




 本文深入解析Kafka的架构,包括分布式消息系统的组件如Broker、Producer、Consumer和ZooKeeper的作用,以及消息的存储机制和消费模型。探讨了Kafka的特性,如高性能、持久性、灵活性和分布式特性。
本文深入解析Kafka的架构,包括分布式消息系统的组件如Broker、Producer、Consumer和ZooKeeper的作用,以及消息的存储机制和消费模型。探讨了Kafka的特性,如高性能、持久性、灵活性和分布式特性。
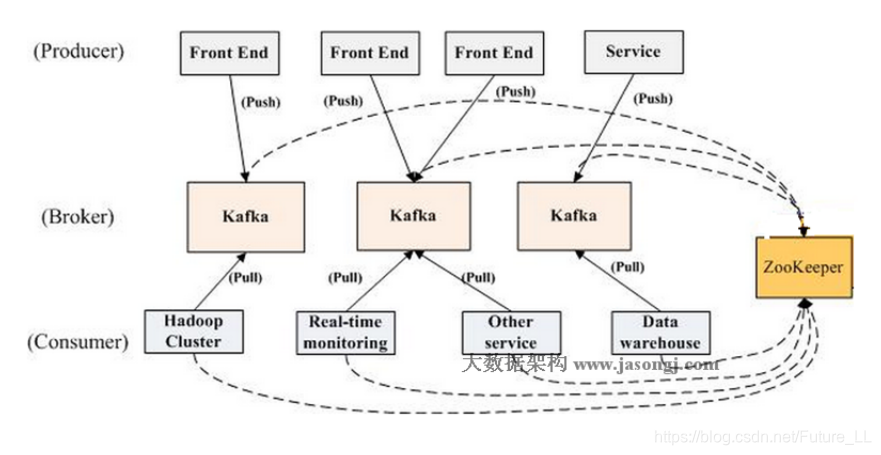
整体架构
- Kafka:分布式消息系统,将消息直接存入磁盘,默认保存一周
- Broker:接收Producer发过来的数据,并且将它持久化,同时提供给Consumer去订阅
- 组成Kafka集群节点,之间没有主从关系,依赖ZooKeeper来协调,broker负责消息的读取和存储,一个broker可以管理多个partition
- Producer:发布者,自己决定向那个partition中去生产消息,两种机制:hash、轮询
- Consumer:订阅者,订阅并获取数据,提供给外部系统去使用,一个consumer只能读取一个partition分区的数据
- consumer通过ZooKeeper去维护消费者偏移量。consumer有自己的消费者组,不同组之间消费同一个topic数据,互不影响,相同组内的不同的consumer消费同一个topic,这个topic中相同的数据只能被消费一次
- ZooKeeper:协调Kafka Broker,存储原数据:consumer的offset+broker信息+topic信息+partition个信息。
- Push And Pull:
- 作为一个messaging system,Kafka遵循了传统的方式,选择由producer向broker push消息并由consumer从broker pull消息。一些logging-centric system,比如Facebook的Scribe和Cloudera的Flume,采用非常不同的push模式。事实上,push模式和pull模式各有优劣。
- Push:push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞
- Pull:pull模式则可以根据consumer的消费能力去从broker拿数据,很大程度上避免了应用程序别压垮,尤其是在峰值流量的情况下,同时设计会特别简单,尤其是broker的设计,它并不需要感知consumer的存在,也不需要知道有多少consumer,每个consumer订阅什么样的topic
- Producer如何知道应该将这条数据发送给那个Broker
- Producer就是通过Partition去判断,应该将那条消息发送给那个Broker
- Producer是如何获取整个Broker集群的原信息
- 上图Broker和Consumer使用了ZooKeeper,从Kafka0.8版本开始Pro杜尔不在依赖于ZooKeeper去获取整个集群的信息,在实例化Producer的时候,可以指定一个或多个Broker的URL或者IP和Port的组合,比如集群有三百个Broker,但是我们只指定三个Broker的IP和端口号给Producer,Producer就会根据这三个Broker的先后,分别取连接这三个Broker,只要有一个连接成功,他就可以从Broker里面拿到整个集群当前还活着的或者正常工作的Broker的列表以及相关的原信息,从而将它返回给Producer,这是Producer就知道整个集群有多少个Broker,每个Topic有多少个Partition,每个Partition分别在那个Broker上面,Producer会将原信息存到Producer的内存当中
注意:如果某个Broker挂掉了或者Producer发送消息给Broker失败了
- 我们需要维护Producer缓存的Broker【或者整个集群】的原信息,刷新原信息有两种机制
- Producer向某个Broker发送数据失败之后,他会主动触发刷新原信息的操作,重新获取当前整个集群的原信息,因为Producer发送数据给Broker失败,很有可能是网络不通或者Broker掉了,这个时候需要去刷新Producer缓存的Broker原信息。
- Producer可以周期性的去刷新缓存的原信息,刷新周期可以通过Producer的配置参数配置,可以在Producer实例化的时候指定它
- Consumer是如何获取整个Broker集群的原信息
- Consumer是通过连接ZooKeeper,也就是说,我们实例化Consumer的时候,需要去指定一个或多个ZooKeeper的IP和Port,我们都知道整个集群的原信息都会存到ZooKeeper里面,Consumer只要去连接了ZooKeeper,他就可以知道整个集群有多少个Topic,每个Topic在那个Broker上面
- Broker如何知道那条消息应该发送到那个Broker上面
- Consumer如何判断我应该从那个Broker上面去消费数据
- 上述两个问题与Topic与Partition有关,订阅、发布都会显示的指定Topic,Consumer也可以设定白名单、黑名单指定希望去消费或者不消费那些Topic的数据
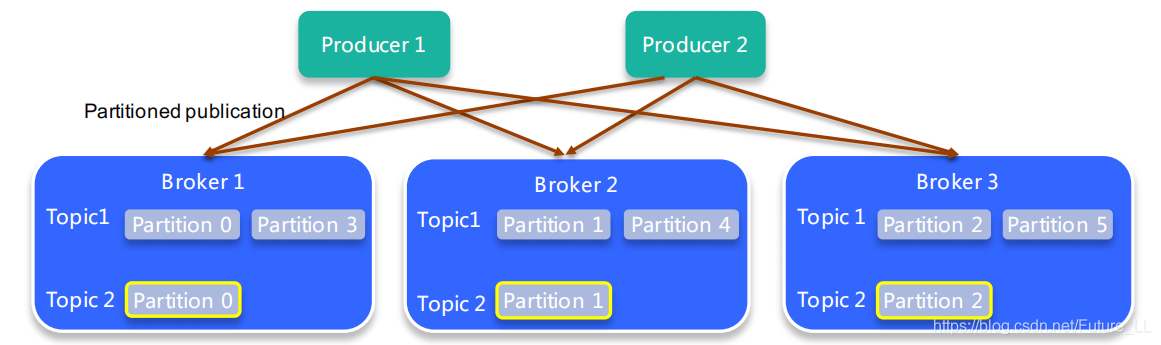
Topic & Partition
Topic【一类消息的总称 / 一个消息队列】
- 逻辑概念,同一个Topic的消息可分布在一个或多个节点(Broker)上
- 一个Topic包含一个或者多个Partition【Topic存储消息存储在Partition上,有多少个创建时候指定】
- 每个partition内部消息强有序,其中的每个消息都有一个序号叫offset
- 一个partition只对应一个broker,一个broker可以管多个partition
- 每条消息都属于且仅属于一个Topic
- 消息直接写入文件,并不是存储在内存中
- 根据时间策略(默认一周)删除,而不是消费完就删除
- Producer发布数据时,必须指定将该消息发布到哪一个Topic
- Consumer订阅消息时,也必须指定订阅哪个Topic的消息
Partition【提高并行度】
- 组成 topic 的单元,每个 partition 都有副本,有多少?创建时候指定。
- 每个 partition 只能由一个 broker 来管理,这个 broker 是这个 partition 的 leader
- 物理概念,一个Partition只分布于一个Broker上(不考虑备份)
- 一个Partition物理上对应一个文件夹【直接写入磁盘,数据不会丢】
- 一个Partition包含多个Segment(Segment对用户透明)
- 一个Segment对应一个文件
- Segment由一个个不可变记录组成
- 记录只会被append到Segment中,不会被单独删除或者修改
- 清除过期日志时,直接删除一个或多个Segme
- producer自己决定往哪个partition写消息,可以是轮询的负载均衡,或者是基于hash的partition策略
- 生产的消息是<key,value>形式的,基于hash的partition策略是将key的hash值余3,得到要存的partition编号,这个策略是partition默认的策略
- 第二种是轮询的方式,第一次进来是partition 0,第二次就partition 1,第三次是partition 2,第四次是partition 0,一次类推
-
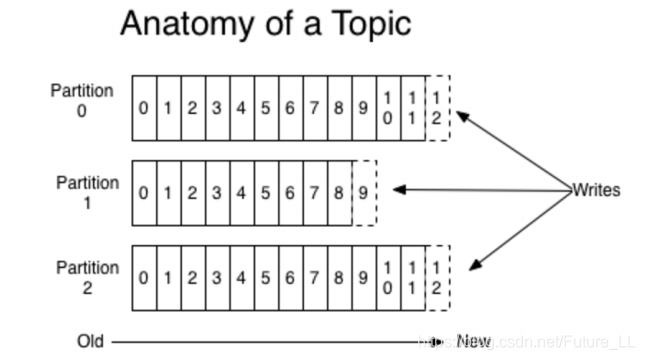
kafka的消息存储和生产消费模型
- kafka里面的消息是有topic来组织的,简单的我们可以想象为一个队列,一个队列就是一个topic,然后它把每个topic又分为很多个partition,这个是为了做并行的,在每个partition里面是有序的,相当于有序的队列,其中每个消息都有个序号,比如0到12,从前面读往后面写
- 一个partition对应一个broker,一个broker可以管多个partition,比如说,topic有6个partition,有两个broker,那每个broker就管3个partition
- 这个partition可以很简单想象为一个文件,当数据发过来的时候它就往这个partition上面append,追加就行,kafka和很多消息系统不一样,很多消息系统是消费完了我就把它删掉,而kafka是根据时间策略删除,而不是消费完就删除,在kafka里面没有一个消费完这么个概念,只有过期这样一个概念
- -------------------------------------------------------------------
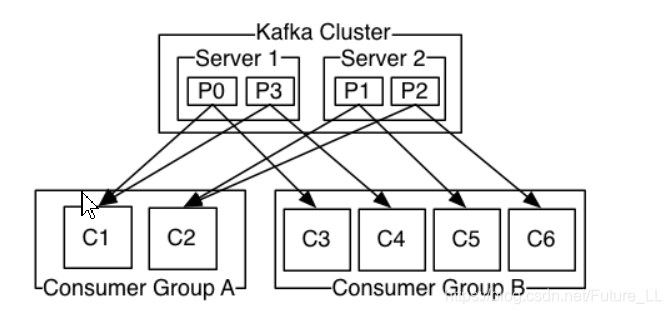
- consumer自己维护消费到哪个offset【消费到partition的offset由consumer交给ZooKeeper去维护】
- 每个consumer都有对应的group
- group内是queue消费模型
- 各个consumer消费不同的partition【也就是说相同的消息只能被消费一次】
- 一个消息在group内只消费一次
- 依次去消费,不是一起消费,先p0,再p3,再p1,再p2
- 如果在消费过程中,C1与p0断开,那么C2可以消费p0,只是消费的位置是C1断开前消费的位置
- 各个group各自独立消费,互不影响
kafka有哪些特点
- 消息系统的特点:生存者消费者模型,FIFO
- partition内部是FIFO的,partition之间呢不是FIFO的,当然我们可以
把topic设为一个partition,这样就是严格的FIFO- 高性能:单节点支持上千个客户端,百MB/s吞吐
- 持久性:消息直接持久化在普通磁盘上且性能好
- 直接写到磁盘里面去,就是直接append到磁盘里面去,这样的好处是
直接持久话,数据不会丢,第二个好处是顺序写,然后消费数据也是
顺序的读,所以持久化的同时还能保证顺序读写- 分布式:数据副本冗余、流量负载均衡、可扩展
- 分布式,数据副本,也就是同一份数据可以到不同的broker上面去,
也就是当一份数据,磁盘坏掉的时候,数据不会丢失,比如3个副本,
就是在3个机器磁盘都坏掉的情况下数据才会丢- 很灵活:消息长时间持久化+Client维护消费状态
- 消费方式非常灵活,第一原因是消息持久化时间跨度比较长,一天或
者一星期等,第二消费状态自己维护消费到哪个地方了,可以自定义
消费偏移量
Partitioner
- Producer在发送一条消息,需要决定这条消息应该发送到具体哪个Broker上面去
- 对于指定消息的key,返回这条消息应该被发送到那个Partition
- 取key的hash值,还会对Partition总数取余,这样的好处是,key相同的数据会被发送到同一个Broker中
- 不管key是什么样子,对于发送过来的消息,如果第一条消息被发送到第0个Partition,那么第二个就发送到第1个partition,依次类推循环处理
- 它不会引起线程安全问题,incrementAndGet() 是线程安全的


同步(Sync)Producer和异步(Aync)Producer
Sync Producer
消息发送过去之后,只有发送成功,我们才发送下一条数据,如果发送失败,它会不停的Retry,三次不成功就失败抛出异常,这个时候我们选择忽略这条,不过不太推荐
- 低延迟
- 低吞吐率
- 无数据丢失
Aync Producer
每次数据使用了send方法之后,它并不是真正的被发送出去了,而是说它里面有一个Queue,每次发送都是入队,会有一个后台线程不停的从Queue中拿数据,发送给Broker,这个发送过程是一个批量过程,因此效率比较高,但是会有延迟
- 高延迟:不会对每条数据直接真实发送
- 高吞吐率:发送是一个批量的过程
- 可能会有数据丢失:如果Queue满了,并且阻塞了一定时间,它会选择将新的数据直接丢掉

















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









