




 本文介绍了PageObjectModel(POM)的设计思想,它将每个页面视为对象,页面元素和操作作为对象的属性和行为。文中详细展示了基础封装层(包括BasePage、Browser和Log类)、页面对象层(如HomePage和NewsPage类)以及测试用例层的实现,使用Python的selenium库进行自动化测试。此外,还讨论了日志记录的配置和unittest框架在编写测试用例中的应用。
本文介绍了PageObjectModel(POM)的设计思想,它将每个页面视为对象,页面元素和操作作为对象的属性和行为。文中详细展示了基础封装层(包括BasePage、Browser和Log类)、页面对象层(如HomePage和NewsPage类)以及测试用例层的实现,使用Python的selenium库进行自动化测试。此外,还讨论了日志记录的配置和unittest框架在编写测试用例中的应用。
POM是Page Object Model的简称,它是一种设计思想,意思是,把每一个页面,当做一个对象,页面的元素和元素之间操作方法就是页面对象的属性和行为。
POM一般使用三层架构,分别为:基础封装层、页面对象层、测试用例层。
目录结构大致如下
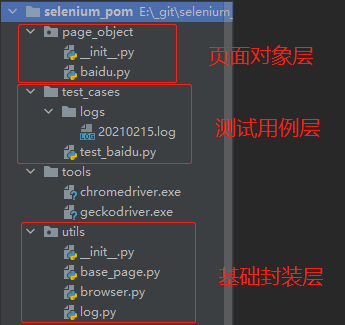
下面简单介绍下我的POM架构实现方式。
基础封装层
基础封装层主要是封装一些常用的方法,提高代码的复用。
基础封装层当前只包含了3个文件:
- base_page.py:将所有界面共用的方法进行封装
- browser.py:继承了selenium常用的webdriver操作,并对部分操作进行了封装
- log,py:封装日志功能
base_page.py文件代码如下:
class BasePage(object):
def __init__(self, driver):
self.__driver = driver
def find_element(self, by, value, times=10, wait_time=1) -> object:
return self.__driver.until_find_element(by, value, times=10, wait_time=1)因为在页面对象层,我们会将每个界面定义成一个类对象,而每个类对象都需要传入一个webdriver的实例对象,为了减少这样的重复操作,我们在base_page.py定义一个页面基类BasePage,在页面对象层定义的类继承该基类就可以完成webdriver实例对象的传入。
browser.py文件代码如下:
import time
import logging
from selenium.webdriver import Chrome, Firefox
from selenium.common.exceptions import NoSuchElementException
class Browser(Chrome, Firefox):
def __init__(self, browser_type="chrome", driver_path=None, *args, **kwargs):
"""
根据浏览器类型初始化浏览器
:param browser_type: 浏览器类型,只可传入chrome或firefox
:param driver_path:指定驱动存放的路径
"""
# 检查browser_type值是否合法
if browser_type not in ["chrome", "firefox"]:
# 不合法报错
logging.error("browser_type 输入值不为chrome,firefox")
raise ValueError("browser_type 输入值不为chrome,firefox")
self.__browser_type = browser_type
# 根据browser_type值选择对应的驱动
if self.__browser_type == "chrome":
if driver_path:
Chrome.__init__(self, executable_pat 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1576
1576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









