfs/shell/mobile.txt /home/hadoop
统计目录下文件大小
hdfs dfs -du /hdfs/shell
删除移动数据文件和目录
hdfs dfs -rm /hdfs/shell/mobile.txt
hdfs dfs -rmr /hdfs rmr递归删除目录下所有子目录和文件,生产环境慎用
HDFS角色
- Client:客户端
- NamaNode(NN):元数据节点
管理文件系统的Namespace/元数据
一个HDFS集群只有一个Active的NN - DataNode(DN):数据节点
数据存储节点,保存和检索Block
一个集群可以有多个数据节点 - Secondary NameNode(SNN):从元数据节点
合并NameNode的edit logs到fsimage文件中
辅助NN将内存中元数据信息持久化
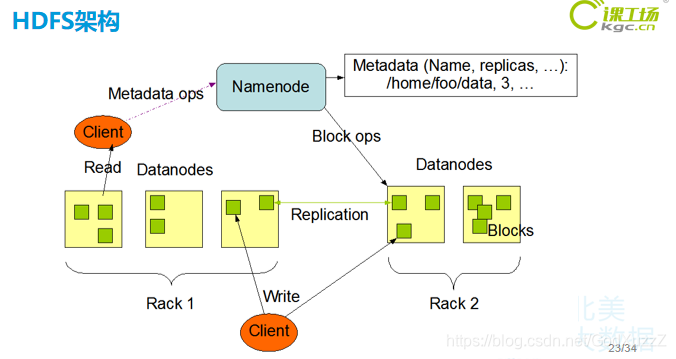
HDFS副本机制:
- Block:数据块
- HDFS最基本的存储单元
默认块大小:128M(2.x)
- HDFS最基本的存储单元
- 副本机制:
- 作用:避免数据丢失
副本数默认为3
存放机制- 一个在本地机架节点
一个在同一个机架不同节点
一个在不同机架的节点
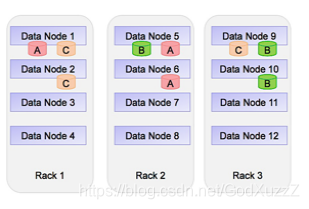
为什么默认块大小为128M?

- 一个在本地机架节点
- 作用:避免数据丢失
HDFS高可用
- 在2.x版本中
解决:HDFS Federation方式,共享DN资源
Active NameNode:对外提供服务
Standby NameNode:Active故障时可切换为Active
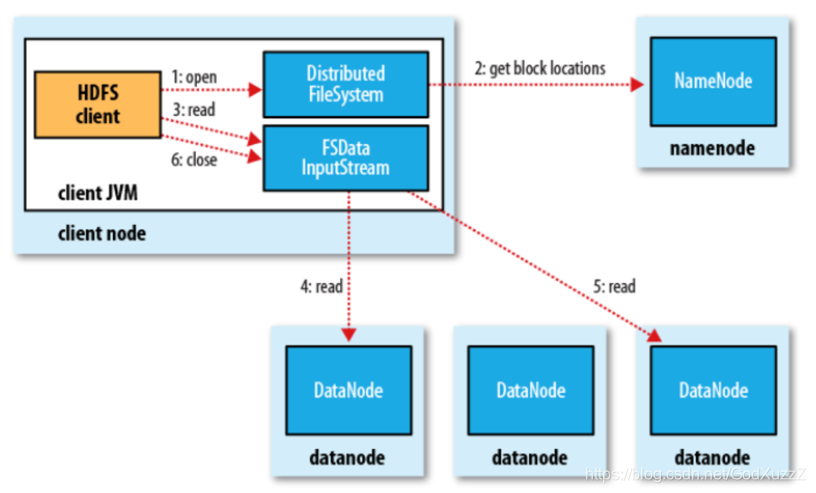
HDFS读文件:
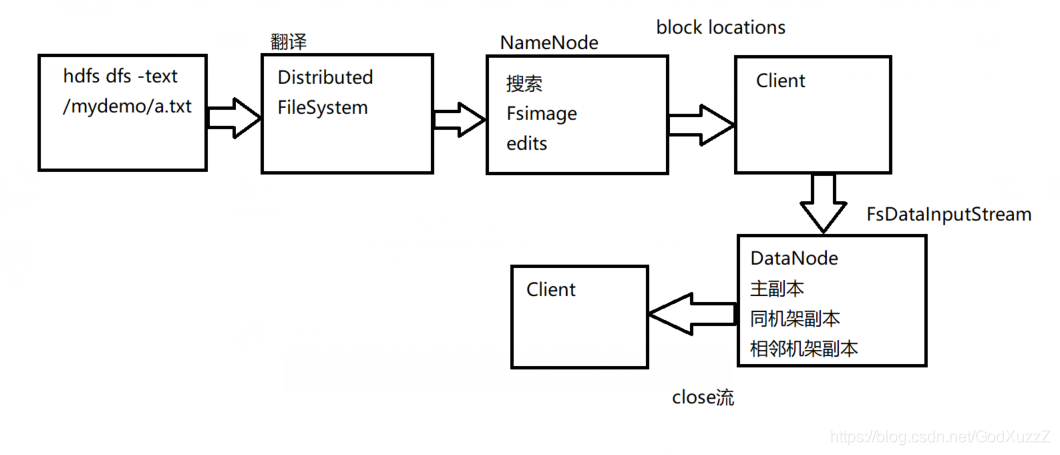
客户下达命令,要读a.txt文件,经过分布式文件系统的读取,到namenode读取fsimage和行为日志edits.log,再把这些数据块地址都打包发送到客户端,经过fsinputstream读取文件输入流读取datanode里面的数据然后返回到客户端,最后关闭输入流。
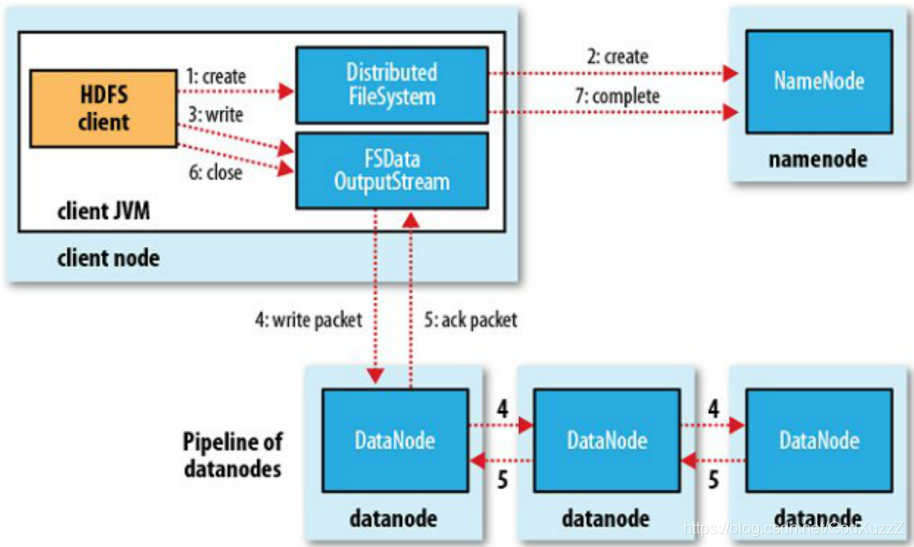
HDFS写文件:
首先向分布式文件系统发送信号,然后向namenode发送信号确认是否有空间存放,namenode返回信号和空间地址到客户端,然后经过输出流fsdataoutputstream往datanode写入数据,并备份至同机架副本和相邻机架副本,然后向客户端发送信号完成写入,最后关闭输出流。

















 3734
3734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









