




 本文围绕Python展开,介绍了基本运算符,包括算术、比较、赋值等运算及优先级;阐述了流程控制,如if、while、for循环;讲解了编码知识,如ASCII、GBK、Unicode、UTF - 8;还详细说明了文件操作,涵盖读、写、追加等模式及相关功能。
本文围绕Python展开,介绍了基本运算符,包括算术、比较、赋值等运算及优先级;阐述了流程控制,如if、while、for循环;讲解了编码知识,如ASCII、GBK、Unicode、UTF - 8;还详细说明了文件操作,涵盖读、写、追加等模式及相关功能。
4. 基本运算符
4.1 算术运算
以下假设变量:a = 5,b = 2
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加:两个对象相加 | a + b = 7 |
| - | 减:一个数减去另一个数 | a - b = 3 |
| * | 乘:两个数相乘 / 得到若干个重复的字符串 | a * b = 10 |
| / | 除:一个数除以另一个数 | a / b = 2.5 |
| % | 取余:返回除法的余数 | a % b = 1 |
| ** | 幂次:一个数的幂次方 | a ** b = 25 |
| // | 取整:返回商的整数部分 | a // b = 2 |
4.2 比较运算
以下假设变量:a = 5,b = 2
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较对象是否相等 | (a == b) 返回False |
| != | 不等于:比较两个对象是否不相等(常用) | (a != b) 返回True |
| <> | 不等于:比较两个对象是否不相等(不常用) | (a <> b) 返回True |
| > | 大于:比较前者是否大于后者 | (a > b) 返回True |
| < | 小于:比较前者是否小于后者 | (a < b) 返回False |
| >= | 大于等于:比较前者是否大于等于后者 | (a >= b) 返回True |
| <= | 小于等于:比较前者是否小于等于后者 | (a <= b) 返回False |
4.3 赋值运算
以下假设变量:a = 5,b = 2
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c == a + b 将a + b的运算结果赋值给c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取余法赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂次法赋值运算符 | c ** = a 等效于 c = c ** a |
| //= | 取整法赋值运算符 | c //= a 等效于 c = c // a |
4.4 逻辑运算
以下假设变量:a = True,b = False
| 运算符 | 描述 | 实例 |
|---|---|---|
| and | 布尔‘与’:两者同为真则返回True,否则将返回False | (a and b) 返回False |
| or | 布尔‘或’:两者至少有一为真则返回True,否则将返回False | (a or b) 返回True |
| not | 布尔‘非’:如果是真的则返回False,若是假的则返回True | not (a and b) 返回True |
1、针对逻辑运算的进一步研究:
- x or y :x为真,值就是x,x为假,值是y;
- x and y :x为真,值是y,x为假,值是x
'''----- or -----'''
print(8 or 4)
# 8 都为真取or前面的
print(0 or False)
# False 都为假取or后面的
print(0 or 3)
# 3 一真一假取真
'''----- and -----'''
print(8 and 4)
# 4 都为真取and后面的
print(0 and 3)
# 0 一真一假取假
print(False and 0)
# False 都为假取and前面的
2、在没有括号 () 的情况下,not 优先级高于 and,and优先级高于or,即优先级关系为:() > not > and > or,同一优先级从左往右计算
- 例题:判断下列逻辑语句的True,False
print(0 or 4 and 3 or 7 or 9 and 6)
# 0 or (4 and 3) or 7 or (9 and 6) = 0 or 3 or 7 or 6 = 3 or 7 or 6 = 3
print(3 > 4 or 4 < 3 and 1 == 1)
# 3 > 4 or (4 < 3 and 1 == 1)
# False or (False) = False
print(1 < 2 and 3 < 4 or 1 > 2)
# (1 < 2 and 3 < 4) or 1 > 2
# (True) or False = True
print(2 > 1 and 3 < 4 or 4 > 5 and 2 < 1)
# (2 > 1 and 3 < 4) or (4 > 5 and 2 < 1)
# (True) or (False) = True
print(1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8)
# (1 > 2 and 3 < 4) or (4 > 5 and 2 > 1) or 9 < 8
# (False) or (False) or False = False or False = False
print(1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)
# (1 > 1 and 3 < 4) or (4 > 5 and 2 > 1) and 9 > 8 or 7 < 6
# (False) or (False) and True or False = False or False or False = False
print(not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6)
# (not 2 > 1 and 3 < 4) or (4 > 5 and 2 > 1) and 9 > 8 or 7 < 6
# False and True or False and True or False = False or False or False = False
4.5 成员运算
除了以上的一些运算符之外,Python还支持成员运算符,测试实例中包含了一系列的成员,包括字符串,列表或元组
| 运算符 | 描述 | |
|---|---|---|
| in | 若在指定的序列中找到值则返回True,否则将返回False | 'a' in 'abc' 返回True |
| not in | 若在指定的序列中未找到值则返回True,否则将返回False | 'b' not in ‘abc’ 返回False |
4.6 运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ 、+ 、- | 按位翻转,一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| *、 / 、% 、// | 乘,除,取模和取整除 |
| +、 - | 加法减法 |
| >>、 << | 右移,左移运算符 |
| & | 位 'AND' |
| ^、 | | 位运算符 |
| <、= <、 > 、>= | 比较运算符 |
| <> 、==、 != | 等于运算符 |
| =、 %= 、/=、 //= 、-= 、+=、 *= 、**= | 赋值运算符 |
| is、 is not | 身份运算符 |
| in、 not in | 成员运算符 |
| not、 and、 or | 逻辑运算符 |
4.7 其他:id、is、==
1、id:
- id是内存地址, 你只要创建一个数据(对象)那么都会在内存中开辟一个空间,将这个数据临时加在到内存中,那么这个空间是有一个唯一标识的,就好比是身份证号,标识这个空间的叫做内存地址,也就是这个数据(对象)的id,可以利用id()去获取这个数据的内存地址:
print(id('雨落'))
# 输出结果:
1270310754352
2、is 和 ==:
-
== 是比较的两边的数值是否相等
-
is 是比较的两边的内存地址是否相等。 如果内存地址相等,那么这两边其实是指向同一个内存地址
可以说如果内存地址相同,那么值肯定相同,但是如果值相同,内存地址不一定相同
i1 = 1000
i2 = 1000
print(i1 is i2) # False 内存地址不同
print(i1 == i2) # True 数值相同
5. 流程控制
Python的缩进有以下几个原则:
-
顶级代码必须顶行写,即如果一行代码本身不依赖于任何条件,那它必须不能进行任何缩进
-
同一级别的代码,缩进必须一致
-
官方建议缩进用4个空格,当然你也可以用2个(显得不专业)
5.1 流程控制:if
1、单分支
if 条件:
满足条件后要执行的代码
2、双分支
if 条件:
满足条件执行代码
else:
if条件不满足就走这段
'''---------例如---------'''
AgeOfQY = 18
if AgeOfQY > 50 :
print("可以准备退休了")
else:
print("还能折腾几年!")
# 输出结果:还能折腾几年!
3、多分支
if 条件:
满足条件执行代码
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
elif 条件:
上面的条件不满足就走这个
else:
上面所有的条件不满足就走这段
'''---------例如---------'''
age_of_qy = 18
guess = int(input("请输入你猜测的庆言年龄:"))
if guess > age_of_qy :
print("猜的太大了,往小里试试...")
elif guess < age_of_qy :
print("猜的太小了,往大里试试...")
else:
print("恭喜你,猜对了...")
5.2 流程控制:while
5.2.1 while循环
while 条件:
循环体
# 如果条件为真,那么循环体则执行
# 如果条件为假,那么循环体不执行
如何终止循环
-
改变条件(根据上面的流程,只要改变条件,就会终止循环)
-
关键字:break(终止循环)
-
调用系统命令:quit(),exit() ,不建议使用
-
关键字:continue(终止本次循环)
5.2.2 终止while循环
1、方式一:标志位
利用改变条件,终止循环。此处引入标志位的概念
while True: # 由于条件为True,会一直循环打印
print('1')
print('2')
print('3')
print('4')
'''---引入标志位---'''
flag = True # 先设定一个flag,使其为True
while flag:
print('1')
print('2')
print('3')
flag = False # 此处改变flag为False
print('4') # 本行继续打印,然后再到while处条件改为False,结束程序
- 练习1:输出1-100的数字,代码如下:
count = 1
flag = True
while flag:
print(count)
count = count + 1
if count == 101:
flag = False
- 练习2:使用while循环求出1-100所有数的和,思路和代码如下:
'''
思路:你要想从1+2+3......+100一直加到100,
那么最起码你得有一个自变量,比如count,
这个count每次循环都会自加1,除了这个之外,你还有有一个变量,
让这个变量一直去加这个count,这个基础变量还不能影响最终的结果,
所以这个基础变量初始值为0,按照这个思路写一下。
'''
count = 1
s = 0
while count < 101:
s = s + count
count = count + 1
print(s)
# 输出结果:
5050
2、方式二:break
break:是Python给大家提供的关键字,什么是关键字?就是Python中具有一定特殊意义的单词,比如if,str,int等,这些不能用作变量对吧?那么break的用法:循环中,只要遇到break马上退出循环。举例说明:
flag = True # 先设定一个flag,使其为True
print(111)
while flag:
print('1')
print('2')
print('3')
break # 此处遇到break直接结束当前循环
print('4') # 本行不打印
print(222)
# 输出结果:
111
1
2
3
222
- 练习3:打印1~100所有的偶数,代码如下:
'''
思路:所有的偶数,偶数有什么特点? 对2取余为0,
取余在python中用%表示。再循环时,你要先打印出1~100所有的数。
在这个基础上加以改动:当count为偶数时打印,否则什么操作都不做。
'''
# 方法一:
count = 1
while True:
if count % 2 == 0:
print(count)
count = count + 1
if count == 101:
break
# 方法二:
count = 1
while count < 101:
if count % 2 == 0:
print(count)
count = count + 1
# 方法三:
count = 2
while count < 101:
print(count)
count = count + 2
3、方式三:quit(),exit()
4、方式四:continue
continue 用于终止本次循环,继续下一次循环。举例说明:
flag = True # 先设定一个flag,使其为True
print(111)
while flag:
print('1')
print('2')
print('3')
continue # 此处遇到continue直接跳过当前循环
print('4') # 本行不打印
print(222) # 本行也不打印,会继续打印'1','2','3'
# 输出结果:
1
2
3
1
2
3
……
- 练习4:使用while循环打印 1 2 3 4 5 6 8 9 10
count = 0
while count < 10:
count = count + 1
if count == 7:
continue
print(count)
- 练习5:请输出1 2 3 4 5 95 96 97 98 99 100
count = 0
while count <= 100 :
count += 1
if count > 5 and count < 95: # count在6-94,直接进入下一次loop(循环)
continue
print( count)
5.3 while…else…
-
与其它语言else 一般只与if 搭配不同,在Python 中还有个while ...else… 语句
-
while 后面的else 作用是指,当while 循环正常执行完,中间没有被break 中止的话,就会执行else后面的语句
count = 0
while count <= 5 :
count += 1
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
# 输出结果:
Loop 1
Loop 2
Loop 3
Loop 4
Loop 5
Loop 6
循环正常执行完啦
-----out of while loop ------
- 如果执行过程中被break啦,就不会执行else的语句啦
count = 0
while count <= 5:
count += 1
if count == 3:
break
print("Loop",count)
else:
print("循环正常执行完啦")
print("-----out of while loop ------")
# 输出结果:
Loop 1
Loop 2
-----out of while loop ------
5.4 循环:for
for循环:用户按照顺序循环可迭代对象的内容
- 对于字符串而言:
msg = '雨落NB'
for item in msg:
print(item) # print有换行的作用
# 输出结果:
雨
落
N
B
- 对于列表而言:
li = ['雨落','庆言','女神']
for i in li:
print(i)
# 输出结果:
雨落
庆言
女神
- 对于字典而言:
dic = {'name':'庆言','age':18,'sex':'femal'}
for k,v in dic.items():
print(k,v)
# 输出结果:
name 庆言
age 18
sex femal
5.5 循环:enumerate
enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
li = ['雨落','庆言','女神']
for i in enumerate(li): # 元组的形式,索引加元素
print(i)
# 输出结果:
(0, '雨落')
(1, '庆言')
(2, '女神')
起始位置默认为0,但也可以修改为任意值
li = ['雨落','庆言','女神']
for index,name in enumerate(li,1): # 起始位置更改为1
print(index,name)
# 输出结果:
1, 雨落
2, 庆言
3, 女神
5.6 循环:range
ange:指定范围,生成指定数字(顾头不顾尾)
for i in range(1,10): # 生成1-9的整数
print(i) # 1 2 3 4 5 6 7 8 9
for i in range(1,10,2): # 步长
print(i) # 1 3 5 7 9
for i in range(10,1,-2): # 反向步长
print(i) # 10 8 6 4 2
练习:利用len和range打印列表的索引
l1 = ['雨落', 'yuluo', 'qingyan', 12, 666]
for i in range(len(l1)):
print(i)
# 输出结果:
0
1
2
3
4
6. 编码
6.1 编码初始
6.1.1 ASCII码
包含英文字母,数字,特殊字符与01010101对应关系
计算机起初使用的密码本是:ASCII码(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统ASCII码中只包含英文字母,数字以及特殊字符与二进制的对应关系,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号
a 01000001 一个字符一个字节表示
6.1.2 GBK
只包含本国文字(以及英文字母,数字,特殊字符)与0101010对应关系
随着计算机的发展,以及普及率的提高,流⾏到欧洲和亚洲。这时ASCII码就不合适了,比如:中⽂汉字有几万个,而ASCII 最多也就256个位置,所以ASCII不行了,怎么办呢?这时,不同的国家就提出了不同的编码用来适用于各自的语言环境(每个国家都有每个国家的GBK,每个国家的GBK都只包含ASCII码中内容以及本国自己的文字)。比如,中国的GBK,GB2312,BIG5,ISO-8859-1等等,这时各个国家都可以使用计算机了
经实际测试和查阅文档,GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码
对于ASCII码中的内容,GBK完全沿用的ASCII码,所以一个英文字母(数字,特殊字母)用一个字节表示,而对于中文来说,一个中文用两个字节表示
a 01000001 ascii码中的字符:一个字符一个字节表示
中 01001001 01000010 中文:一个字符两个字节表示
6.1.3 Unicode
包含全世界所有的文字与二进制0101001的对应关系
但是GBK只包含中文,不能包含其他文字,言外之意,GBK编码是不能识别其他国家的文字的,举个例子:如果你购买了一个日本的游戏盘,在用中国的计算机去玩,那么此时中国的计算机只有GBK编码和ASCII码,那么你在玩游戏的过程中,只要出现日本字,那就会出错或者出现乱码.......
但是,随着全球化的普及,由于网络的连通,以及互联网产品的共用(不同国家的游戏,软件,建立联系等),各个国家都需要产生各种交集,此时急需一个密码本:要包含全世界所有的文字与二进制0101010的对应关系,所以创建了万国码
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS-2用两个字节编码,UCS-4用4个字节编码。
起初:Unicode规定一个字符用两个字节表示:
英文:a b c 六个字节 一个英文用2个字节
中文:中国 四个字节 一个中文用2个字节
但这种最多有65535种可能,可是中国文字有9万多,所以改成一个字符用四个字节表示
b 01000001 01000010 01100011 00000001
中 01001001 01000010 01100011 00000001
这样虽然解决了问题,但是又引出一个新的问题就是原本a可以用1个字节表示,却必须用4个字节,这样非常浪费资源,所以对Uniocde进行升级
6.1.4 UTF-8(重点)
包含全世界所有的文字与二进制0101001的对应关系(最少用8位一个字节表示一个字符)
英文: 8位 一个字节表示
欧洲文字: 16位 两个字节表示一个字符
中文,亚洲文字: 24位 三个字节表示
常见单位转化:
8 bit = 1 byte # 8位 = 1字节
1 byte = 1024^-1 KB = 1024^-2 MB = 1024^-3 GB = 1024^-4 TB = 1024^-5 PB
6.1.5 其他说明
在计算机内存中,统一使用Unicode编码,当需要将数据保存到硬盘或者需要网络传输的时候,就转换为非Unicode编码,比如:UTF-8编码
-
其实这个不用深入理解,他就是规定,举个例子:用文件编辑器(word,wps,等)编辑文件的时候,从文件将你的数据(此时你的数据是非Unicode(可能是UTF-8,也可能是GBK,这个编码取决于你的编辑器设置))字符被转换为Unicode字符读到内存里,进行相应的编辑,编辑完成后,保存的时候再把Unicode转换为非Unicode(UTF-8,GBK 等)保存到文件
不同编码之间,不能直接互相识别
-
比如你的一个数据:‘老铁没毛病’是以utf-8的编码方式编码并发送给一个朋友,那么你发送的肯定是通过UTF-8的编码转化成的二进制01010101,那么你的朋友接收到你发的这个数据,他如果想查看这个数据必须将01010101转化成汉字,才可以查看,那么此时那也必须通过UTF-8编码反转回去,如果要是通过GBK编码反转,那么这个内容可能会出现乱码或者报错
编码(encode)和解码(decode)
-
如果你的str数据想要存储到文件或者传输出去,那么直接是不可以的,我们要将str数据转化成bytes数据就可以了,方法如下:
# encode称作编码:将 str 转化成 bytes类型
# 转化成utf-8的bytes类型
s1 = '中国'
b1 = s1.encode('utf-8')
print(s1) # 中国
print(b1) # b'\xe4\xb8\xad\xe5\x9b\xbd'
# 转化成gbk的bytes类型
s1 = '中国'
b1 = s1.encode('gbk')
print(s1) # 中国
print(b1) # b'\xd6\xd0\xb9\xfa'
# decode称作解码, 将 bytes 转化成 str类型
b1 = b'\xe4\xb8\xad\xe5\x9b\xbd'
s1 = b1.decode('utf-8')
print(s1) # 中国
6.2 代码块
Python程序是由代码块构造的。块是一个Python程序的文本,他是作为一个单元执行的。打个比方:咱们学生就好比是代码,班级就好比是代码块,我们想组织什么活动,也就是让代码运行起来,必须依靠班级去执行,也就是代码块
-
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块
-
而作为交互方式输入的每个命令都是一个代码块
什么叫交互方式?就是咱们在cmd中进入Python解释器里面,每一行代码都是一个代码块,例如:
i1 = 1000 # 这是一个代码块
i2 = 1000 # 这也是一个代码块
而对于一个文件中的两个函数,也分别是两个不同的代码块:
def func1():
pass # 这是一个代码块
def func2():
pass # 这也是一个代码块
6.3 深浅拷贝(copy)
顾名思义,深拷贝就是完全复制一份,而浅拷贝就是部分复制
6.3.1 赋值运算(==)
1、代码1:
l1 = [1,2,3,['yuluo','qingyan']]
l2 = l1 # 相当于l1、l2两个标签贴在内存上
l1[0] = 111 # 改动了内存,l1和l2还是对应同一个内存地址,故还是相同的
print(l1) # [111, 2, 3, ['yuluo', 'qingyan']]
print(l2) # [111, 2, 3, ['yuluo', 'qingyan']]
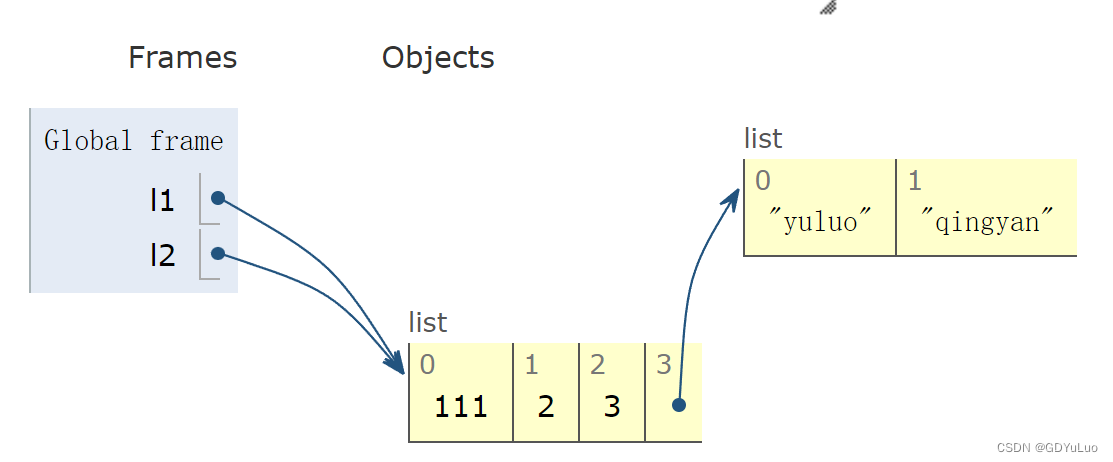 2、代码2:
2、代码2:
l1 = [1,2,3,['yuluo','qingyan']]
l2 = l1 # 相当于l1、l2两个标签贴在内存上
l1[3][0] = '雨落' # 还是同理,l1和l2对应的都是同一个内存地址的标签
print(l1) # [111, 2, 3, ['雨落', 'qingyan']]
print(l2) # [111, 2, 3, ['雨落', 'qingyan']]
print(id(l1), id(l2)) # 2827732023104 2827732023104
print(id(l1[-1]),id(l2[-1])) # 2827731226688 2827731226688
print(id(l1[-1][-1]),id(l2[-1][-1])) # 2827731225968 2827731225968
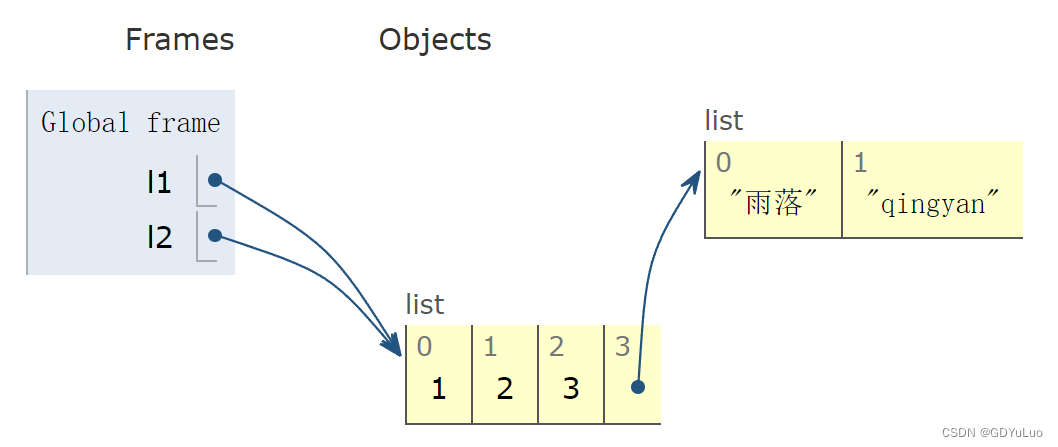
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的,在举个例子,比如雨落和庆言住在一起,那么对于客厅来说,他们是公用的,雨落可以用,庆言也可以用,但是突然有一天雨落把客厅的的电视换成投影了,那么庆言使用客厅时,想看电视没有了,而是投影了,对吧?l1,l2指向的是同一个列表,任何一个变量对列表进行改变,剩下那个变量在使用列表之后,这个列表就是发生改变之后的列表
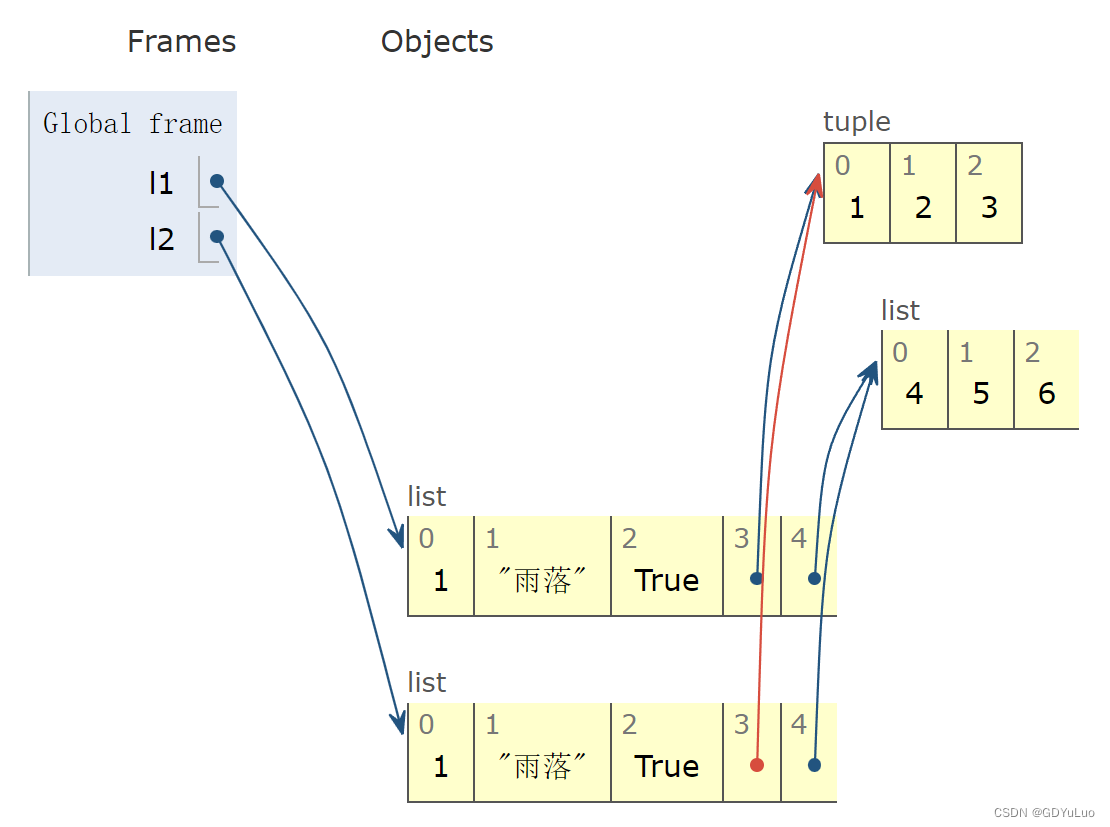
6.3.2 浅拷贝(copy)
对于浅copy来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的
l1 = [1, '雨落', True, (1,2,3), [4,5,6]]
l2 = l1.copy()
print(id(l1), id(l2)) # 2223863330624 2223863330816
print(id(l1[-2]), id(l2[-2])) # 2223863426944 2223863426944
print(id(l1[-1]),id(l2[-1])) # 2223862534208 2223862534208
print(id(l1[-2][-2]),id(l2[-2][-2])) # 140731884757832 140731884757832
print(id(l1[-1][-1]),id(l2[-1][-1])) # 140731884757960 140731884757960
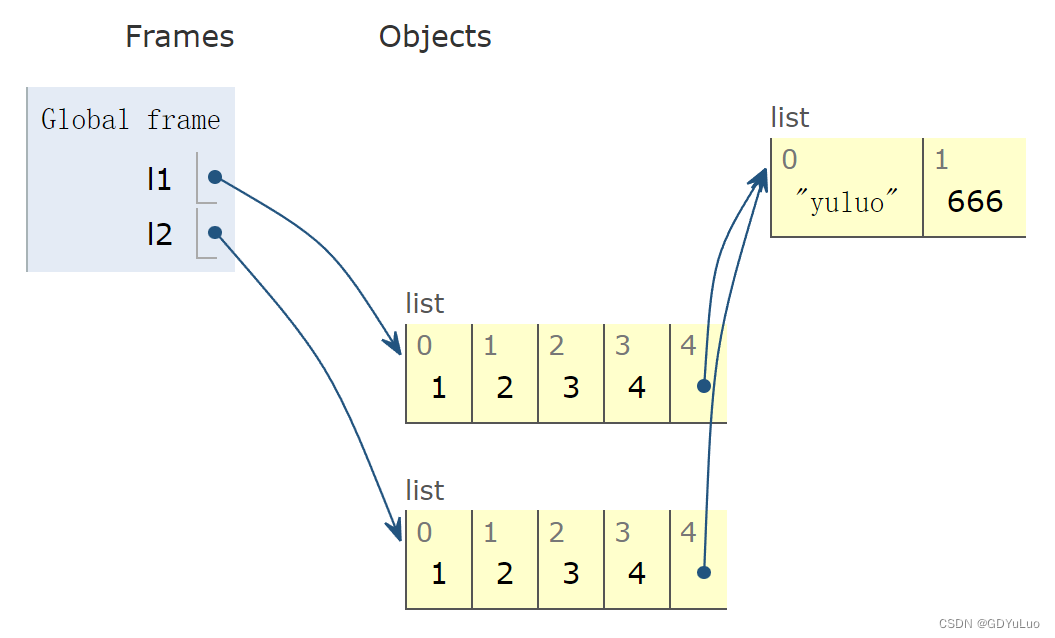
6.3.3 深拷贝(deepcopy)
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的
l1 = [1, 2, 3, 4, ['yuluo']]
l2 = l1[::]
l1[-1].append(666)
print(l1)
print(l2)
# 输出结果:
[1, 2, 3, 4, ['yuluo', 666]]
[1, 2, 3, 4, ['yuluo', 666]]
6.4 文件的操作
6.4.1 文件操作初始
现在让你用Python开发一个软件来操作一个文件,你觉得你需要什么必要参数呢
-
文件路径:D:\全国富婆通讯录.txt
-
编码方式:utf-8,gbk,gb2312....
-
操作模式:只读,只写,追加,写读,读写....
此时你需要先利用软件创建一个文件,文件里面随便写一些内容,然后保存在任意磁盘(路径尽量要简单一些)中。然后创建一个py文件,利用Python代码打开这个文件
f = open('d:\全国富婆通讯录.txt',mode='r',encoding='utf-8')
content = f.read()
print(content)
f.close()
代码解读:
-
f:文件句柄,就是一个变量,一般都会将它写成f, f_obj, file, f_handler, fh等
-
open:是Python调用的操作系统(windows,linux,等)的功能
-
'd:\全国富婆通讯录.txt':这个是文件的路径
-
mode:就是定义你的操作方式,r为读模式
-
encoding='utf-8':此次打开文件使用 'utf-8' 编码本
-
f.read():你想操作文件,比如读文件,给文件写内容等,都必须通过文件句柄进行操作
-
close():关闭文件句柄(可以把文件句柄理解成一个空间,这个空间存在内存中,必须要主动关闭)
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
# 1. 打开文件,得到文件句柄并赋值给一个变量
f = open('a.txt','r',encoding='utf-8') # 默认打开模式就为r
# 2. 通过句柄对文件进行操作
data=f.read()
# 3. 关闭文件
f.close()
在打开文件路径的时候,有时候 ’\‘ 会被计算机”误解“,如果想只表示文件路径:
-
解决方式一:多加一个斜杠,例如:
'C:\\Users\\yuluo\\Desktop\\111.txt' -
解决方式二:添加转义字符r,例如:
r'C:\Users\yuluo\Desktop\\111.txt'
相对路径与绝对路径:
-
1. 绝对路径:从磁盘根目录开始一直到文件名
-
2. 相对路径:用一个文件夹下的文件,相对于当前这个程序所在的文件而言。如果在同一个文件中,则相对路径就是这个文件名。如果再上一层文件夹则要使用../
相对路径下,你就可以直接写文件名即可
编码的问题:打开文件的编码与文件存储时的编码用的编码本不一致导致,比如这个文件当时用word软件保存时,word软件默认的编码为utf-8,但是你利用python代码打开时,用的gbk,那么就会报错了
6.4.2 文件操作
文件操作的操作模式分为三个类:读,写,追加。每一类又有一些具体的方法
6.4.2.1 文件的 - 读
6.4.2.1.1 r模式
r 以只读方式打开文件,文件的指针将会放在文件的开头。是文件操作最常用的模式,也是默认模式,如果一个文件不设置mode,那么默认使用r模式操作文件
f = open('path/男神.txt',mode='r',encoding='utf-8')
msg = f.read()
f.close()
print(msg)
# 运行结果:
雨落1号
雨落2号
雨落3号
1、read()
read() 将文件中的内容全部读取出来。但弊端是如果文件很大就会非常的占用内存,易导致内存奔溃
2、read(n)
read()读取的时候指定读取到什么位置。在r模式下,n 按照字符读取
f = open('path/男神.txt',mode='r',encoding='utf-8')
msg1 = f.read(4) # 先读取4个字符
msg2 = f.read() # 剩下的全部读取
f.close()
print(msg1)
print(msg2)
# 输出结果:
雨落1号
雨落2号
雨落3号
3、readline()
readline() 读取每次只读取一行,注意点:readline()读取出来的数据在后面都有一个换行,即\n
f = open('path/帅哥.txt',mode='r',encoding='utf-8')
msg1 = f.readline()
msg2 = f.readline()
msg3 = f.readline()
f.close()
print(msg1)
print(msg2)
print(msg3)
# 输出结果:
雨落1号
雨落2号
雨落3号
解决这个问题只需要在我们读取出来的文件后边加一个strip()就OK了
f = open('path/帅哥.txt',mode='r',encoding='utf-8')
msg1 = f.readline().strip()
msg2 = f.readline().strip()
msg3 = f.readline().strip()
f.close()
print(msg1)
print(msg2)
print(msg3)
# 输出结果:
雨落1号
雨落2号
雨落3号
4、readlines()
readlines() 返回一个列表,列表里面每个元素是原文件的每一行,如果文件很大,占内存,容易崩盘
f = open('path/帅哥.txt', encoding='utf-8')
print(f.readlines())
f.close()
# 输出结果:
['雨落1号\n', '雨落2号\n', '雨落3号\n']
5、for循环
上面这4种都不太好,因为如果文件较大,他们很容易撑爆内存,所以我们可以通过for循环去读取,文件句柄是一个迭代器,他的特点就是每次循环只在内存中占一行的数据,非常节省内存
f = open('../path/帅哥',mode='r',encoding='utf-8')
for line in f:
print(line) # 这种方式就是逐行进行读取, 等同print(f.readline())
f.close() # 读完后的文件句柄一定要关闭
6.4.2.1.2 rb模式
rb模式:以二进制格式打开一个文件用于只读,文件指针将会放在文件的开头。记住下面讲的也是一样,带b的都是以二进制的格式操作文件,他们主要是操作非文字文件:图片,音频,视频等,并且如果你要是带有b的模式操作文件,那么不用声明编码方式
当然rb模式也有read,read(n),readline(),readlines(),for循环这几种方法
f = open('path/男神.jpg',mode='rb') # encoding默认为二进制格式
msg = f.read()
f.close()
print(msg)
6.4.2.2 文件的 - 写
6.4.2.2.1 w模式
如果文件不存在,利用w模式操作文件,那么它会先创建文件,然后写入内容
f = open('txt',encoding='utf-8',mode='w')
f.write('输入内容') # 以字符串形式写入
f.close() # 写完记得关闭
如果文件存在,利用w模式操作文件,先清空原文件内容,在写入新内容
f = open('txt',encoding='utf-8',mode='w')
f.write('输入内容') # 以字符串形式写入
f.close() # 写完记得关闭
6.4.2.2.2 wb模式
wb模式:以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如:图片,音频,视频等
我先以rb的模式将一个图片的内容以bytes类型全部读取出来,然后在以wb将全部读取出来的数据写入一个新文件,这样我就完成了类似于一个图片复制的流程。具体代码如下:
# 第一步,先把原图片通过rb模式读取出来
f = open('雨落原图.jpg',mode='rb') # rb模式下默认是二进制编码
content = f.read()
f.close()
# 第二步,将读取出来的数据通过wb模式写入新文件中
f1 = open('雨落新图.jpg',mode='wb')
f1.write(content)
f1.close()
6.4.2.2.3 w+模式
6.4.2.2.4 w+b模式
6.4.2.3 文件的 - 追加
6.4.2.3.1 a模式
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
f = open('txt',encoding='utf-8',mode='a')
f.write('追加/新建内容')
f.close()
6.4.2.3.2 ab模式
6.4.2.3.3 a+模式
6.4.2.3.4 a+b模式
6.4.2.4 文件的 - 其他模式
咱们还有一种模式没有讲,就是那种带+号的模式。+就是加一个功能。比如刚才讲的r模式是只读模式,在这种模式下,文件句柄只能进行类似于read的这读的操作,而不能进行write这种写的操作。所以我们想让这个文件句柄既可以进行读的操作,又可以进行写的操作
6.4.2.4.1 r+模式
r+:打开一个文件用于读写。文件指针默认将会放在文件的开头
f = open('txt',encoding='utf-8',mode='r+')
content = f.read()
print(content) # 这是原先的内容
f.write('这是新追加的内容')
f.close() # 这是原先的内容这是新追加的内容
注意:如果你在读写模式下,先写后读,那么文件就会出问题,因为默认光标是在文件的最开始,你要是先写,则写入的内容会讲原内容覆盖掉,直到覆盖到你写完的内容,然后在后面开始读取
6.4.2.5 文件的 - 其他功能
6.4.2.5.1 read(n)
-
文件打开方式为文本模式时,代表读取n个字符
-
文件打开方式为b模式时,代表读取n个字节
6.4.2.5.2 seek()
-
seek(n)光标移动到n位置,注意:移动单位是byte,所有如果是utf-8的中文部分要是3的倍数
-
通常我们使用seek都是移动到开头或者结尾
-
移动到开头:seek(0)
-
移动到结尾:seek(0,2) - 第二个参数表示的是从哪个位置进行偏移,默认是0-开头,1-当前位置,2-结尾
-
f = open("帅哥", mode="r+", encoding="utf-8")
f.seek(0) # 光标移动到开头
content1 = f.read() # 读取内容, 此时光标移动到结尾
print(content1)
f.seek(0) # 再次将光标移动到开头
f.seek(0, 2) # 将光标移动到结尾
content2 = f.read() # 读取内容. 什么都没有
print(content2)
f.seek(0) # 移动到开头
f.write("雨落") # 写入信息. 此时光标在6 一个中文三个字节
f.flush() # 强制保存文件
f.close() # 执行完之后及时关闭文件
6.4.2.5.3 tell()
- 使用tell()可以帮我们获取当前光标在什么位置
f = open("帅哥", mode="r+", encoding="utf-8")
f.seek(0) # 光标移动到开头
content1 = f.read() # 读取内容, 此时光标移动到结尾
print(content)
f.seek(0) # 再次将光标移动到开头
f.seek(0, 2) # 将光标移动到结尾
content2 = f.read() # 读取内容. 什么都没有
print(content2)
f.seek(0) # 移动到开头
f.write("雨落") # 写入信息. 此时光标在6
print(f.tell()) # 光标位置6
f.flush() # 强制保存文件
f.close() # 执行完之后及时关闭文件
6.4.2.5.4 readable(),writeable()
-
readable():如果文件是可读的,则 readable() 方法返回 True,否则返回 False
-
writeable():如果文件可写,则 writable() 方法返回 True,否则返回 False - 如果使用 "a" 追加或使用 "w" 写入来打开文件,则该文件是可写的
f = open('Test',encoding='utf-8',mode='r')
print(f.readable()) # True 可读
print(f.writable()) # False 不可写入
content = f.read()
f.close()
6.4.2.6 文件的 - 其他打开方式
咱们打开文件都是通过open去打开一个文件,其实Python也给咱们提供了另一种方式:with open() as .... 的形式,主要优点有以下两点:
1、利用with上下文管理这种方式,它会自动关闭文件句柄
with open('t1',encoding='utf-8') as f1:
f1.read()
# 则执行完文件后无需手动关闭
2、一个with 语句可以操作多个文件,产生多个文件句柄
with open('t1',encoding='utf-8') as f1,\
open('Test', encoding='utf-8', mode = 'w') as f2:
# 注意:此处的“\”为续行符(换行符),表示这两行应是归属于同一行
f1.read() # 对于f1句柄进行读的操作
f2.write('雨落好帅') # 对于f2句柄进行写的操作
注意:虽然使用with语句方式打开文件,不用你手动关闭文件句柄,但是依靠其自动关闭文件句柄,是有一段时间的,这个时间不固定,所以这里就会产生问题,如果你在with语句中通过r模式打开t1文件,那么你在下面又以a模式打开t1文件,此时有可能你第二次打开t1文件时,第一次的文件句柄还没有关闭掉,可能就会出现错误,他的解决方式只能在你第二次打开此文件前,手动关闭上一个文件句柄
6.4.2.7 文件的 - 修改
文件的数据是存放于硬盘上的,因而只存在覆盖、不存在修改这么一说,我们平时看到的修改文件,都是模拟出来的效果,具体的说有两种实现方式:
1、方式一:将硬盘存放的该文件的内容全部加载到内存,在内存中是可以修改的,修改完毕后,再由内存覆盖到硬盘(word,vim,nodpad++等编辑器)
import os # 调用系统模块
with open('a.txt') as read_f, open('.a.txt.swap','w') as write_f:
data = read_f.read() # 全部读入内存,如果文件很大,会很卡
data = data.replace('yuluo','雨落') # 在内存中完成修改
write_f.write(data) # 一次性写入新文件
os.remove('a.txt') # 删除原文件
os.rename('.a.txt.swap','a.txt') # 将新建的文件重命名为原文件
2、方式二:将硬盘存放的该文件的内容一行一行地读入内存,修改完毕就写入新文件,最后用新文件覆盖源文件
import os
with open('a.txt') as read_f, open('.a.txt.swap','w') as write_f:
for line in read_f:
line = line.replace('yuluo','雨落')
write_f.write(line)
os.remove('a.txt')
os.rename('.a.txt.swap','a.txt')
- 练习1:有如下文件,请把文件中的所有SB替换成雨落
------- a.txt -------
SB是是一个非常帅的帅哥。
为什么说SB那么帅呢?
因为SB小哥哥他的长相很好看!
除此之外,SB还给你们免费教学Python,
你们说SB能不帅吗?
---------- 解析 ----------
import os
with open('a.txt',encoding='utf-8') as f1, \
open('a_r.txt',encoding='utf-8',mode='w') as f2:
for line in f1: # 逐行读取f1中的内容
line = line.replace('SB','雨落') # 替换行内的关键词
f2.write(line) # 把新内容写入f2中
os.remove('a.txt') # 把源文件删除
os.rename('a_r.txt','a.txt') # 把新文件改名替换成源文件
6.4.2.8 文件的 - 操作总结
# 1. 打开文件的模式有(默认为文本模式):
r 只读模式【默认模式,文件必须存在,不存在则抛出异常】
w 只写模式【不可读;不存在则创建;存在则清空内容】
a 只追加写模式【不可读;不存在则创建;存在则只追加内容】
# 2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码(默认二进制)
# 3,‘+’模式(就是增加了一个功能)
r+ 读写【可读,可写】
w+ 写读【可写,可读】
a+ 写读【可写,可读】
# 4,以bytes类型操作的读写,写读,写读模式
r+b 读写【可读,可写】
w+b 写读【可写,可读】
a+b 写读【可写,可读】


















 3372
3372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









