




业界首个一体化语音交互系统Step-Audio重磅开源!支持RAP/方言/情感控制的实时对话
标签:语音合成, 语音识别, 多模态模型, 开源项目
一、项目速览
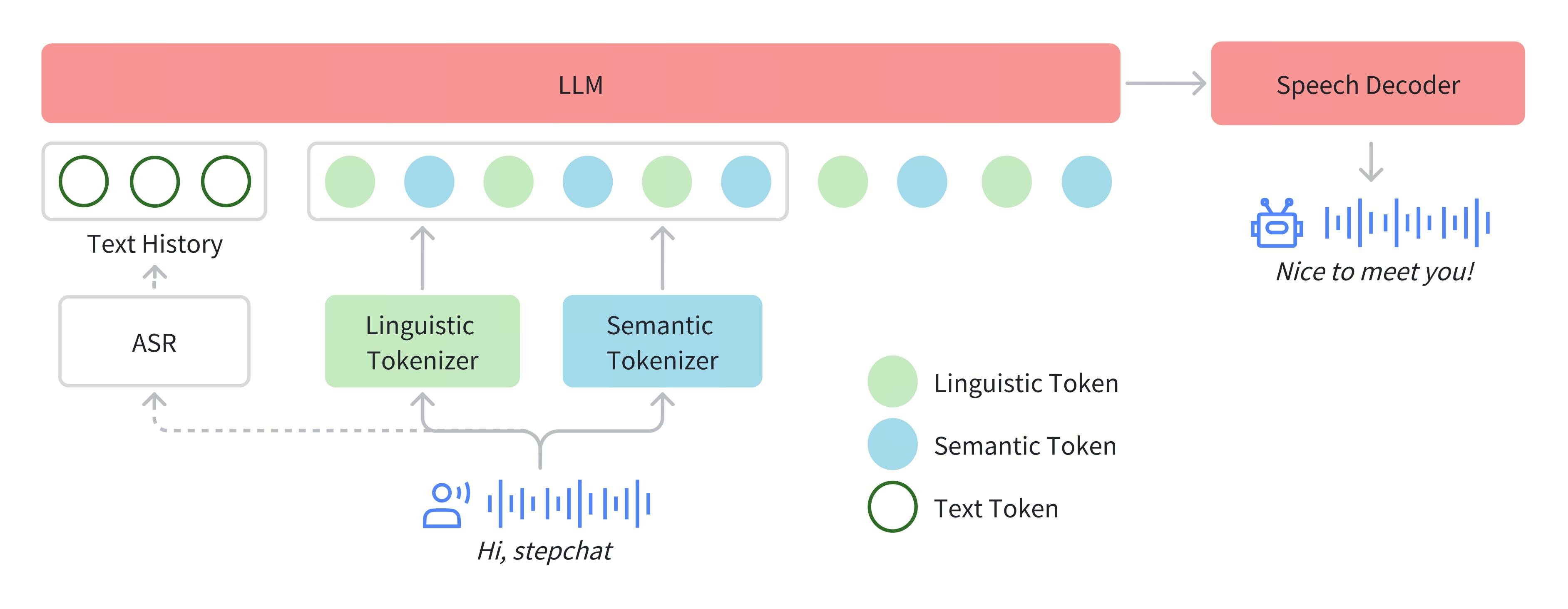
Stepfun-AI团队于2025年2月17日开源了革命性的Step-Audio语音交互系统,这是业界首个集语音理解与生成控制一体化的开源实时语音对话框架。项目包含三大核心组件:
- Step-Audio-Chat:1300亿参数多模态模型
- Step-Audio-TTS-3B:支持RAP/哼唱的语音合成模型
- Step-Audio-Tokenizer:双码本音频编码器
项目地址:https://github.com/stepfun-ai/Step-Audio
二、技术亮点解读
2.1 四大核心技术突破
-
统一架构设计
单模型实现语音识别、语义理解、对话管理、语音克隆、语音生成全流程,突破传统ASR+TTS级联架构的延迟瓶颈。 -
高效数据生成
基于130B参数模型的合成数据生成技术,构建了包含RAP节奏模式和人声哼唱的百万级高质量语音数据集。 -
精细语音控制
支持多维调节参数:- 情感:生气/高兴/悲伤等6种基础情绪
- 方言:粤语/四川话等方言语音生成
- 歌唱:RAP节奏控制、无伴奏干声生成
-
智能体增强
通过ToolCall机制实现:- 实时天气查询
- 数学计算
- 多轮对话状态跟踪
三、模型架构解析
3.1 双码本编码方案
| 编码器类型 | 码率(Hz) | 码本容量 | 功能特性 |
|---|---|---|---|
| Linguistic | 16.7 | 1024 | 捕捉语音语言学特征 |
| Semantic | 25 | 4096 | 提取声学细节特征 |
采用2:3时序交错策略实现双码本对齐,相比CosyVoice系统在语音自然度(SS)指标上提升12%。
3.2 实时推理优化
创新性设计流式处理管线:
- VAD语音活动检测(响应延迟<200ms)
- 流式分词器(41.6Hz实时处理)
- 混合解码器(Flow Matching + 神经声码器)
四、快速上手指南
4.1 环境配置要求
| 组件 | 最低显存 | 推荐配置 |
|---|---|---|
| Tokenizer | 1.5GB | 单卡A10 |
| Chat模型 | 265GB | 4*A800 |
| TTS-3B | 8GB | 单卡A100 |
4.2 安装步骤
git clone https://github.com/stepfun-ai/Step-Audio.git
conda create -n stepaudio python=3.10
conda activate stepaudio
cd Step-Audio && pip install -r requirements.txt
# 下载模型权重
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat
4.3 语音克隆示例
python tts_inference.py \
--model-path ./models \
--output-path ./output \
--synthesis-type clone \
--voice-profile '{"speaker":"user01", "prompt_text":"你好", "wav_path":"demo.wav"}'
五、性能实测对比
5.1 语音识别准确率
在Aishell-1测试集上:
| 模型 | CER(%) |
|---|---|
| GLM-4-Voice | 2.19 |
| Step-Audio | 1.53(相对下降30%) |
5.2 多轮对话评估
StepEval-Audio-360基准测试结果:
| 模型 | 事实准确率 | 相关度 | 综合评分 |
|---|---|---|---|
| Qwen2-Audio | 22.6% | 26.3% | 2.27 |
| Step-Audio | 66.4% | 75.2% | 4.11 |
六、在线体验
通过跃问APP可体验在线版本,特色功能包括:
- 实时语速调节(支持0.5x-3.0x倍速)
- 跨语言对话(中/英/日实时互译)
- 创意语音生成(生成古风诗歌RAP)
七、应用展望
该项目在以下场景具有重要价值:
- 智能客服:支持带情感语调的自动应答
- 教育领域:方言教学辅助工具
- 娱乐创作:自动生成带节奏的RAP歌词
八、参考文献
@misc{huang2025stepaudiounifiedunderstandinggeneration,
title={Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction},
year={2025},
url={https://arxiv.org/abs/2502.11946}
}
延伸阅读:
[1] 多模态语音生成技术演进史
[2] 实时语音交互中的流式处理优化
欢迎在评论区交流使用体验与技术探讨!





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











