 Hive索引详解:Local Index, Cube与Global Index
Hive索引详解:Local Index, Cube与Global Index





 本文介绍了Hive的三种索引类型:Local Index、Cube和Global Index。Local Index通过字典编码技术提高过滤速度,Cube针对高聚合率优化查询效率,而Global Index通过定位文件位置减少不必要的数据读取。文章详细阐述了每种索引的特性和创建方法,并给出了创建Local Index和Cube的示例。
本文介绍了Hive的三种索引类型:Local Index、Cube和Global Index。Local Index通过字典编码技术提高过滤速度,Cube针对高聚合率优化查询效率,而Global Index通过定位文件位置减少不必要的数据读取。文章详细阐述了每种索引的特性和创建方法,并给出了创建Local Index和Cube的示例。
hive的索引包括三种:Local Index、Cube和Global Index。接下来分别进行介绍。
通俗的说:global index,标记记录在哪个文件。local index,标记记录在单个文件里哪个位置。cube,类似local index,同时对多个字段做索引。
Local Index是将列式存储的每个单元看作整体建立的。Local Index的创建采用了字典编码技术。相对于通过遍历每一条记录进行条件过滤的手段,使用Local Index大幅度缩短了过滤时间。
Cube是对相关字段聚合信息的整理,Cube对于聚合率高的情况有很好的优化效应。如果没有采用Cube,有可能要依次读取出每个block中的记录。而创建了Cube之后,可以直接获取需要的聚合信息,减少对原表的读取(最差情况数量相同),所以创建有效的Cube可以使查询效率更高。
Local Index和Cube支持的数据类
型:boolean,byte,short,int,float,double,long,date,timestamp,decimal,string,varchar,
不支持嵌套类型。
以下将分别介绍创建Local Index和Cube的语法。
1. 创建Local Index的语法:
CREATE TABLE <holodesk_table_name>(
<column_name1> <DATATYPE1>,
<column_name2> <DATATYPE2>,
...
) STORED AS HOLODESK WITH TABLESIZE <table_size>
TBLPROPERTIES (
"holodesk.index" = "<localindex_key1>,<localindex_key2>,..."
);2. Cube
创建Cube的语法:
CREATE TABLE <holodesk_table_name>(
<column_name1> <DATATYPE1>,
<column_name2> <DATATYPE2>,
...
) STORED AS HOLODESK WITH TABLESIZE <table_size>
TBLPROPERTIES (
"holodesk.dimension" = "<cube1_dim1>, <cube1_dim2>, ... |
<cube2_dim1>, <cube2_dim2>, ...|
..."
) ;
例 48. 针对某应用场景设计Holodesk表的创建
假设对于holodeskEmployee表将有如下的查询语句:
SELECT Sex, Region, COUNT(ID) AS cnt, AVG (Salary) AS avg_salary
FROM holodeskEmployee
WHERE Department = 'IT'
GROUP BY Sex, Region
ORDER BY Sex, Region;
如果在建表时为“Department”字段建立Local Index,根据(“Sex”,“Region”)建立Cube,则有助于提升查询效率,原因如下:
• WHERE 中的条件对“Department”的值进行过滤,如果为“Department”创建Index,就可以通过索引直接获得满足“Department = 'IT'”的所有记录,而不用遍历整张表。
• 根据(“Sex”, “Region”)建立Cube将整合出基于“Sex”和“Region”两个字段的所有聚合信息,并保存于HashMap 中。实时计算聚合函数所消耗的时间。
所以应该通过如下语句建表并创建相应Local Index、Cube,并从Employee 导入数据:
DROP TABLE IF EXISTS holodeskEmployee;
CREATE TABLE holodeskEmployee
STORED AS HOLODESK WITH TABLESIZE 10MB
TBLPROPERTIES (
"holodesk.index" = "Department",
"holodesk.dimension" = "Sex, Region"
) AS SELECT * FROM employee1;
Global Index
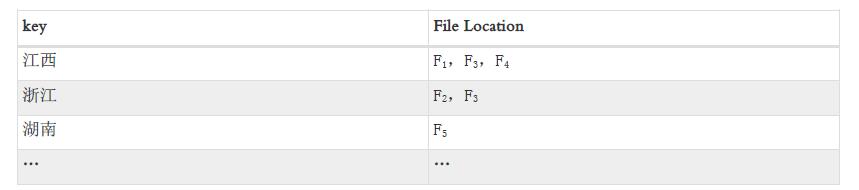
创建Global Index的同时会生成一张GI表,用于存储Key所在的文件位置,在执行查询语句时,会先查GI表,定位Key所在的文件,过滤掉不必要的文件,从而提高执行效率。查GI表会造成少量额外的时间开销,所以Global Index适合建在高过滤率的字段,可有效减少task数量,这是Local Index和Cube做不到的。假设为destination字段创建Global Index,生成的对应的GI表大致如下所示:
1. 创建Global Index
CREATE TABLE <holodesk_table_name>(
<column_name1> <DATATYPE1>,
<column_name2> <DATATYPE2>,
...
) STORED AS HOLODESK WITH TABLESIZE <table_size>
TBLPROPERTIES (
"HOLODESK.GLOBALINDEX" = "<globalindex_key1>,<globalindex_key2>,...", ① ②
"GLOBALINDEX.BUCKET" = "<globalindex_bucket_number>" ③
);① Global Index支持的数据类型:int,double,float,string(n),varchar
(m),long,byte,short,boolean,date。
② HOLODESK.GLOBALINDEX与GLOBALINDEX.BUCKET需同时指定。
③ GLOBALINDEX.BUCKET计算公式:GLOBALINDEX.BUCKET=1/10原表大小÷100M。即十分之一原表大小除
以100M。
2. 导入数据
INSERT INTO <holodesk_table_name>
SELECT * FROM table_B;
参考资料:
星环
Transwarp ArgoDB使用手册
章节:4.4索引


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









