



内容速览:
- 腾讯《三角洲行动》周年庆登双榜TOP1
- Playstack 2025年上半年收入增长52%,达3070万英镑
- 腾讯首款生活模拟游戏《粒粒的小人国》曝光
- 米哈游首款生活模拟游戏《星布谷地》发布首曝PV
- Google Play推出一系列新游戏功能
- 9月156款版号下发:《归环》《星绘友晴天》《崩坏:因缘精灵》等在列
腾讯《三角洲行动》周年庆登双榜TOP1
9月17日,腾讯天美旗下琳琅天上研发的多端FPS游戏《三角洲行动》迎来了S6“烈火冲天”赛季的上线。新赛季上线当天,《三角洲行动》一举冲上iOS畅销总榜Top1,并同时斩获游戏免费榜Top1,国际服的Steam同时在线人数也创下22.6万的历史新高。根据点点数据,截至9月21日,游戏依然稳居免费榜和畅销榜双榜第一。
这次是《三角洲行动》发布一年来首次登顶iOS畅销总榜,标志着其在市场上的强劲增长。今年4月,游戏宣布日活跃用户(DAU)已达到1200万;7月,DAU突破2000万;而在9月21日的周年庆活动上,制作人Shadow宣布,国服DAU已突破3000万,仅仅两个月时间便实现了从2000万到3000万的飞跃。

Playstack 2025年上半年收入增长52%,达3070万英镑
据近日报告称,Playstack今年上半年收入同比增长52%,达3070万英镑(约合4140万美元),相比2024年的2020万英镑(约合2720万美元)。这一强劲的业绩得益于其热销游戏《Balatro》和《Abiotic Factor》,两者在2025年上半年共售出超过300万套。这一成绩继2024年创下了710万套销量,并且玩家在其游戏中的累计游戏时长超过了1.5亿小时。

腾讯首款生活模拟游戏《粒粒的小人国》曝光
9月24日,腾讯旗下银之心工作室首曝生活模拟治愈新作《粒粒的小人国》,同步开启全平台预约。游戏以5cm小人视角构建世界,采用类绘本卡通画风,玩家可建造、种田、换装,还能收集阳光、香气等特色资源。上百位 “粒粒”NPC有专属人设与互动,社交无强制且重质量。游戏属腾讯 “春笋计划” 孵化,现处内容丰满阶段,长线将推主题版本与UGC功能,力求打造全年龄段精神乌托邦。

米哈游首款生活模拟游戏《星布谷地》发布首曝PV
9月25日,米哈游首款生活模拟游戏《星布谷地》首曝PV并开启 “宜居测试” 招募,游戏获版号。其为米哈游首次涉足联机社交赛道,画风偏Q版萌系卡通,含种植、建造、换装等经典玩法。玩家可拥有星球家园,能星际旅行探访不同星球伙伴,支持好友串门、共庆等社交互动,还融入剧情与UGC建设元素。

Google Play推出一系列新游戏功能
Google Play推出了一系列新功能,包括Play Games Sidekick,它通过AI实时提供游戏内指导;Play Games Leagues,让玩家通过参与竞技争夺Play Points和荣誉,首个比赛将在《Subway Surfers》中举行。此外,You标签将于10月1日上线,为玩家提供个性化奖励、订阅和推荐。游戏详情页也得到优化,加入了事件、更新及玩家进度显示。Google Play Games on PC正式发布,标志着Google推动跨平台游戏的承诺

9月156款版号下发:《归环》《星绘友晴天》《崩坏:因缘精灵》等在列
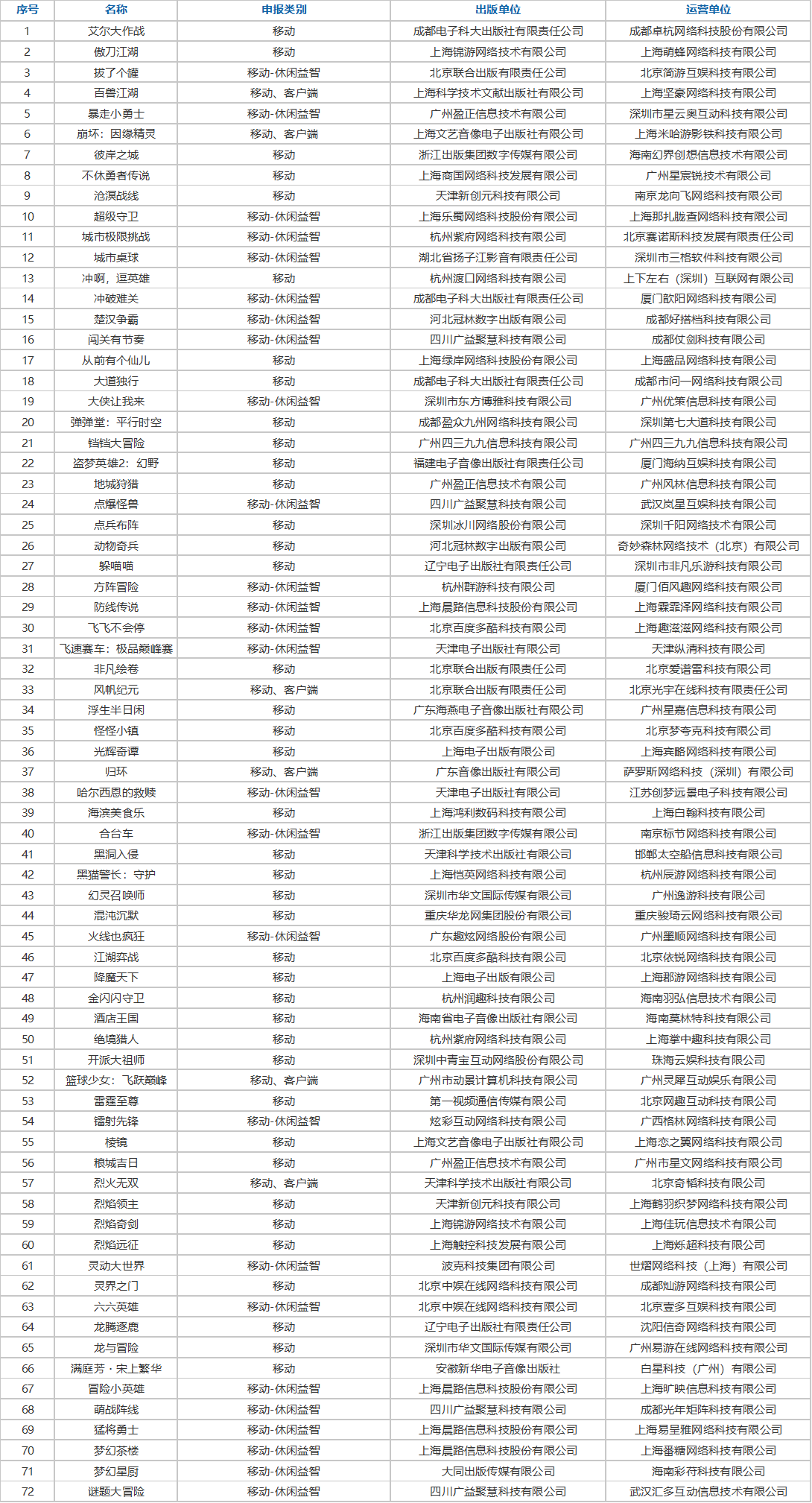
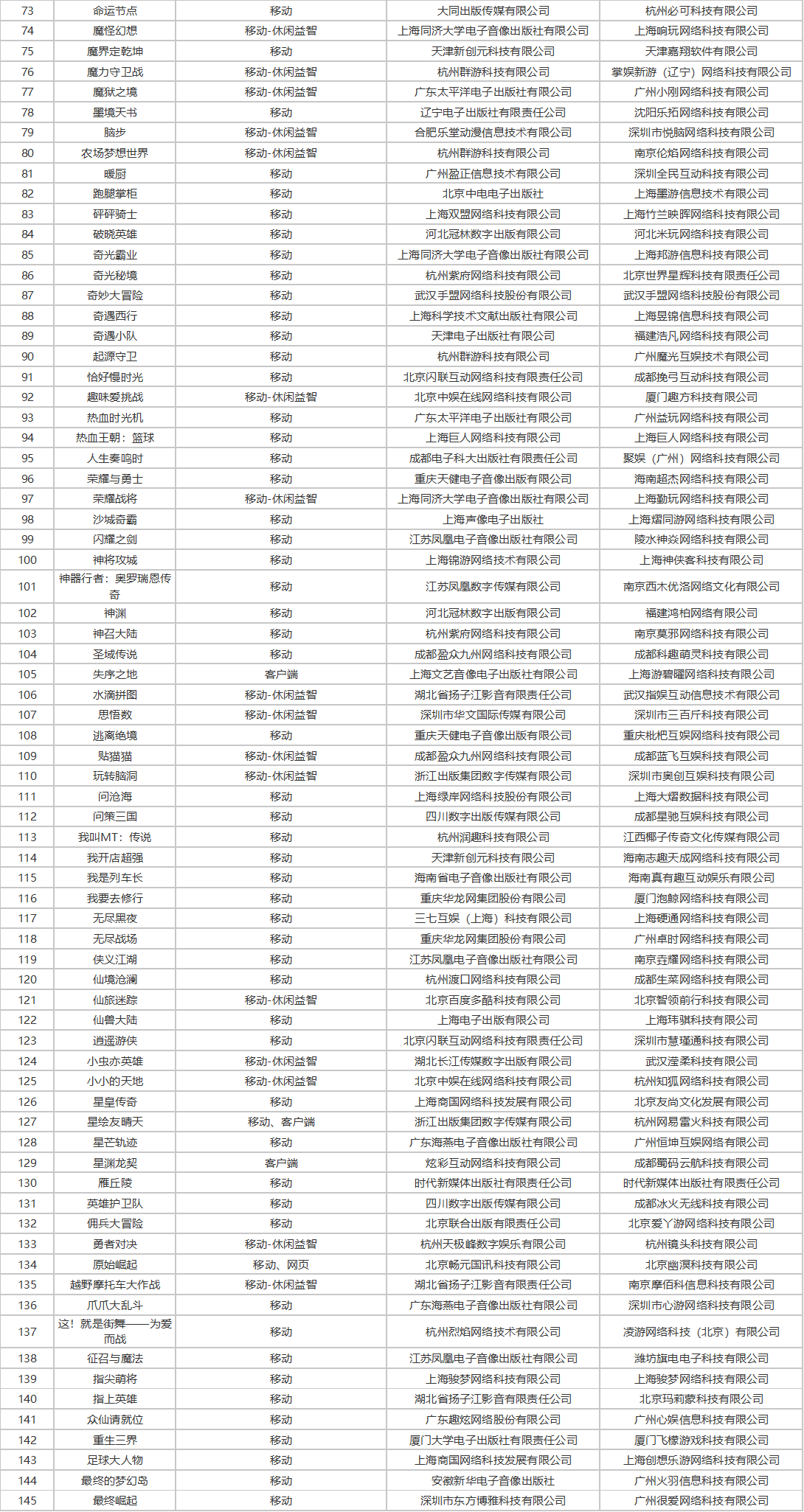
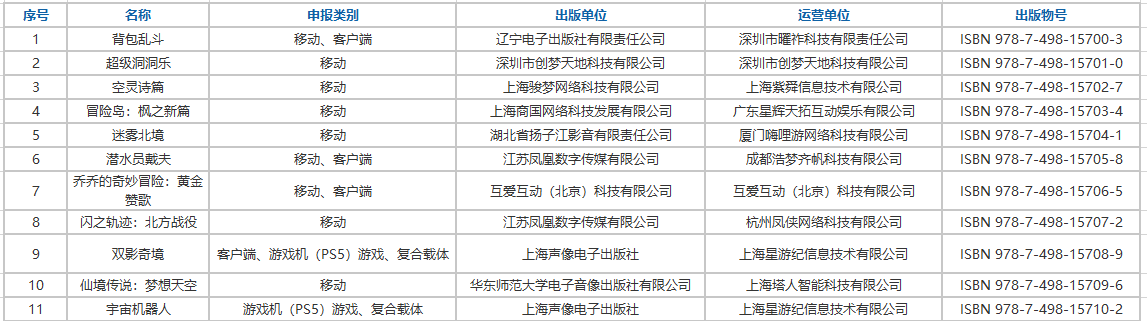
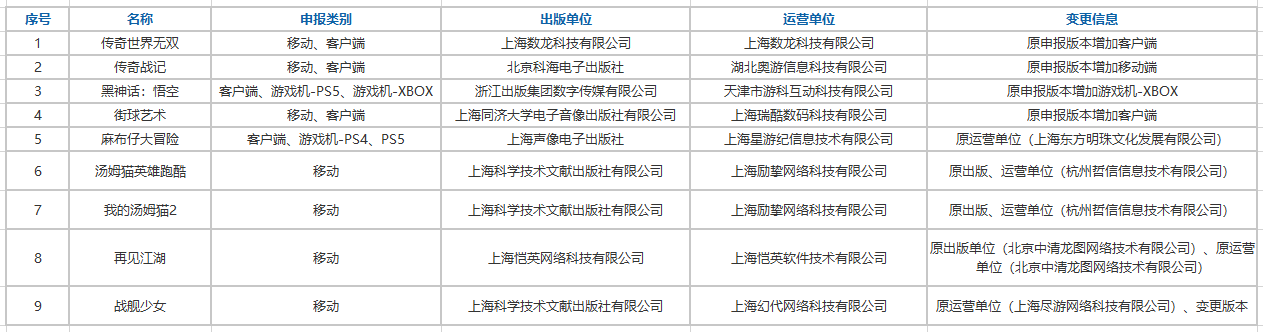
9月24日,国家新闻出版署发布了《2025年9月份网络游戏审批信息》消息。本次下发的版号共156款,包括145款国产网络游戏版号:其中135款移动游戏、2款客户端游戏,7款同时拿到移动和客户端版号、1款游戏同时拿到移动和网页游戏版号。还有11款进口网络游戏获得版号:其中6款移动游戏、3款移动+客户端、1款同时获得游戏机(PS5)游戏、复合载体版号,1款同时获得客户端、游戏机(PS5)游戏和复合载体版号。版号信息变更游戏9款。
本次过审版号腾讯《归环》、网易《星绘友晴天》、米哈游《崩坏:因缘精灵》、点点互动《海滨美食乐》、浩梦齐帆《潜水员戴夫》等知名厂商产品在列。
国产版号:
进口版号:
版号信息变更:

















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









