




1、三大角色

2、物理组成

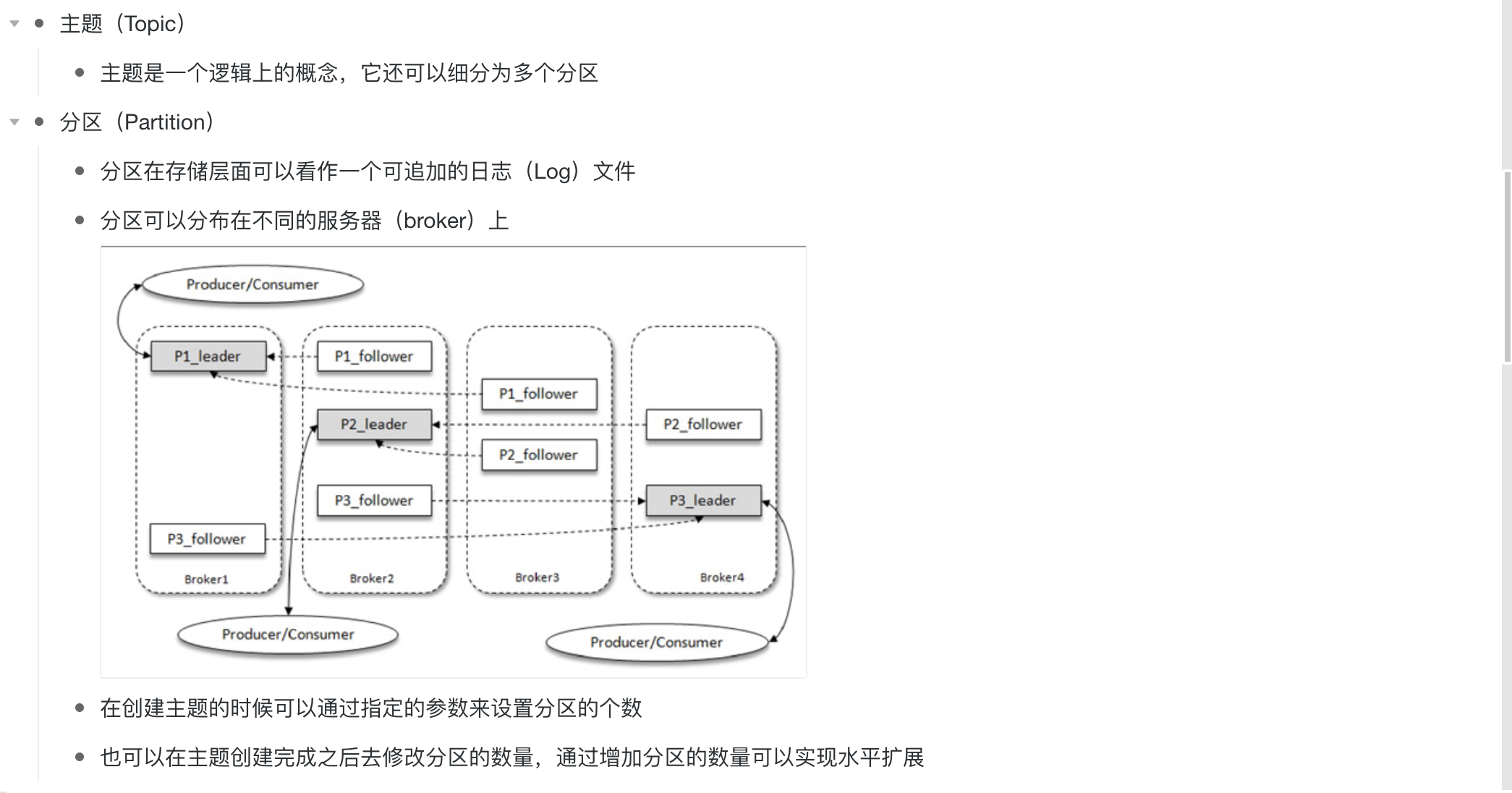
3、逻辑概念


4、bin目录下的实用脚本

5、服务端参数配置


6、重要的生产者参数

7、消费者与消费组


8、提交消费位移

9、重要的消费者参数



10、日志文件目录
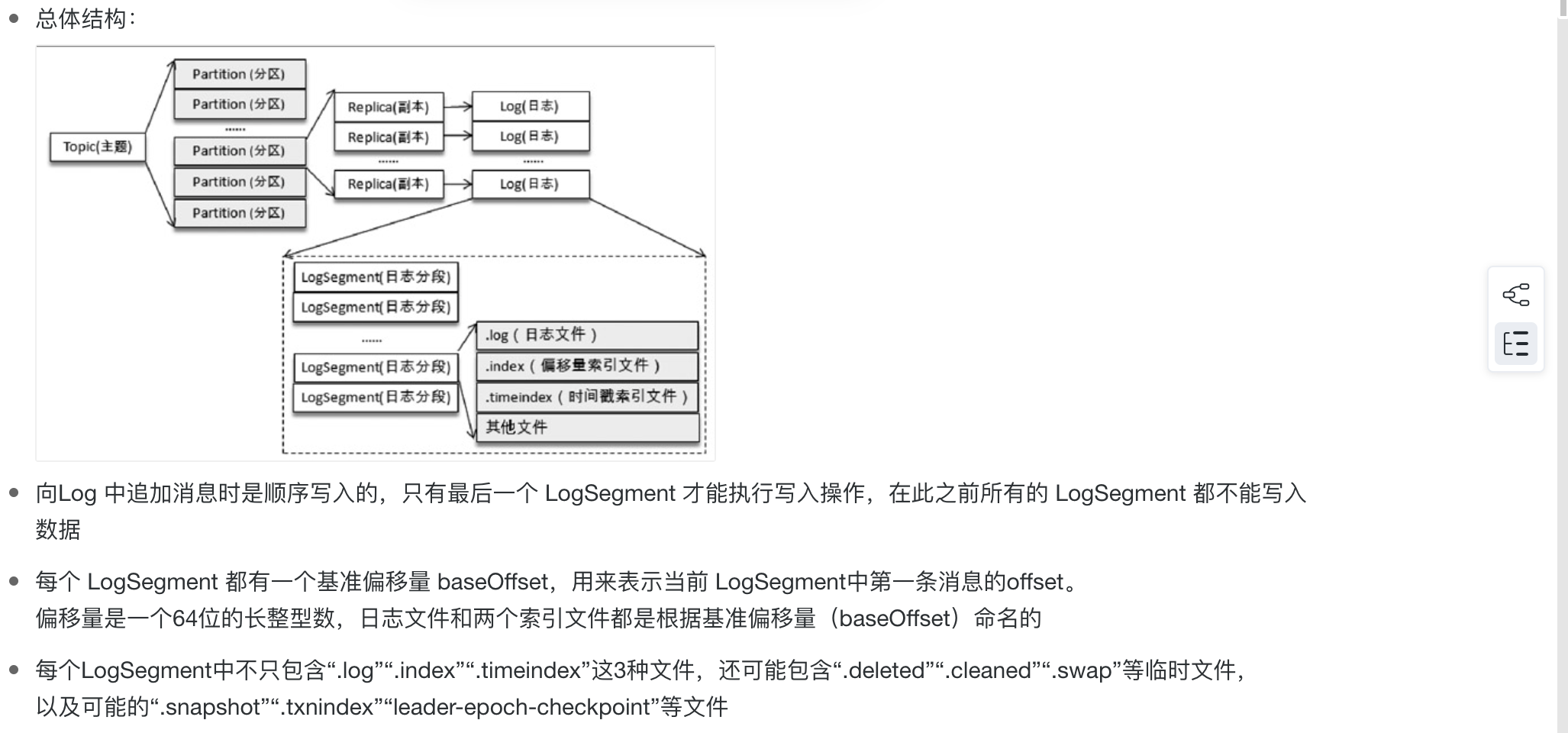
11、日志索引

12、日志分段文件切分
满足其一即可:

13、日志删除
1、基于时间

2、基于日志大小

3、基于日志起始偏移量

14、延时队列
在Kafka中实现延迟队列通常不是直接通过Kafka的原生功能来实现的,因为Kafka本身是一个高吞吐量的分布式消息系统,主要用于处理实时数据流。然而,你可以通过一些方法来模拟延迟队列的功能。

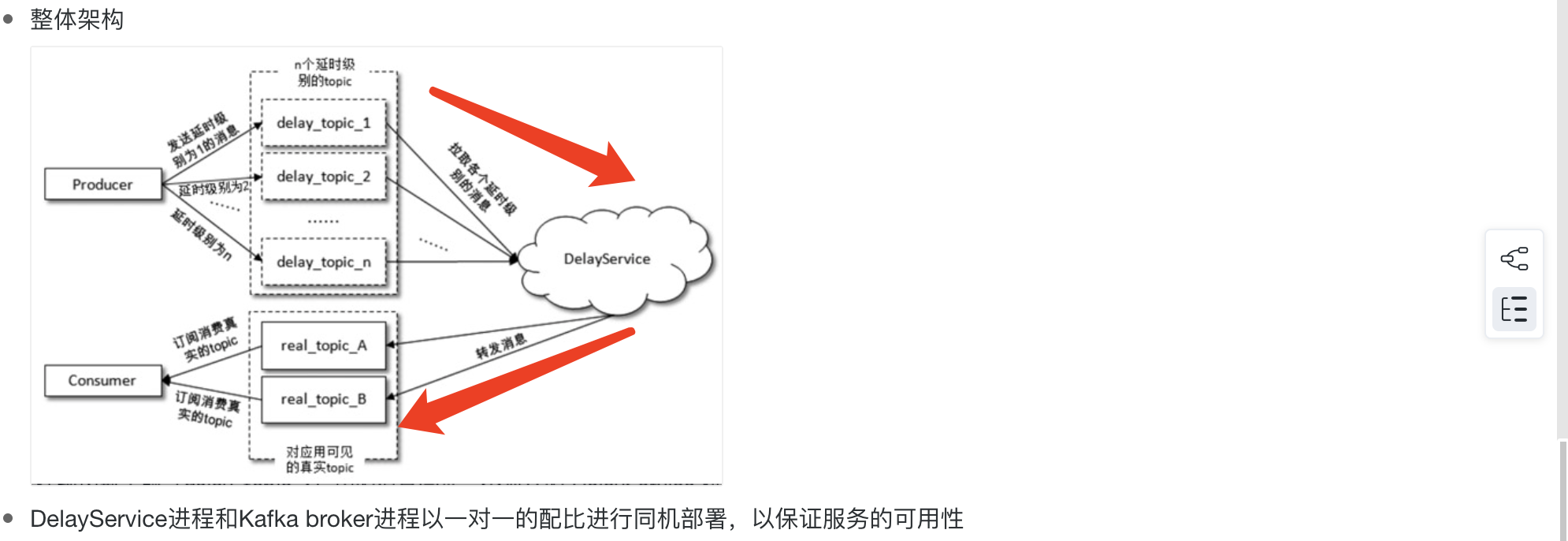
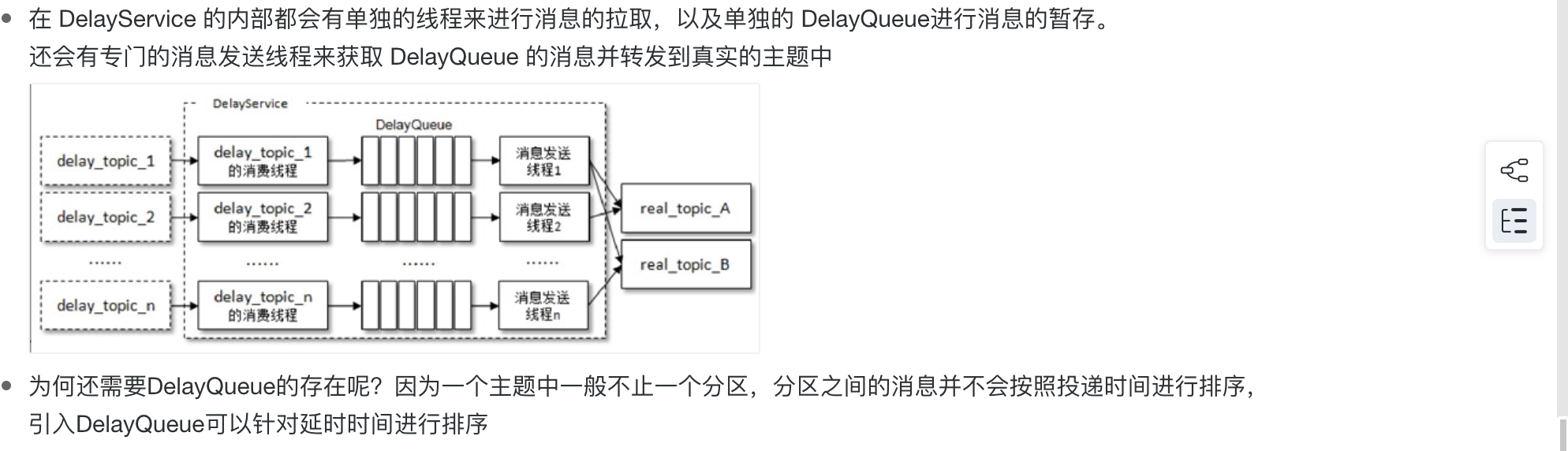
如果延迟时间超级长,没有延迟等级可以满足,那么消费到了消息可以在投递一遍延迟队列,直到时间到达在真正消费消息。
15、事务



















 2142
2142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









