




 本文详细介绍了Redis的五大数据类型,包括Hash、Set和Zset,以及Python操作Redis的常见方法。此外,讨论了主从配置的概念,强调了主从同步在性能提升和数据安全性上的作用。同时,讲解了Redis的RDB持久化机制,包括触发方式、配置和优缺点。
本文详细介绍了Redis的五大数据类型,包括Hash、Set和Zset,以及Python操作Redis的常见方法。此外,讨论了主从配置的概念,强调了主从同步在性能提升和数据安全性上的作用。同时,讲解了Redis的RDB持久化机制,包括触发方式、配置和优缺点。
文章目录
1. Redis 常用五大数据类型
1.1 Redis-Hash
-
hash是一个键值对集合
-
hash是一个string类型的field和value的映射表,hash特别适合存储对象
- hset/hget/hmset/hmget/hgetall/hdel
设值/取值/设值多个值/取多个值/取全部值/删除值
hset user id 11
hget user id
hmset customer id 11 name sam age 26
hmget customer id name age
hgetall customer
hdel user id

2.hlen
求哈希长度
hlen customer
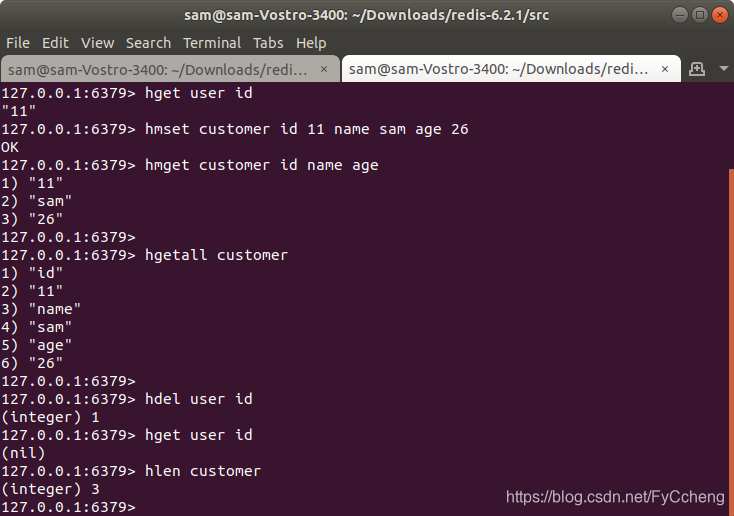
3.hexists key
hexists ---- 在key里面的某个值
存在返回1 ,不存在返回0
hexists customer name > 1
hexists customer age > 1
hexists customer high > 0
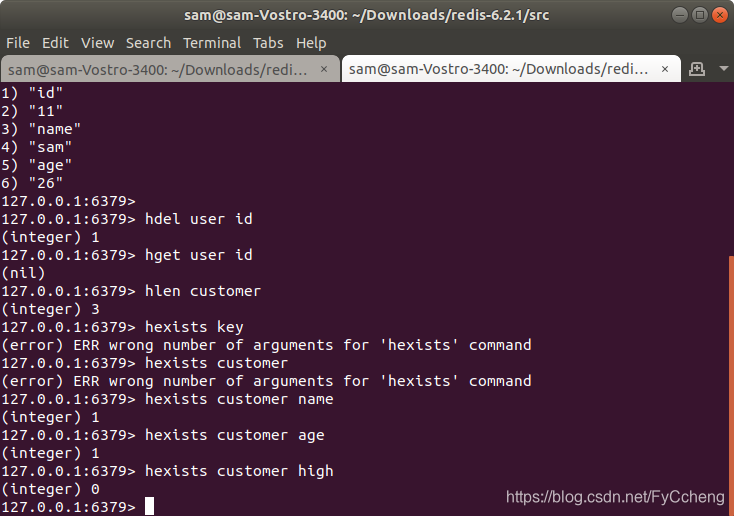
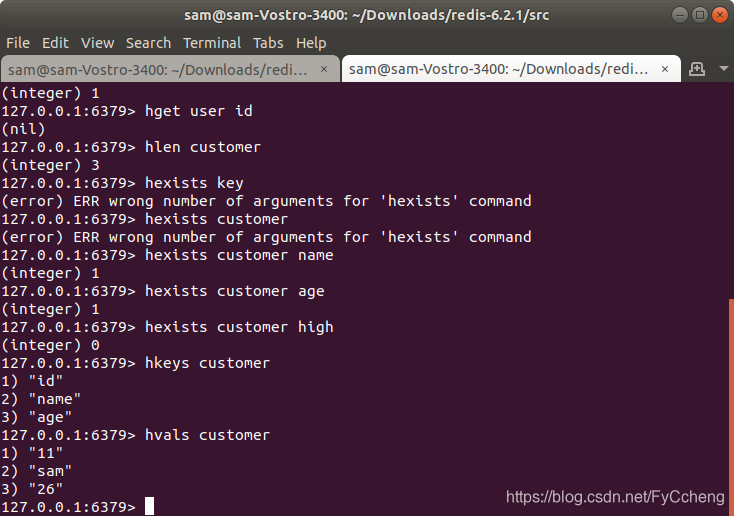
4.hkeys/hvals 查看Hash的字段和值
hkeys customer -> 查看所有字段
hvals customer -> 查看所有值
总结:hash的运用场景,例如:购物车(哪个用户添加了什么商品 添加购物车多少件)——>(用户、商品、数量)
carts user id :{goods id: count, goods id:count}
carts 1: {2(things1),3(things2)}
1.2 redis-set(不重复的)
Set(集合)
set是string类型的无序集合

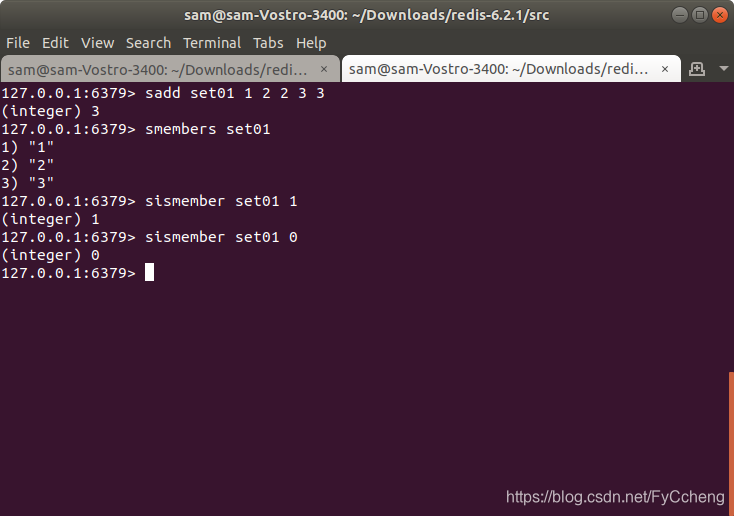
1.sadd/smembers/sismember
sadd/smembers/sismember ---- 添加/查看集合/查看是否存在
sadd set01 1 2 2 3 3 去掉重复添加
smembers set01 得到set01
sismember set01 1 如果存在返回1 不存在返回0
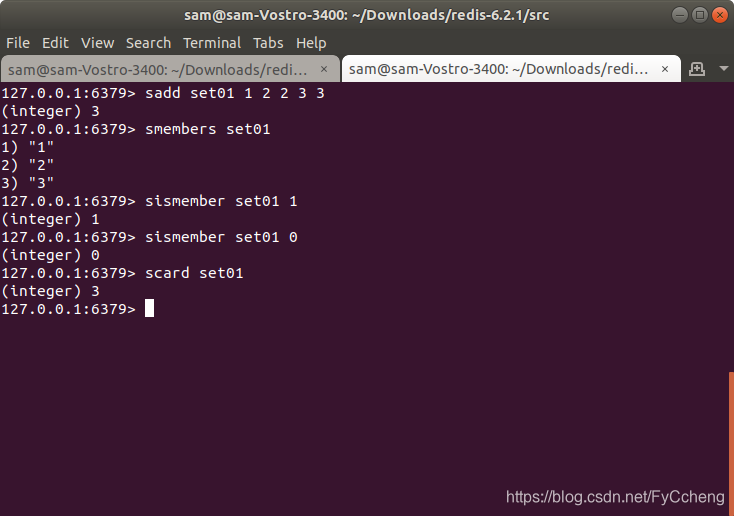
2.scard
scard ---- 获取集合里面的元素个数
scard set01
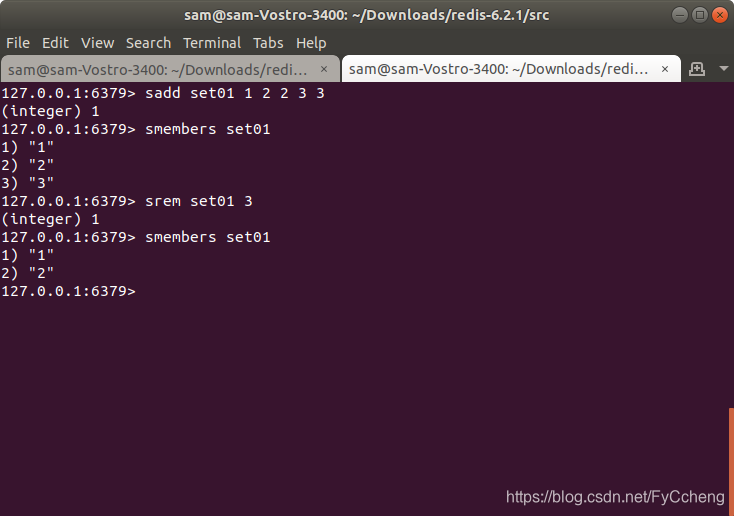
3.srem key value
srem ---- 删除集合中元素
srem set01 3
smember set01 3已经被删除掉
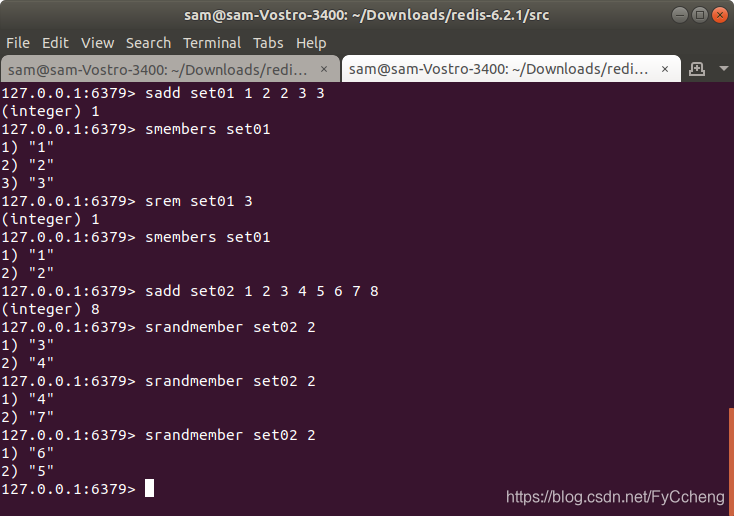
4.srandmember key
srandmembe ---- 随机出几个数
sadd set02 1 2 3 4 5 6 7 8
srandmember set02 2
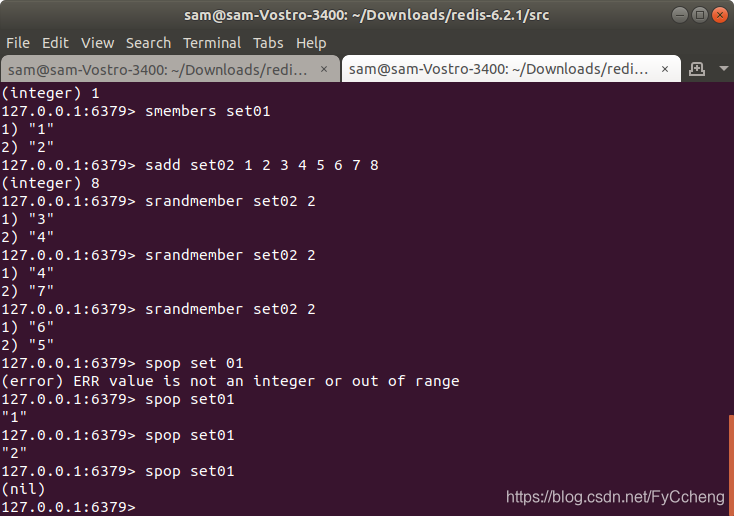
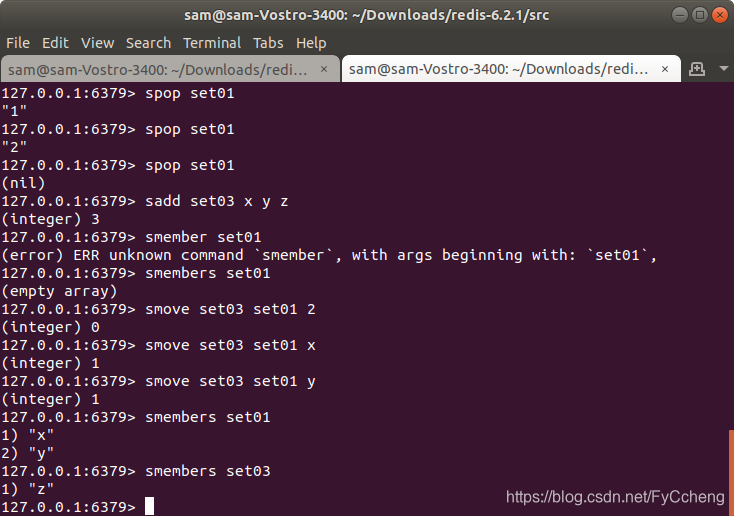
5.spop key
spop ---- 随机出栈
spop set01
6.smove key1 key2
sadd set03 x y z
smove set03 set01 x 将set03中的x 移动到set02中
7.数学集合类
sadd set01 1 2 3 4 5
sadd set02 1 2 3 a b
差集
SDIFF set01 set02 返回 4 5 在第一个set中不在第二个set中
交集
SINTER set01 set02 返回 1 2 3
并集
SUNION set01 set02 返回set01 set02 中的值 去掉重复
总结:运用场景,例如:抽奖100人,利用spop随机出数。
1.3 redis-Zset
Zset(有序集合)
有序集合类型(Sorted Set)相比与集合多了一个排序属性score(分值),对于有序集合ZSet来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值,有序集合的存储元素值也是不能重复的,但分值是可以重复的。

存储值: 老王 老李 老钱
分值:100 60 80
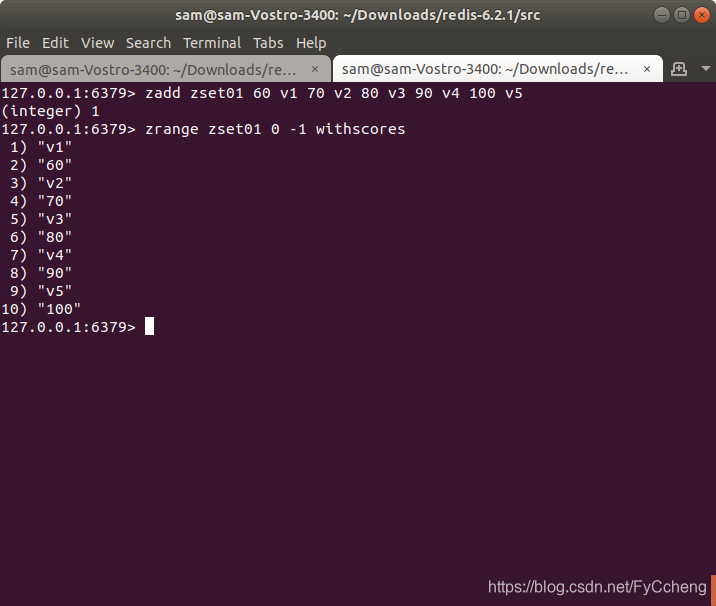
1.zadd/zrange
zadd zset01 60 v1 70 v2 80 v3 90 v4 100 v5
zrange zset01 0 -1
带分数返回 withscores
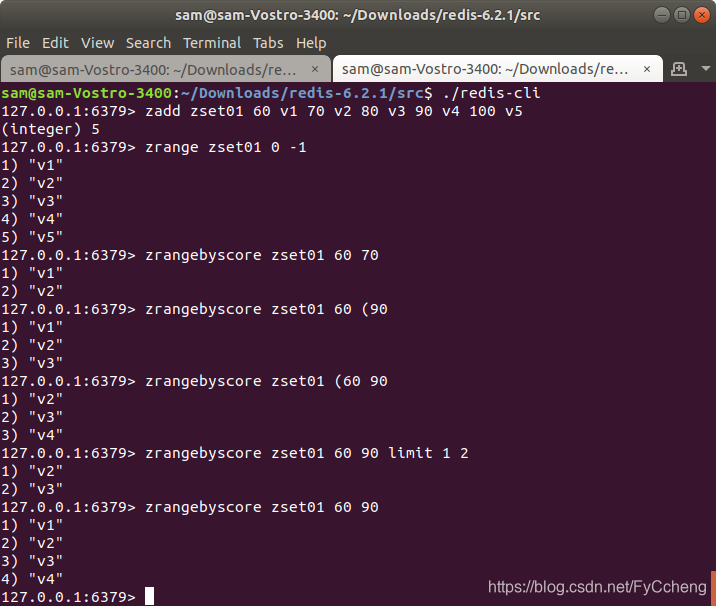
2.zrangebyscore key start end
zrangebyscore key start end----根据开始结束来取值
zrangebyscore zset01 60 70
zrangebyscore zset01 60 (90 表示不包含90
zrangebyscore zset01 (60 90 表示不包含60
zrangebyscore zset01 (60 (90 表示不包含60
zrangebyscore zset01 60 90 limit 1 2 从第一条开始截取2条
zrangebyscore zset01 60 90
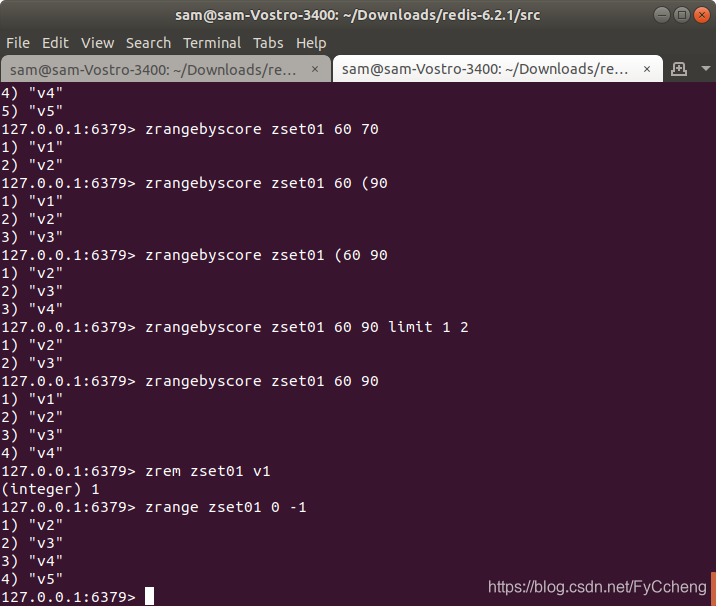
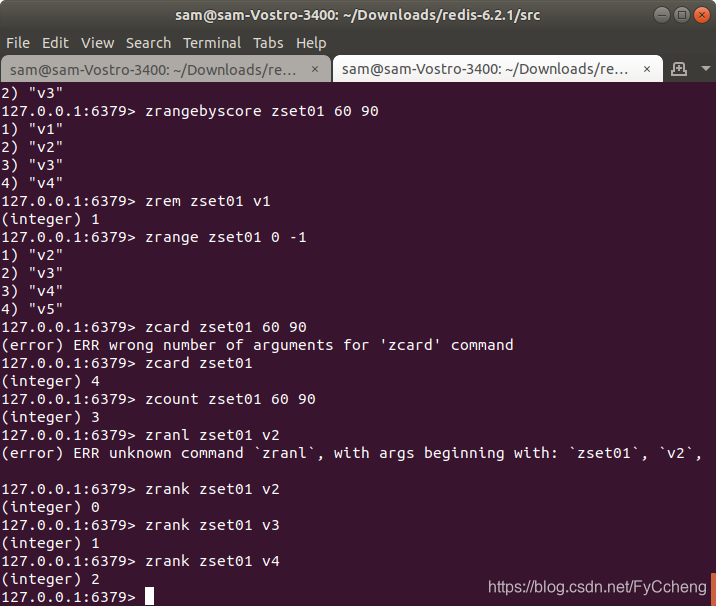
3.zrem key
zrem key value---- 某score下对应的value值,作用是删除元素
zrem zset01 v1
zrange zset01 0 -1
4.zcard/zcount key score 区间/zrank key values
zcard 求zset01 总条数
zcount zset01 60 90 求60-90个数
zrank zset01 v2 返回1 返回对应下角标,从0开始
2. Python操作Redis
2.1 redis安装及连接
安装Redis扩展
$ pip install redis
连接
r = redis.StrictRedis(host='localhost',port=6379,db=0)
基础测试
import redis
class RedisString(object):
"""Redis字符串类型"""
def __init__(self):
self.r = redis.StrictRedis(host='127.0.0.1',port=6379)
def redis_string_set(self, name, value):
self.r.set(name, value)
if __name__ == "__main__":
rs = RedisString()
rs.redis_string_set('name', 'sam')
2.2 字符串相关操作
import redis
class TestString(object):
def __init__(self):
self.r = redis.StrictRedis(host='192.168.75.130',port=6379)
设置值
def test_set(self):
res = self.r.set('user1','juran-1')
print(res)
取值
def test_get(self):
res = self.r.get('user1')
print(res)
设置多个值
def test_mset(self):
d = {
'user2':'juran-2',
'user3':'juran-3'
}
res = self.r.mset(d)
取多个值
def test_mget(self):
l = ['user2','user3']
res = self.r.mget(l)
print(res)
删除
def test_del(self):
self.r.delete('user2')
2.3 列表相关操作
class TestList(object):
def __init__(self):
self.r = redis.StrictRedis(host='192.168.75.130',port=6379)
插入记录
def test_push(self):
res = self.r.lpush('common','1')
res = self.r.rpush('common','2')
# res = self.r.rpush('jr','123')
弹出记录
def test_pop(self):
res = self.r.lpop('common')
res = self.r.rpop('common')
范围取值
def test_range(self):
res = self.r.lrange('common',0,-1)
print(res)
2.4 集合相关操作
class TestSet(object):
def __init__(self):
self.r = redis.StrictRedis(host='192.168.75.130', port=6379)
添加数据
def test_sadd(self):
res = self.r.sadd('set01','1','2')
lis = ['Cat','Dog']
res = self.r.sadd('set02',lis)
删除数据
def test_del(self):
res = self.r.srem('set01',1)
随机删除数据
def test_pop(self):
res = self.r.spop('set02')
2.5 哈希相关操作
class TestHash(object):
def __init__(self):
self.r = redis.StrictRedis(host='192.168.75.130', port=6379)
批量设值
def test_hset(self):
dic = {
'id':1,
'name':'huawei'
}
res = self.r.hmset('mobile',dic)
批量取值
def test_hgetall(self):
res = self.r.hgetall('mobile')
判断是否存在 存在返回1 不存在返回0
def test_hexists(self):
res = self.r.hexists('mobile','id')
print(res)
3. 主从概念
主从同步(主从复制)是Redis高可用服务的基石,也是多机运行中最基础的一个。我们吧吧主要存储数据的节点叫做主节点(master),把其他通过服饰主节点数据的副本节点叫做从节点(slave)
- ⼀个master可以拥有多个slave,⼀个slave⼜可以拥有多个slave,如此下去,形成了强⼤的多级服务器集群架构
- master用来写数据,slave用来读数据,经统计:网站的读写比率是10:1
- 通过主从配置可以实现读写分离
- master和slave都是一个redis实例(redis服务)
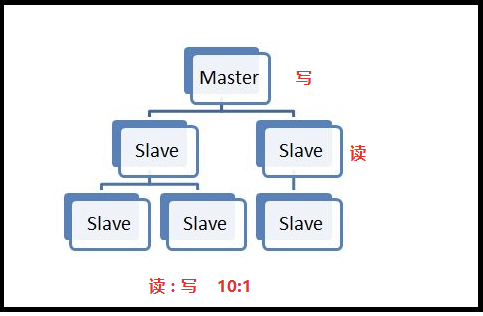
主从同步具有以下三个优点:
- 性能方面:有了主从同步之后,可以把查询任务分配给从服务器,用主服务器来执行写操作,这样极大的提高了程序运行的效率,把所有压力分摊到各个服务器。
- 高可用:当有了主从同步之后,当主服务器节点宕机之后,可以很迅速的把从节点提升为主节点,为Redis服务器的宕机回复节省了时间。
- 防止数据丢失:当主服务器磁盘坏掉之后,其他从服务器还保留着相关的数据,不至于数据全部丢失。
3.1主从配置
-
配置主
-
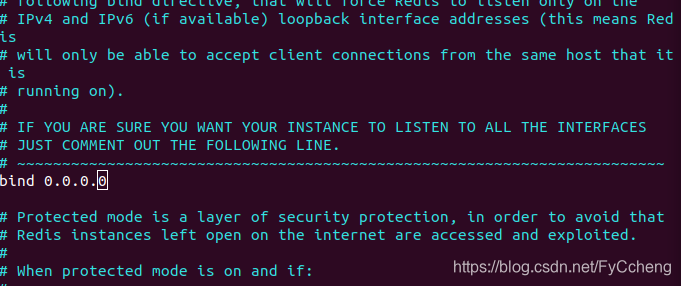
修改etc/redis/redis.conf文件
bind 0.0.0.0 或者改成本机IP
开启主机服务
src/redis-server redis.conf
3.2 配置从
- 复制etc/redis/redis.conf文件
cp redis.conf slave.conf
- 修改redis/slave.conf文件
vim slave.conf
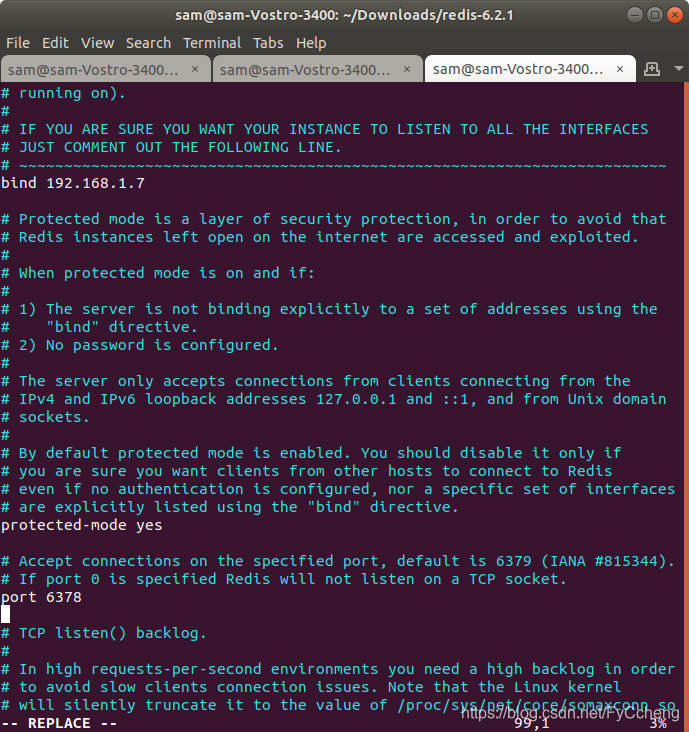
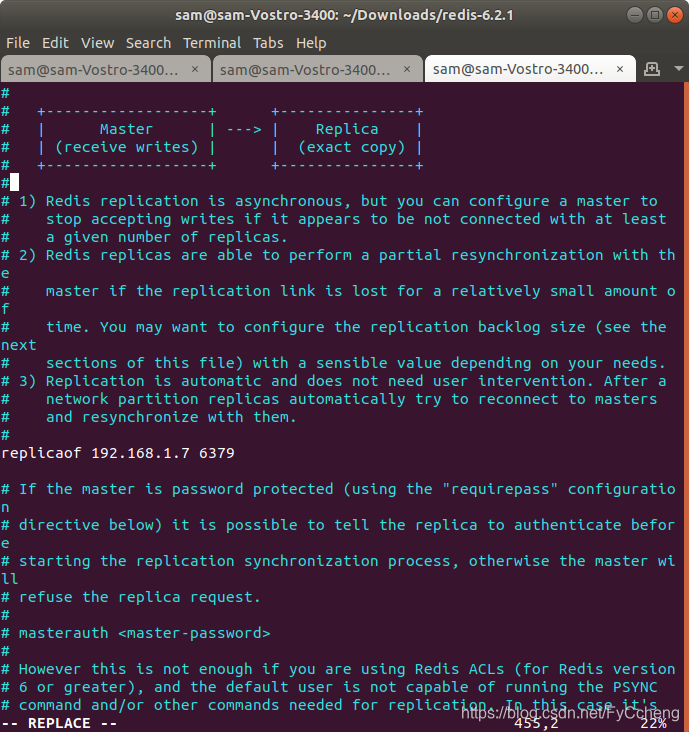
bind 192.168.1.7(主机IP)
slaveof 192.168.1.7(主机IP) 6379(主机端口) windows系统
replicaof 192.168.1.7(主机IP) 6379(主机端口) linux系统
port :6378(从机端口)
开启主机服务
src/redis-server slave.conf
$ ps aux | grep redis

可以发现已经开启了两个redis
3.3 数据操作
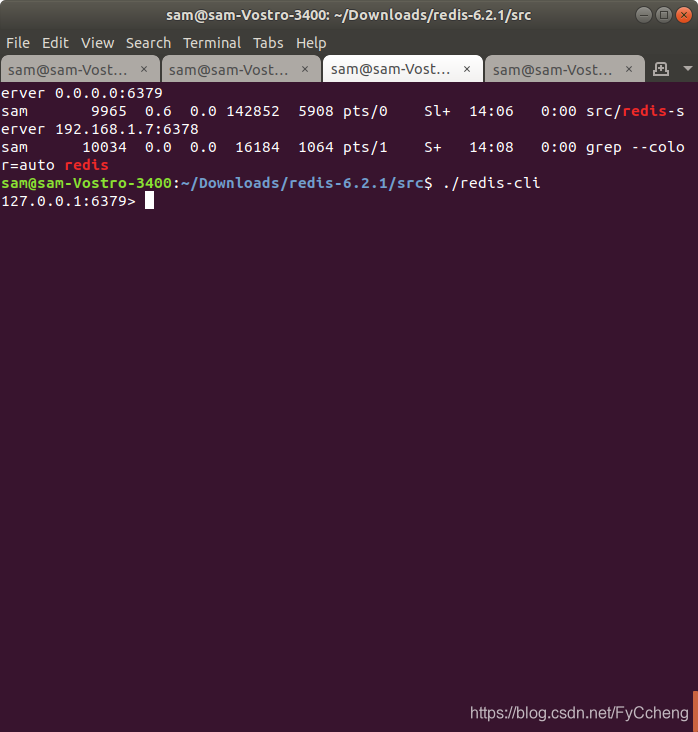
- 在master和slave分别执⾏info命令,查看输出信息 进入主客户端
src/redis-cli -h 192.168.1.7 -p 6379
src/redis-cli
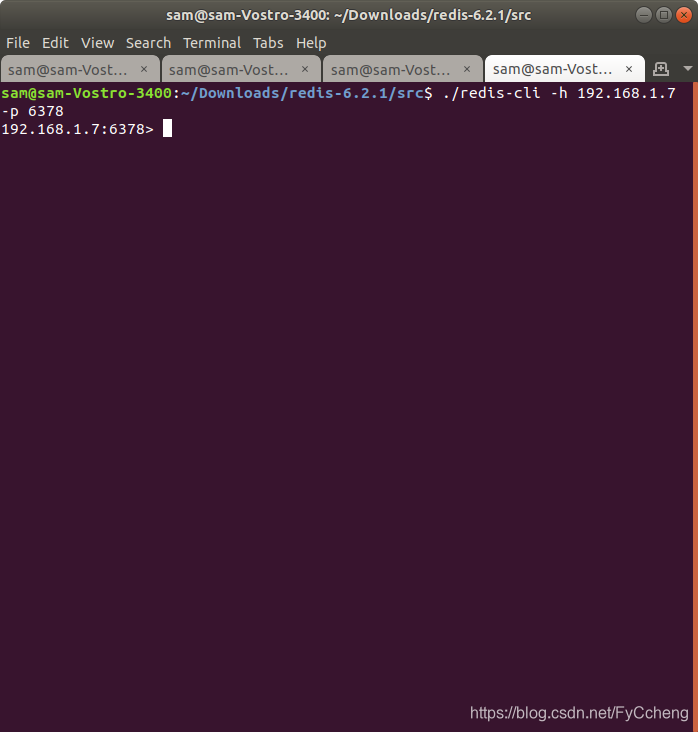
进入从的客户端
src/redis-cli -h 192.168.1.7 -p 6378
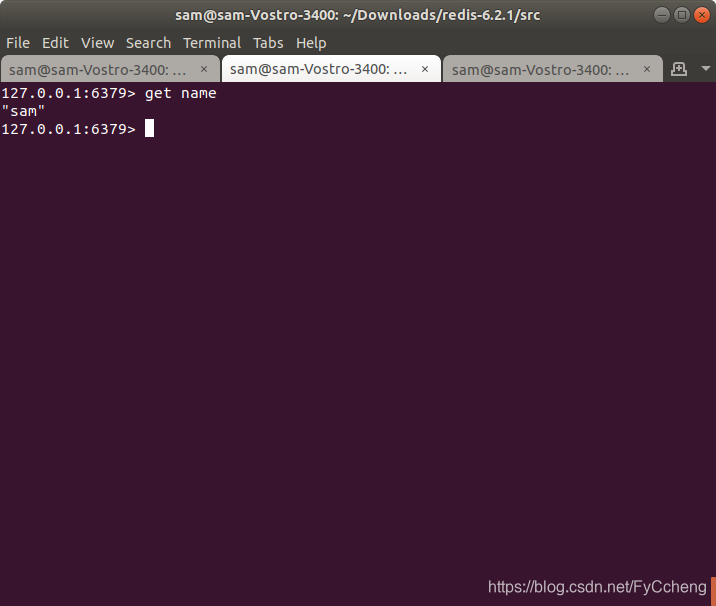
- 在master上写数据
set name sam
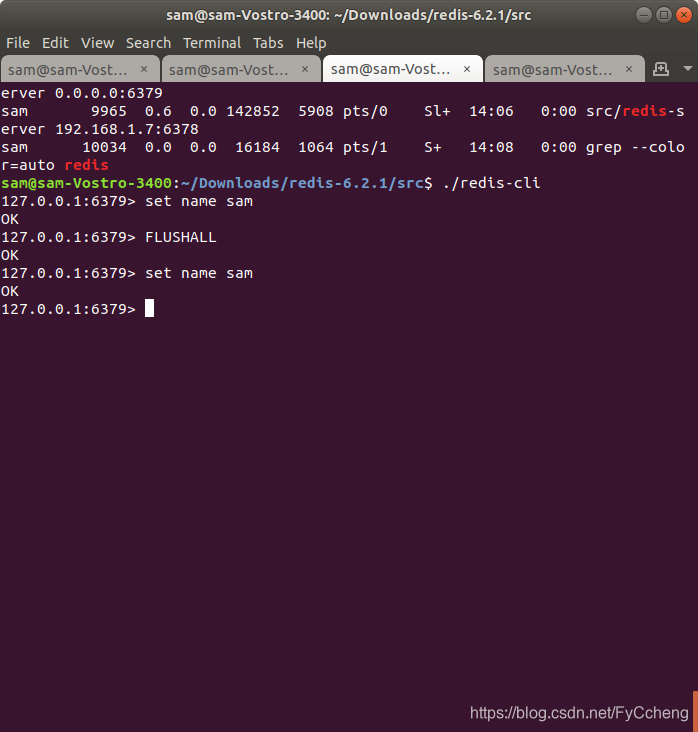
- 在slave上读数据
get name
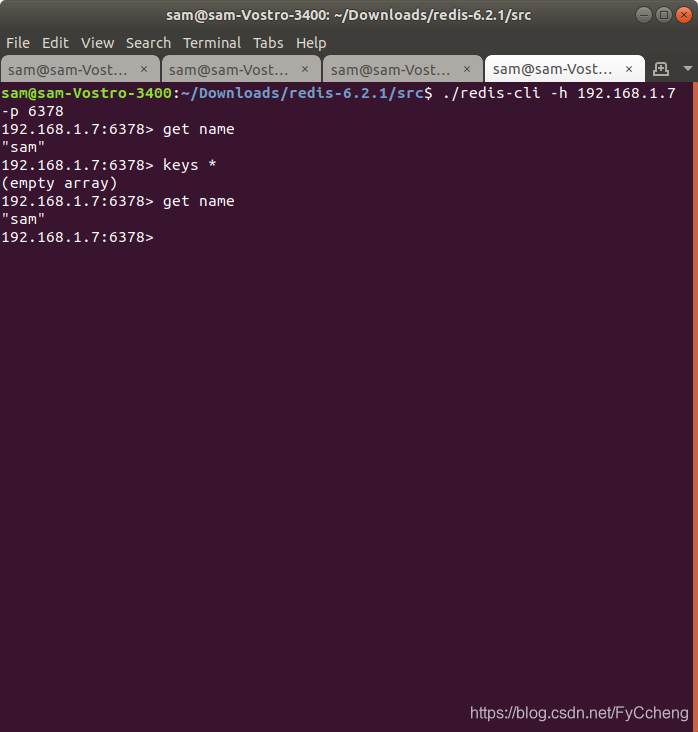
3.4 注意
数据一致性问题:
当从服务器已经完成和主服务的数据同步之后,再新增的命令会以异步的方式发送值从服务器,在这个过程中主从同步会有短暂的数据不一致,如在这个异步同步发生之前主服务器宕机了,会造成数据不一致。
从服务器只读性:
在默认情况下,处于复制模式的主服务器既可以执行写操作也可以执行读操作,而从服务器则只能执行读操作。
复制命令的变化:
Redis 5.0 之前使用的复制命令是slaveof ,在redis 5.0 之后的复制命令才被改为replicaof,在高版本(Redis 5+ )中我们应该尽量使用 replicaof,因为slaveof 命令可能会被随时废弃。
4. Redis 持久化—RDB
Redis 的读写都是在内存中,所以它的性能较高,但在内存中的数据会随着服务器的重启而丢失,为了保证数据不丢失,我们需要将内存中的数据存储到磁盘,以便 Redis 重启时能够从磁盘中恢复原有的数据,而整个过程就叫做 Redis 持久化。
持久化的几种方式
Redis 持久化拥有以下三种方式:
- 快照方式(RDB, Redis DataBase)将某一个时刻的内存数据,以二进制的方式写入磁盘;
- 文件追加方式(AOF, Append Only File),记录所有的操作命令,并以文本的形式追加到文件中;
- 混合持久化方式,Redis 4.0 之后新增的方式,混合持久化是结合了 RDB 和 AOF 的优点,在写入的时候,先把当前的数据以 RDB 的形式写入文件的开头,再将后续的操作命令以 AOF 的格式存入文件,这样既能保证 Redis 重启时的速度,又能减低数据丢失的风险。
RDB简介
RDB(Redis DataBase)是将某一个时刻的内存快照(Snapshot),以二进制的方式写入磁盘的过程。
持久化触发
RDB 的持久化触发方式有两类:一类是手动触发,另一类是自动触发。
手动触发
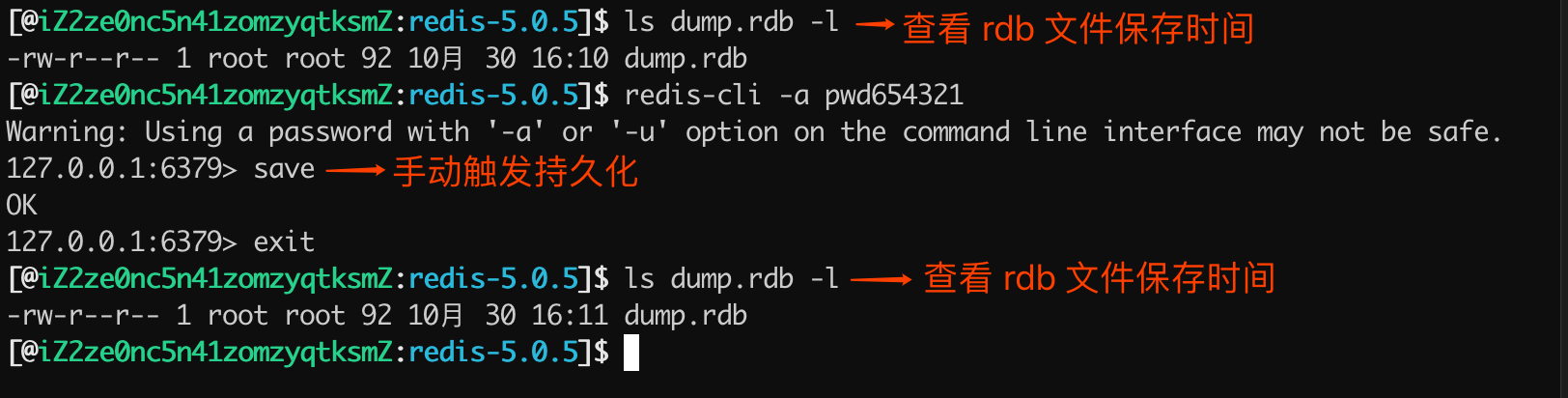
手动触发持久化的操作有两个: save 和 bgsave ,它们主要区别体现在:是否阻塞 Redis 主线程的执行。
① save 命令 在客户端中执行 save 命令,就会触发 Redis 的持久化,但同时也是使 Redis 处于阻塞状态,直到 RDB 持久化完成,才会响应其他客户端发来的命令,所以在生产环境一定要慎用。
② bgsave 命令 bgsave(background save)既后台保存的意思, 它和 save 命令最大的区别就是 bgsave 会 fork() 一个子进程来执行持久化,整个过程中只有在 fork() 子进程时有短暂的阻塞,当子进程被创建之后,Redis 的主进程就可以响应其他客户端的请求了,相对于整个流程都阻塞的 save 命令来说,显然 bgsave 命令更适合我们使用。
自动触发
RDB 的手动触发方式,下面来看如何自动触发 RDB 持久化? RDB 自动持久化主要来源于以下几种情况。
① save m n save m n 是指在 m 秒内,如果有 n 个键发生改变,则自动触发持久化。 参数 m 和 n 可以在 Redis 的配置文件中找到,例如,save 60 1 则表明在 60 秒内,至少有一个键发生改变,就会触发 RDB 持久化。 自动触发持久化,本质是 Redis 通过判断,如果满足设置的触发条件,自动执行一次 bgsave 命令。 注意:当设置多个 save m n 命令时,满足任意一个条件都会触发持久化。
② flushall flushall 命令用于清空 Redis 数据库,在生产环境下一定慎用,当 Redis 执行了 flushall 命令之后,则会触发自动持久化,把 RDB 文件清空
配置说明
# RDB 保存的条件
save 900 1
save 300 10
save 60 10000
# bgsave 失败之后,是否停止持久化数据到磁盘,yes 表示停止持久化,no 表示忽略错误继续写文件。
stop-writes-on-bgsave-error yes
# RDB 文件压缩
rdbcompression yes
# 写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
rdbchecksum yes
# RDB 文件名
dbfilename dump.rdb
# RDB 文件目录
dir ./
其中比较重要的参数如下列表:
① save 参数 它是用来配置触发 RDB 持久化条件的参数,满足保存条件时将会把数据持久化到硬盘。 默认配置说明如下:
- save 900 1:表示 900 秒内如果至少有 1 个 key 值变化,则把数据持久化到硬盘;
- save 300 10:表示 300 秒内如果至少有 10 个 key 值变化,则把数据持久化到硬盘;
- save 60 10000:表示 60 秒内如果至少有 10000 个 key 值变化,则把数据持久化到硬盘。
② rdbcompression 参数 它的默认值是 yes 表示开启 RDB 文件压缩,Redis 会采用 LZF 算法进行压缩。如果不想消耗 CPU 性能来进行文件压缩的话,可以设置为关闭此功能,这样的缺点是需要更多的磁盘空间来保存文件。
③ rdbchecksum 参数 它的默认值为 yes 表示写入文件和读取文件时是否开启 RDB 文件检查,检查是否有无损坏,如果在启动是检查发现损坏,则停止启动。
配置查询
Redis 中可以使用命令查询当前配置参数。查询命令的格式为:config get xxx ,例如,想要获取 RDB 文件的存储名称设置,可以使用 config get dbfilename
RDB 优缺点
1)RDB 优点
- RDB 的内容为二进制的数据,占用内存更小,更紧凑,更适合做为备份文件;
- RDB 对灾难恢复非常有用,它是一个紧凑的文件,可以更快的传输到远程服务器进行 Redis 服务恢复;
- RDB 可以更大程度的提高 Redis 的运行速度,因为每次持久化时 Redis 主进程都会 fork() 一个子进程,进行数据持久化到磁盘,Redis 主进程并不会执行磁盘 I/O 等操作;
- 与 AOF 格式的文件相比,RDB 文件可以更快的重启。
2)RDB 缺点
- 因为 RDB 只能保存某个时间间隔的数据,如果中途 Redis 服务被意外终止了,则会丢失一段时间内的 Redis 数据;
- RDB 需要经常 fork() 才能使用子进程将其持久化在磁盘上。如果数据集很大,fork() 可能很耗时,并且如果数据集很大且 CPU 性能不佳,则可能导致 Redis 停止为客户端服务几毫秒甚至一秒钟。

















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









