




目录
- 一、数仓分层
- 二、数仓理论
- 三、数仓环境搭建
- 四、数仓搭建-ODS层
-
- 4.1 ODS层(用户行为数据)
- 4.2 ODS层(业务数据)
-
- 4.2.1 活动信息表
- 4.2.2 活动规则表
- 4.2.3 一级品类表
- 4.2.4 二级品类表
- 4.2.5 三级品类表
- 4.2.6 编码字典表
- 4.2.7 省份表
- 4.2.8 地区表
- 4.2.9 品牌表
- 4.2.10 购物车表
- 4.2.11 评论表
- 4.2.12 优惠券信息表
- 4.2.13 优惠券领用表
- 4.2.14 收藏表
- 4.2.15 订单明细表
- 4.2.16 订单明细活动关联表
- 4.2.17 订单明细优惠券关联表
- 4.2.18 订单表
- 4.2.19 退单表
- 4.2.20 订单状态日志表
- 4.2.21 支付表
- 4.2.22 退款表
- 4.2.23 商品平台属性表
- 4.2.24 商品(SKU)表
- 4.2.25 商品销售属性表
- 4.2.26 商品(SPU)表
- 4.2.27 用户表
- 4.2.28 ODS层业务表首日数据装载脚本
- 4.2.29 ODS层业务表每日数据装载脚本
- 五、数仓搭建-DIM层
- 六、数仓搭建-DWD层
-----------------------------------------------------分隔符-----------------------------------------------------
数据仓库之电商数仓-- 1、用户行为数据采集==>
数据仓库之电商数仓-- 2、业务数据采集平台==>
数据仓库之电商数仓-- 3.1、电商数据仓库系统(DIM层、ODS层、DWD层)==>
数据仓库之电商数仓-- 3.2、电商数据仓库系统(DWS层)==>
数据仓库之电商数仓-- 3.3、电商数据仓库系统(DWT层)==>
数据仓库之电商数仓-- 3.4、电商数据仓库系统(ADS层)==>
数据仓库之电商数仓-- 4、可视化报表Superset==>
数据仓库之电商数仓-- 5、即席查询Kylin==>
一、数仓分层
1.1 为什么要分层
数仓分层

总结⭐️:
⭐️数据仓库分层:
ODS(Operation Data Store)层: 原始数据层,存放原始数据。直接加载原始日志、数据,数据保持原貌不做处理;
DWD(Data Warehouse Detail)层: 对ODS层数据进行清洗(去除空值、脏数据、超过极限范围的数据)、脱敏等,保存业务事实明细,一行信息代表一次业务行为,例如一次下单行为;
DIM(Dimension)层: 维度层,保存维度数据,主要是对业务事实的描述信息,如何人何处何地等;
DWS(Data Warehouse Service)层: 以DWD层为基础,按天进行轻度汇总。一行信息代表一个主题对象一天的汇总行为,如一个用户一天下单次数;
DWT(Data Warehouse Topic)层: 以DWS层为基础,对数据进行累积汇总。一行信息代表一个主题对象的累积行为,例如一个用户从注册开始至今下了多少单;
ADS(Application Data Store)层: 为各种统计报表提供数据。
⭐️数据仓库为什么要分层?
- 把复杂问题简单化:
将复杂的任务分解成多层来完成✅,每一层只处理简单的任务,方便定位问题; - 减少重复开发:
规范数据分层,通过中间层数据,能够减少极大地重复计算,增加一次计算结果的复用性; - 隔离原始数据:
不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
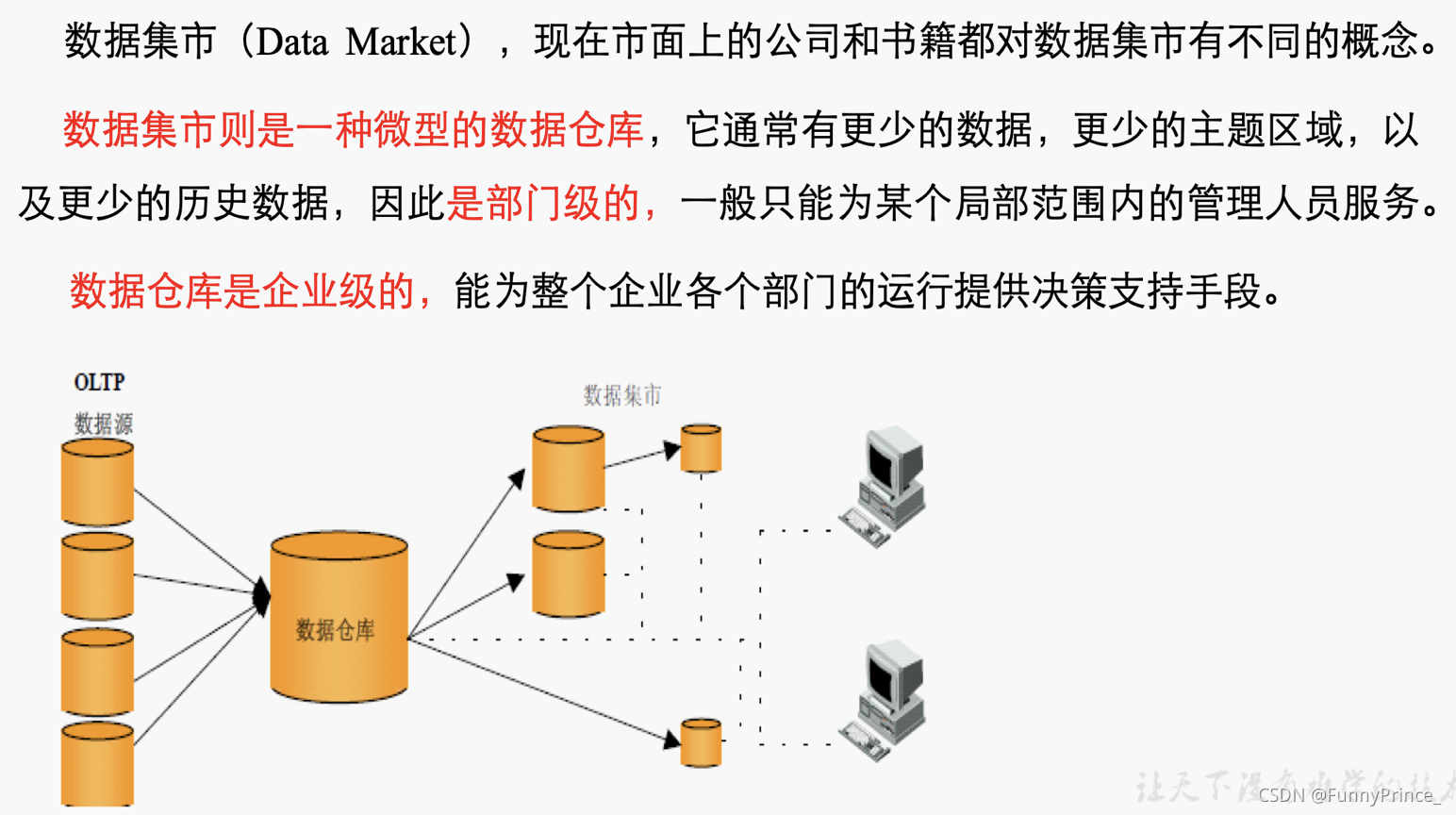
1.2 数据集市与数据仓库概念
⭐️数据集市与数据仓库区别:
1.3 数仓命名规范
1.3.1 表命名
ODS层命名为ods_表名
DIM层命名为dim_表名
DWD层命名为dwd_表名
DWS层命名为dws_表名
DWT层命名为dwt_表名
ADS层命名为ads_表名
临时表命名为tmp_表名
1.3.2 脚本命名
数据源_to_目标_db/log.sh;
用户行为脚本以log为后缀;业务数据脚本以db为后缀。
1.3.3 表字段类型
数量类型为bigint;
金额类型为decimal(16, 2); 表示:16位有效数字,其中小数部分2位;
字符串(名字,描述信息等)类型为string;
主键外键类型为string;
时间戳类型为bigint;
二、数仓理论
2.1 范式理论
2.1.1 范式概念
-
定义
数据建模必须遵循一定的规则,在关系建模中,这种规则就是范式。 -
目的
采用范式,可以降低数据的冗余性。
为什么要降低数据冗余性?
1). 十几年前,磁盘很贵,为了减少磁盘存储;
2). 以前没有分布式系统,都是单机,只能增加磁盘,磁盘个数也是有限的;
3). 一次修改,需要修改多个表,很难保证数据一致性。
-
缺点
范式的缺点是获取数据时,需要通过Join拼接出最后的数据。 -
分类
目前业界范式有:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)、第五范式(5NF)。
2.1.2 函数依赖
函数依赖:完全函数依赖、部分函数依赖、传递函数依赖。

2.1.3 三范式区分
-
第一范式1NF核心原则:属性不可分割;
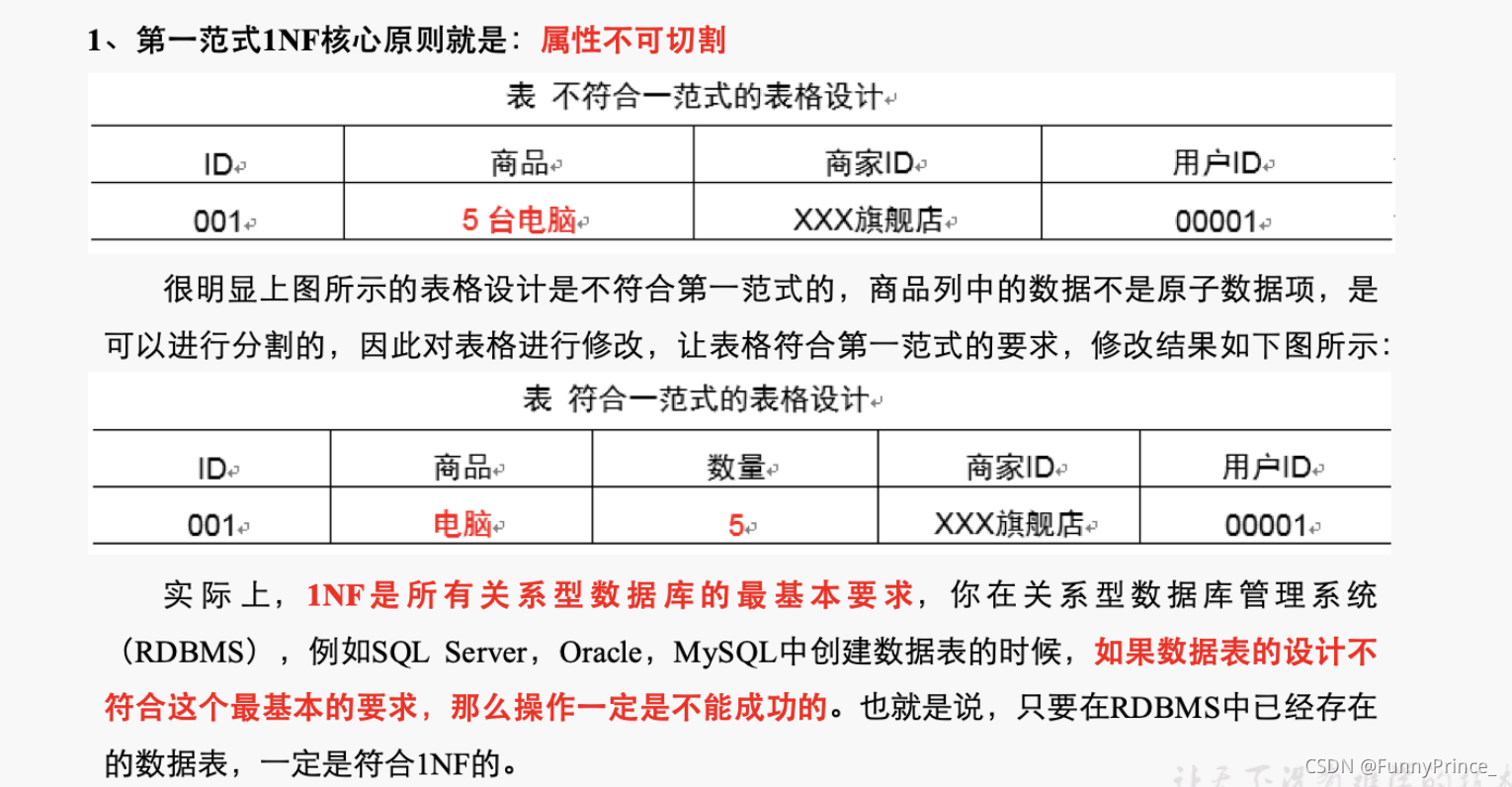
-
第二范式2NF核心原则: 不能存在“
部分函数依赖”,即不能存在非主键字段部分函数依赖于主键函数的现象;
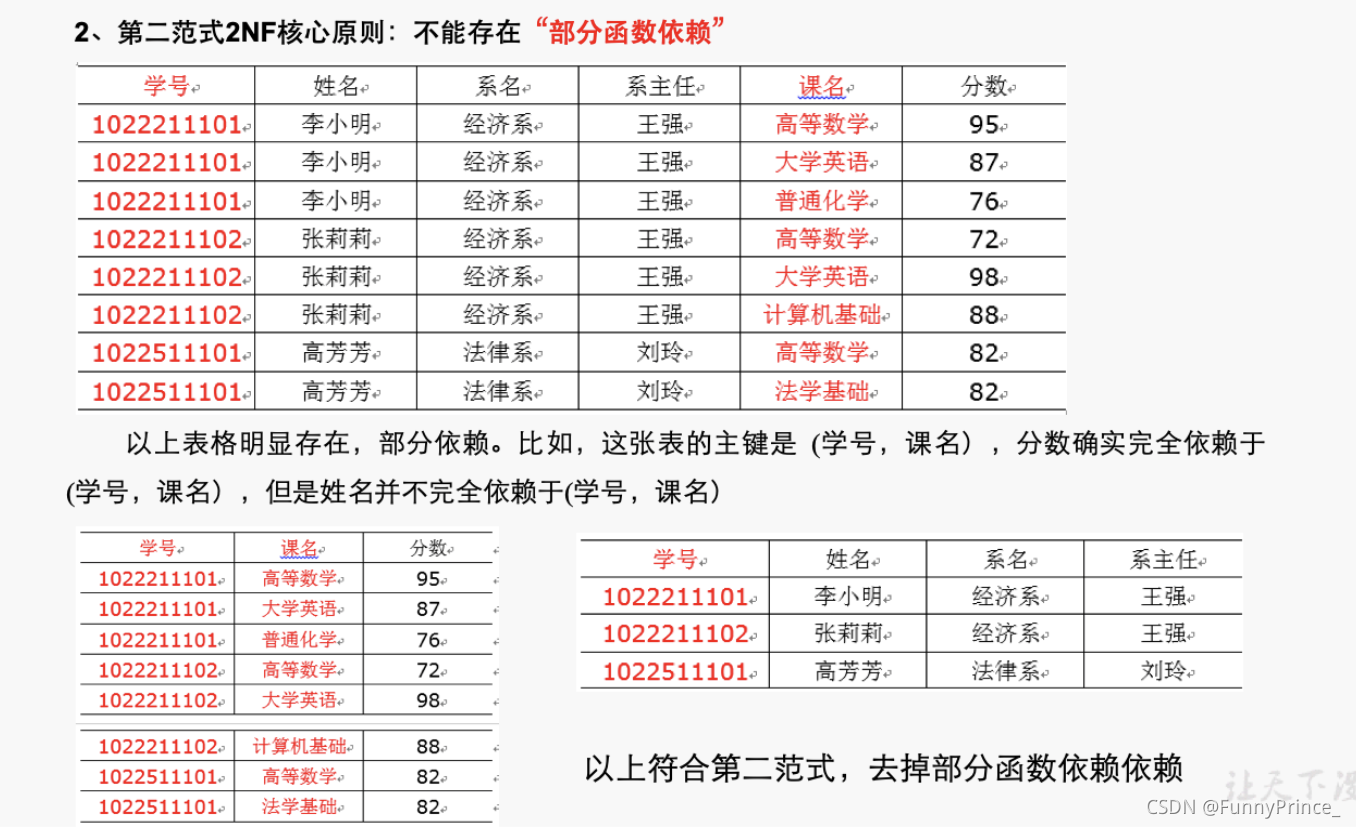
-
第三范式3NF核心原则:
不能存在传递函数依赖,即不能存在非主键字段传递函数依赖于主键字段的现象。
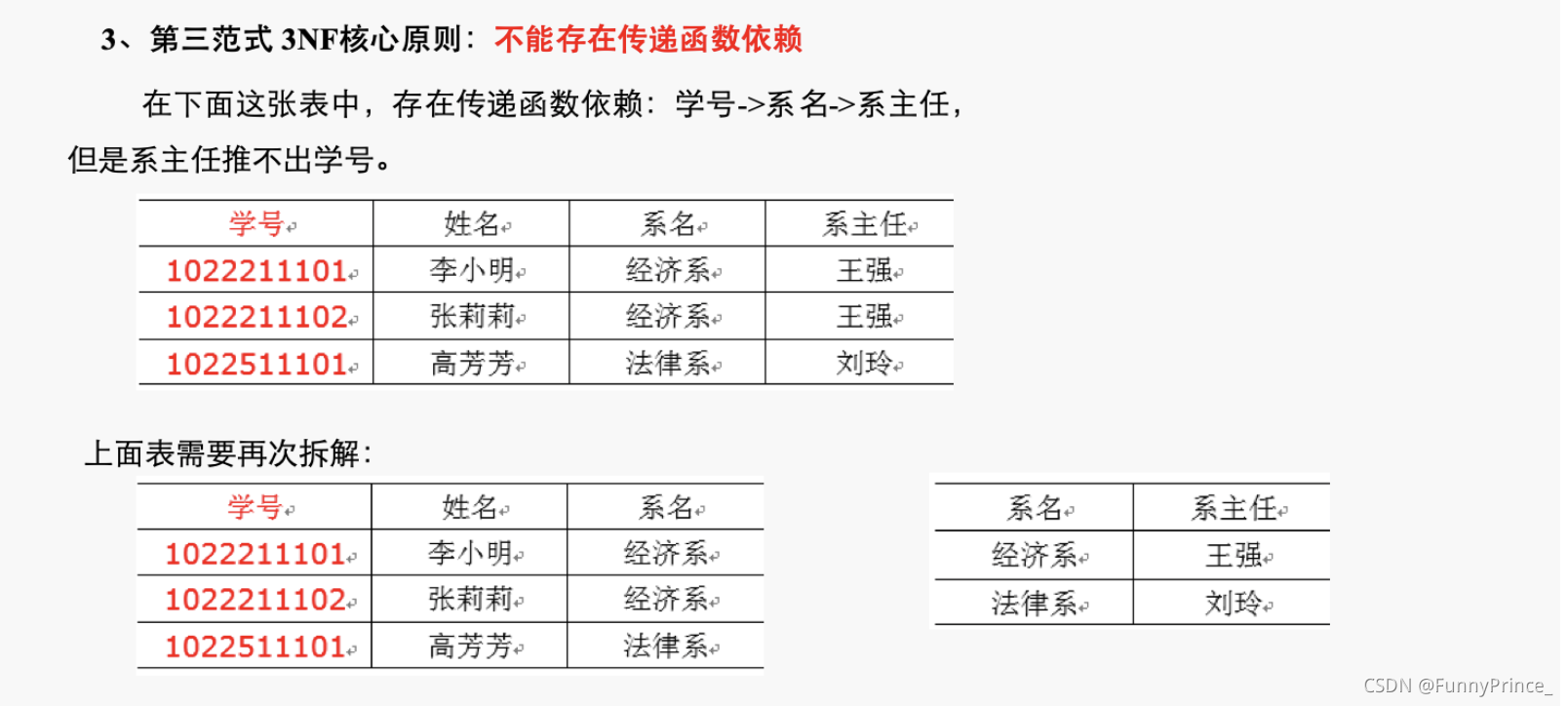
2.2 关系建模与维度建模
关系建模和维度建模是两种数据仓库的建模技术。关系建模由Bill Inmon所倡导,维度建模由Ralph Kimball所倡导。
2.2.1 关系建模
关系建模将复杂的数据抽象为两个概念——实体和关系,并使用规范化的方式表示出来。关系模型如图所示,从图中可以看出,较为松散、零碎,物理表数量多。
图为关系模型示意图:
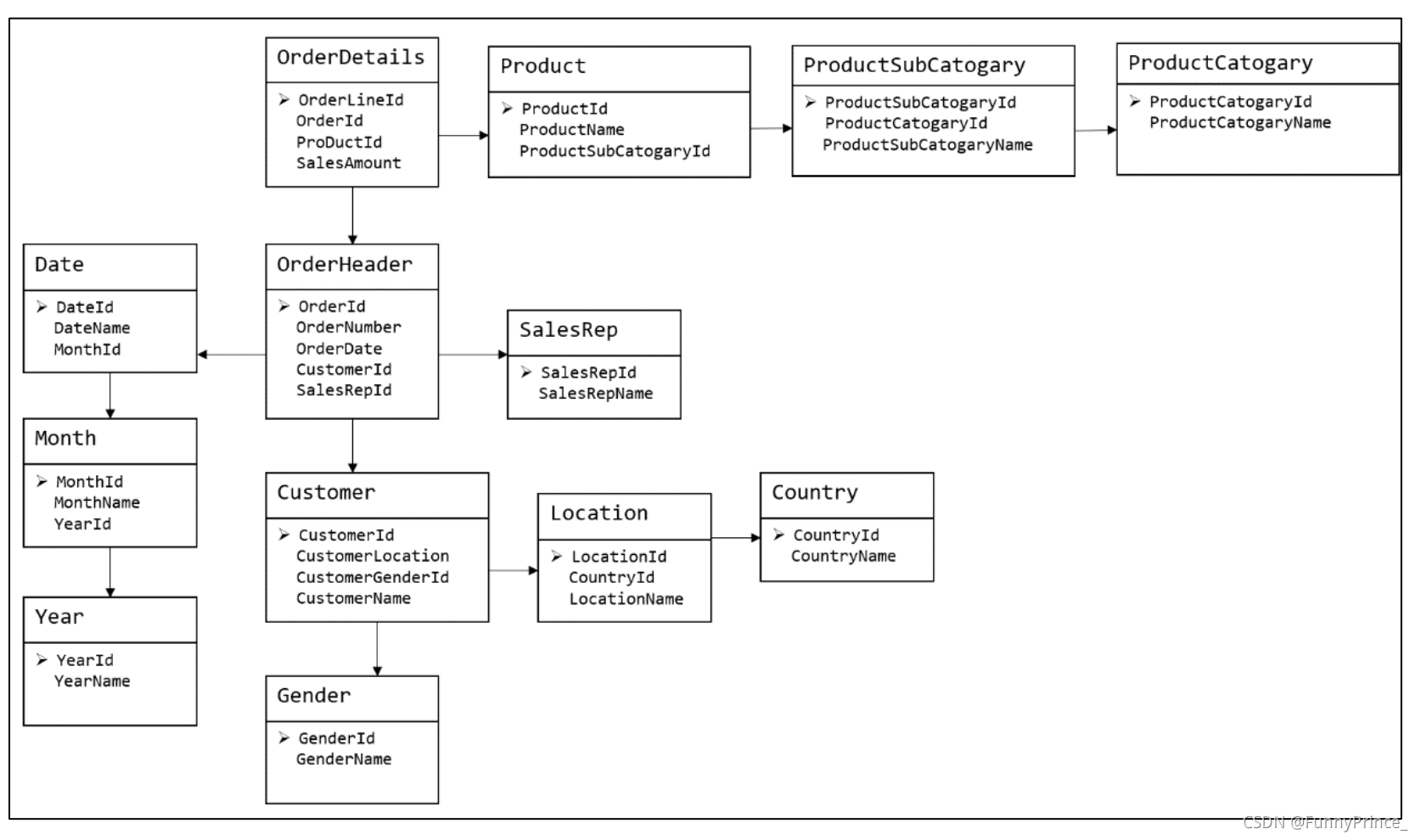
关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
2.2.2 维度建模⭐️
维度模型如图所示,从图中可以看出,模型相对清晰、简洁。
图为维度模型示意图:
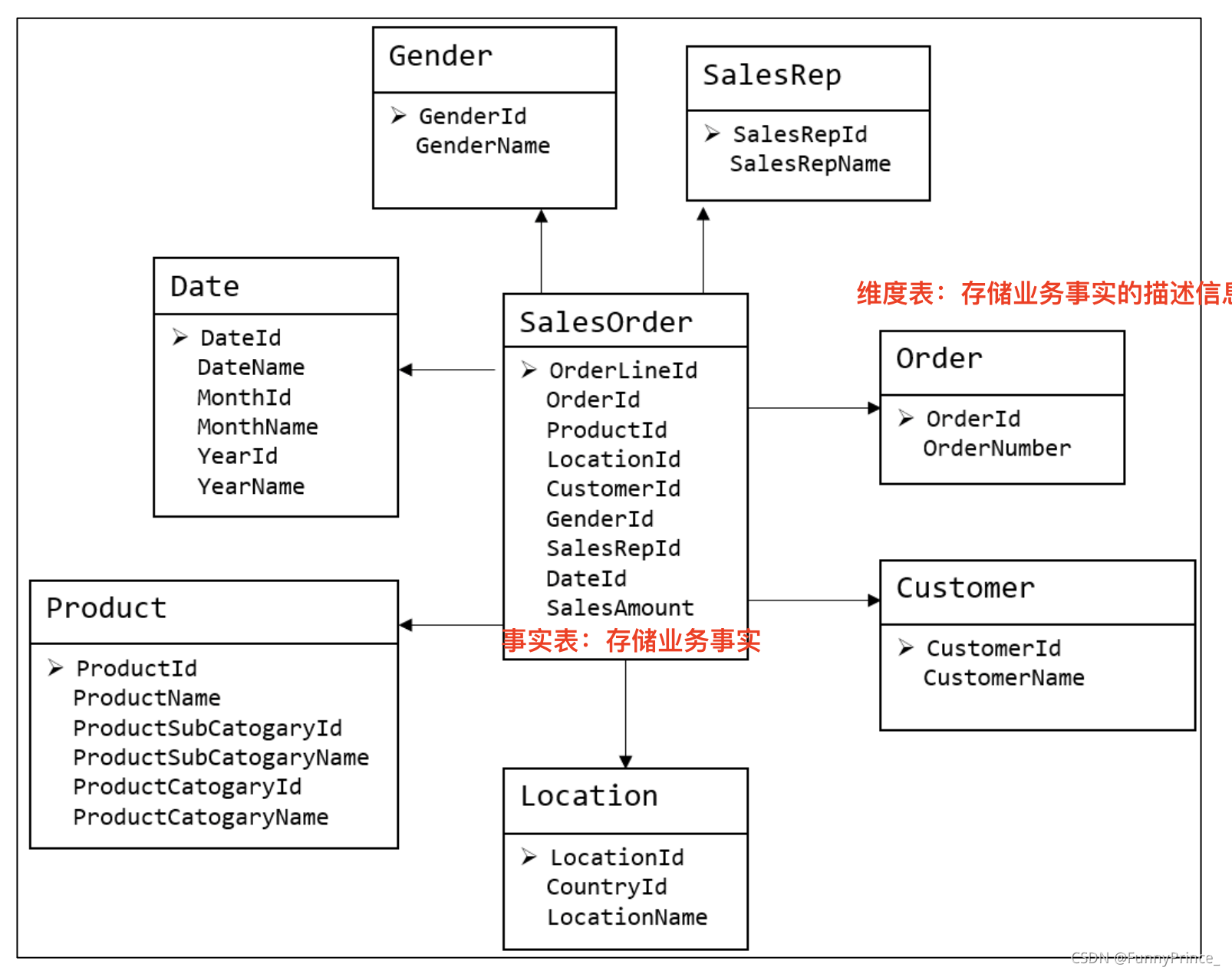
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。
join少、shuffle少。
2.3 维度表和事实表⭐️
2.3.1 维度表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。
🌰用户、商品、日期、地区等。
维表的特征:
- 维表的范围很宽(具有多个属性、列比较多);
- 跟事实表相比,行数相对较小:通常< 10万条;
- 内容相对固定:编码表;
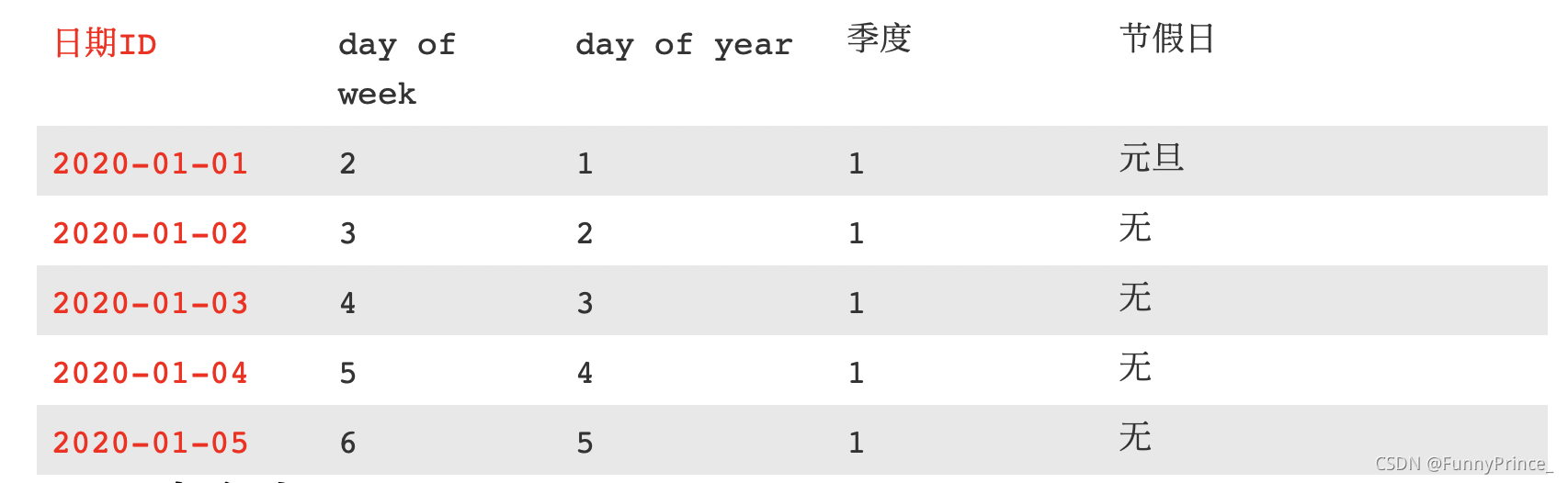
🌰:
时间维度表:
2.3.2 事实表
事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等);
“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等)。
🌰2020年5月21日,小明花50块买了颗🍬;
维度表:时间、用户、商品、商家。事实表:50块钱、🍬。
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键,通常具有两个和两个以上的外键。
事实表的特征:
- 非常大;
- 内容相对的窄:列数较少(主要是外键id和度量值);
- 经常发生变化,每天会新增加很多。
1)事务型事实表
以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。一旦事务被提交,事实表数据被插入,数据就不再进行更改,其更新方式为增量更新。
2)周期型快照事实表
周期型快照事实表中不会保留所有数据,只保留固定时间间隔的数据,使用全量同步策略,例如每天或者每月的销售额,或每月的账户余额等。
🌰购物车,有加减商品,随时都有可能变化,但是我们更关心每天结束时这里面有多少商品,方便我们后期统计分析。
3)累积型快照事实表
累积快照事实表用于跟踪业务事实的变化,使用新增和变化同步策略。
🌰数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断更新。

总结:
事务型事实表: 适用于不会发生变化的业务,通常使用增量同步;
周期型事实表:适用于不关心明细操作、只关心结果的业务,通常使用全量同步策略;
累积型事实表:适用于会发生周期性变化的业务,通常使用新增和变化同步策略。
2.4 维度模型分类
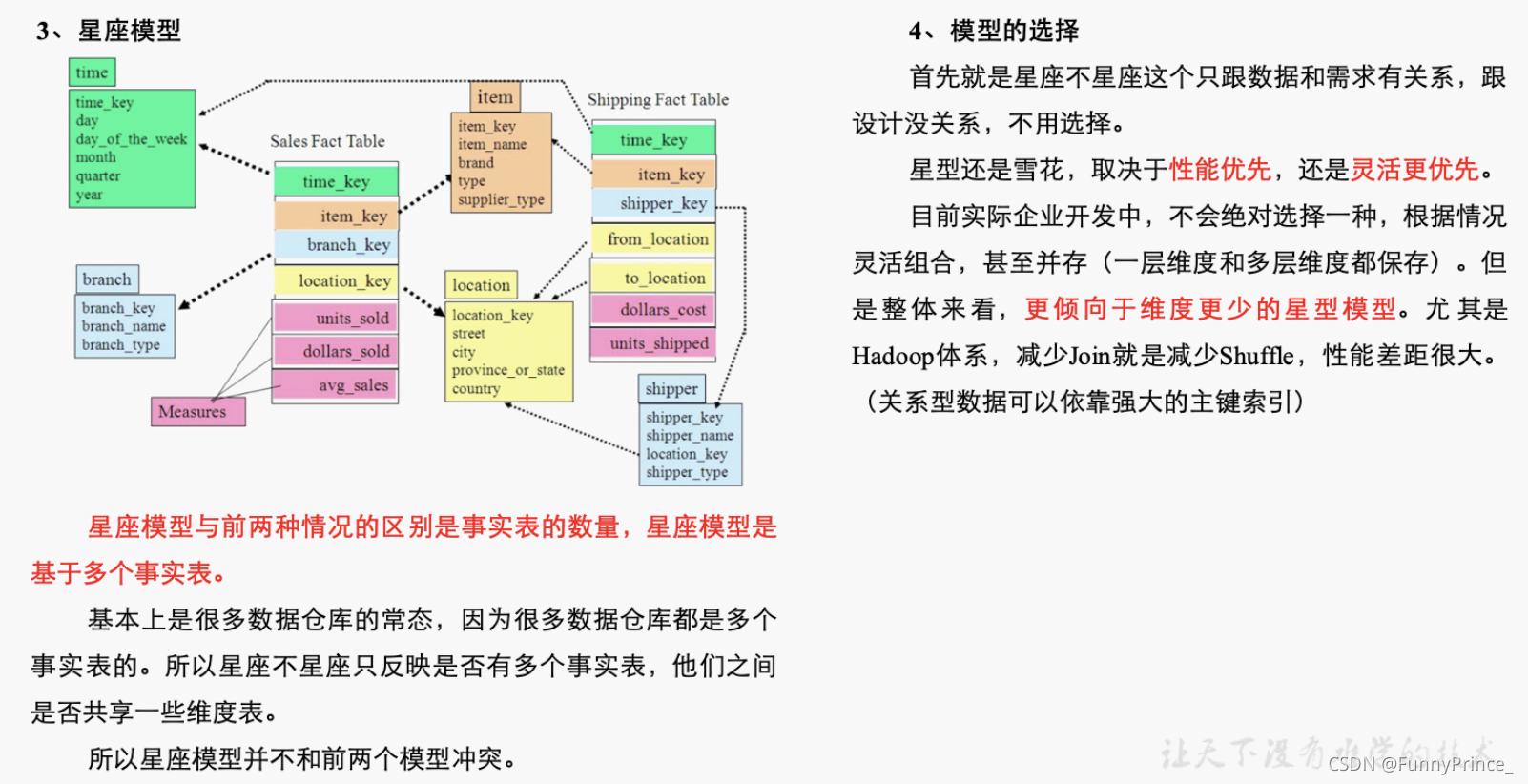
在维度建模的基础上又分为三种模型:星型模型、雪花模型、星座模型。
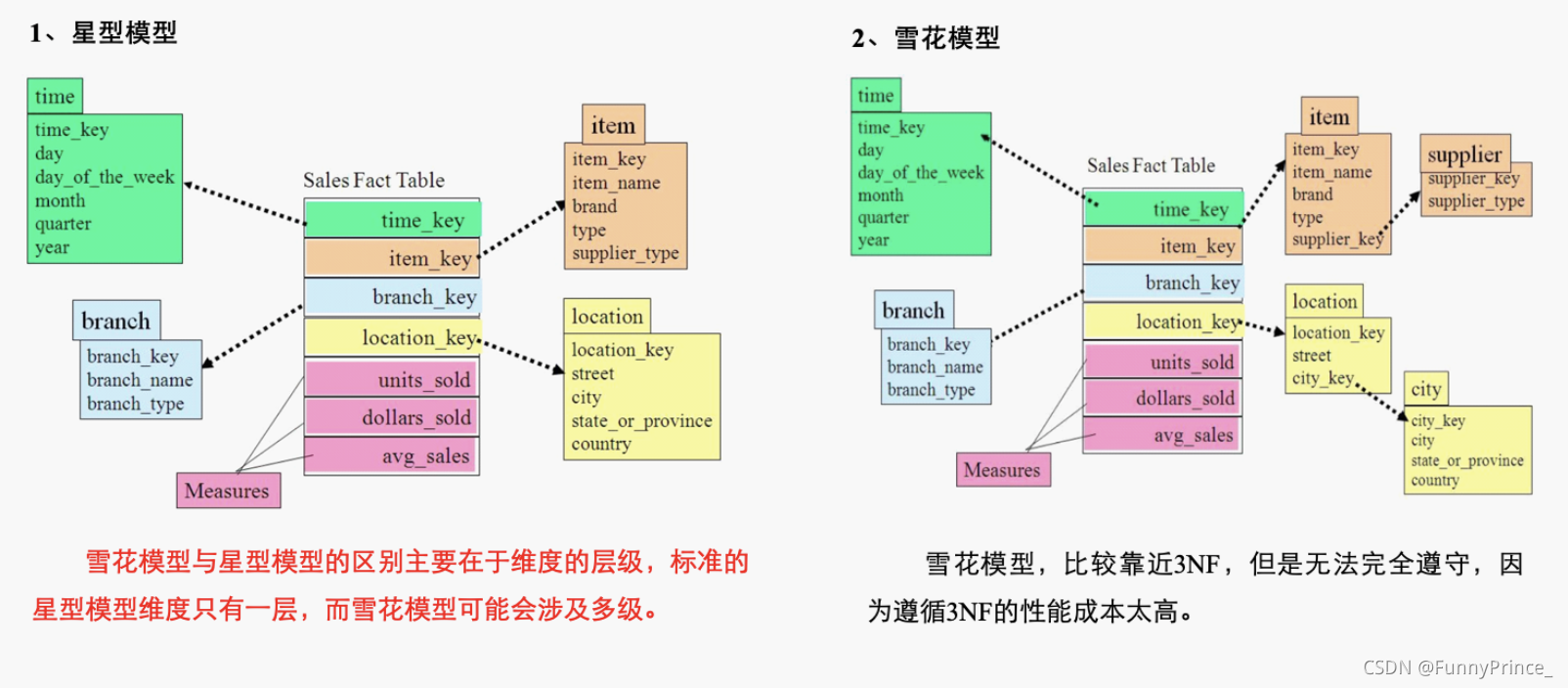
2.5 数据仓库建模⭐️🌟
2.5.1 ODS层
-
HDFS用户行为数据: 通过kafka-flume-kafka数据采集通道传输到hdfs的log日志;
-
HDFS业务数据:通sqoop从mysql同步到hdfs的数据文件;
-
针对HDFS上的用户行为数据和业务数据,我们如何规划处理?
1). 保持数据原貌不做任何修改,起到备份数据的作用;
2). 数据采用压缩,减少磁盘存储空间(例如:原始数据100G,可以压缩到10G左右);
3). 创建分区表,防止后续的全表扫描。
2.5.2 DIM层和DWD层
DIM层DWD层需构建维度模型,一般采用星型模型,呈现的状态一般为星座模型。
维度建模一般按照以下四个步骤:
选择业务过程→声明粒度→确认维度→确认事实
-
选择业务过程
在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。 -
声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项;
支付事实表中一行数据表示的是一个支付记录。 -
确定维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
确定维度的原则是:后续需求中是否要分析相关维度的指标。
🌰需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
- 确定事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。
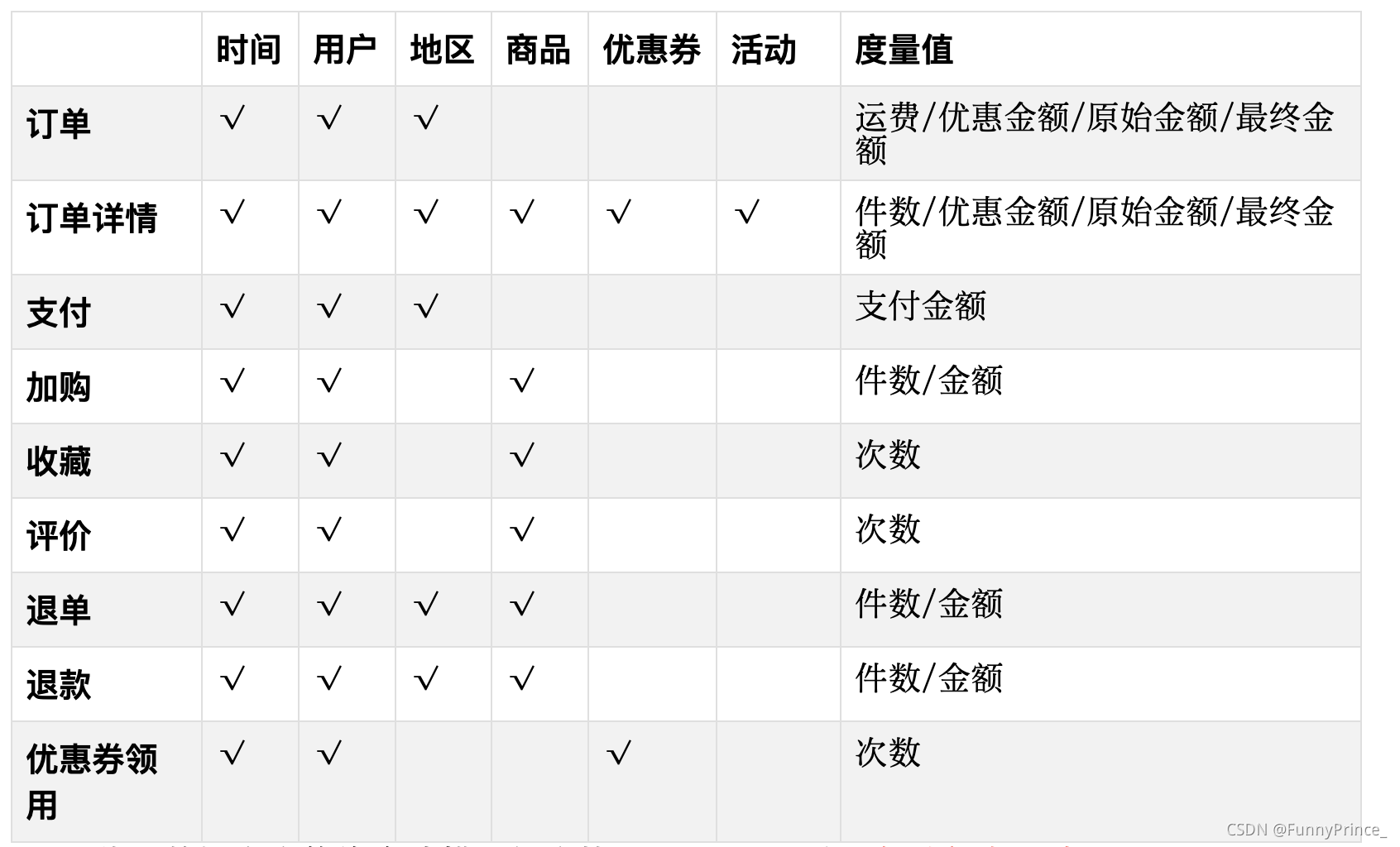
2.5.3 DWS层与DWT层
DWS层和DWT层统称宽表层,这两层的设计思想大致相同,通过以下案例进行阐述。
- 问题引出:两个需求,统计每个省份订单的个数、统计每个省份订单的总金额
- 处理办法:都是将省份表和订单表进行join,group by省份,然后计算。同样数据被计算了两次,实际上类似的场景还会更多。
那怎么设计能避免重复计算呢?
针对上述场景,可以设计一张地区宽表,其主键为地区ID,字段包含为:下单次数、下单金额、支付次数、支付金额等。上述所有指标都统一进行计算,并将结果保存在该宽表中,这样就能有效避免数据的重复计算。
- 总结:
1). 需要建哪些宽表:以维度为基准。
2). 宽表里面的字段:是站在不同维度的角度去看事实表,重点关注事实表聚合后的度量值。
3). DWS和DWT层的区别:DWS层存放的所有主题对象当天的汇总行为;
🌰每个地区当天的下单次数,下单金额等;
DWT层存放的是所有主题对象的累积行为;
🌰每个地区最近7天(15天、30天、60天)的下单次数、下单金额等。
2.5.4 ADS层
对电商系统各大主题指标分别进行分析。
三、数仓环境搭建
3.1 Hive环境搭建
3.1.1 Hive引擎简介
Hive引擎包括:默认MR、tez、spark;
Hive on Spark: Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
对比:
Hive on Spark:周边生态更完整;
Spark on Hive:计算性能高。
3.1.2 Hive on Spark配置
1. 兼容性说明:
注⚠️: 官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤: 官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
2. 在Hive所在节点部署Spark:
- Spark官网下载jar包地址:
http://spark.apache.org/downloads.html - 上传
spark-3.0.0-bin-hadoop3.2.tgz至/opt/software/spark目录下:
[xiaobai@hadoop102 spark]$ ll
total 372316
-rw-r--r--. 1 root root 224453229 Oct 4 17:02 spark-3.0.0-bin-hadoop3.2.tgz
-rw-r--r--. 1 root root 156791324 Oct 4 17:01 spark-3.0.0-bin-without-hadoop.tgz
- 将重新编译后带有依赖的spark-3.0.0-bin-hadoop3.2.tgz解压至/opt/module/目录下:
[xiaobai@hadoop102 spark]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
- 将解压后的spark-3.0.0-bin-hadoop3.2改成
spark:
[xiaobai@hadoop102 module]$ mv spark-3.0.0-bin-hadoop3.2/ spark
- 配置SPARK_HOME环境变量
/etc/profile.d/my_env.sh:
[xiaobai@hadoop102 module]$ sudo vim /etc/profile.d/my_env.sh
增加以下内容:
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
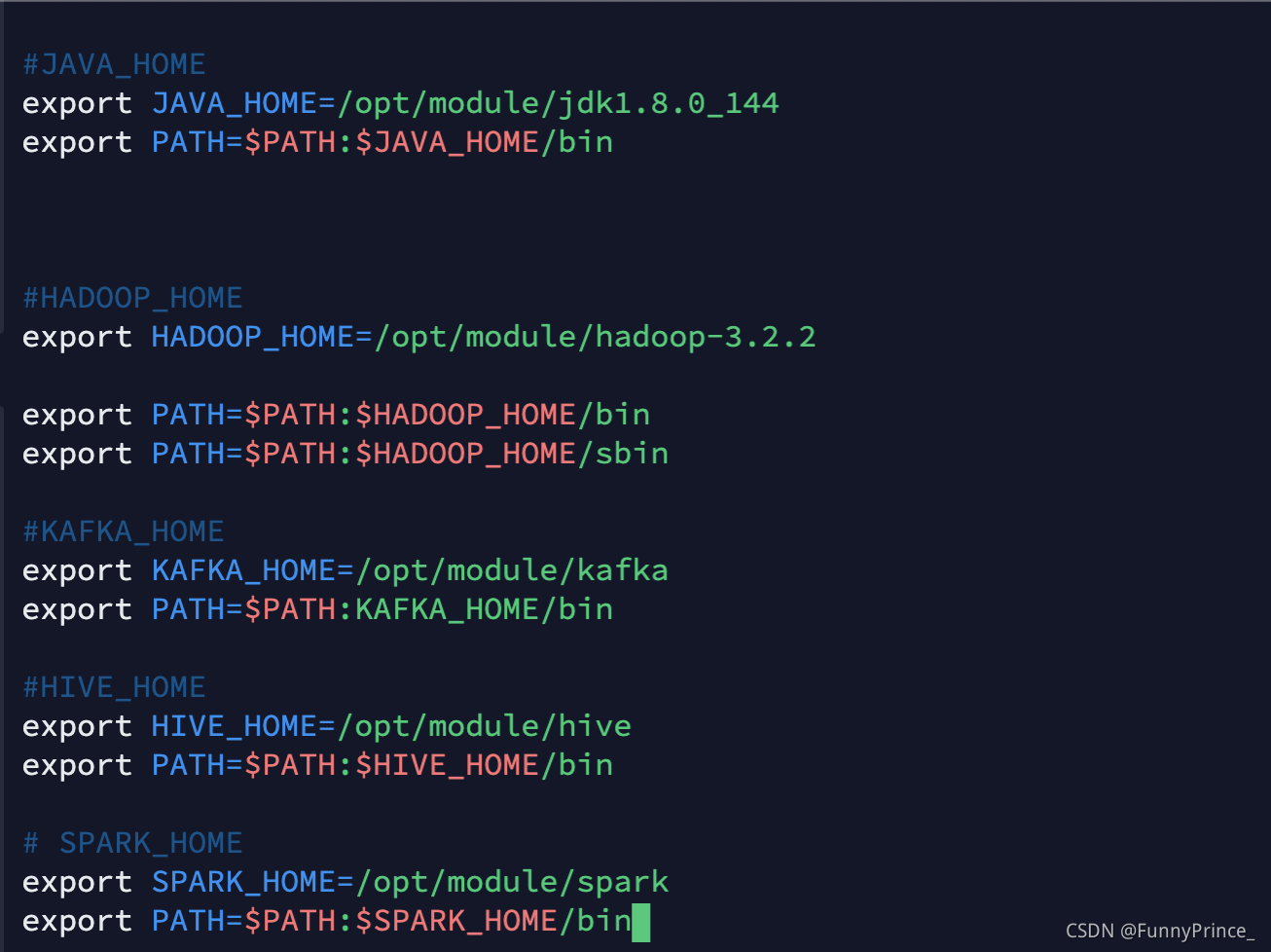
- source环境变量,使其生效:
[xiaobai@hadoop102 module]$ source /etc/profile.d/my_env.sh
3. 在hive中创建spark配置文件:
- 在hive中创建spark配置文件
spark-defaults.conf:
[xiaobai@hadoop102 software]$ vim /opt/module/hive/conf/spark-defaults.conf
- 添加如下内容(在执行任务时,会根据如下参数执行):
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
- 在HDFS创建
spark-history路径,用于存储历史日志:
[xiaobai@hadoop102 software]$ hadoop fs -mkdir /spark-history

4. 向HDFS上传Spark纯净版jar包:
- 在hdfs创建
spark-jars路径:
[xiaobai@hadoop102 spark]$ hadoop fs -mkdir /spark-jars

- 解压
spark-3.0.0-bin-without-hadoop.tgz至/opt/software/spark路径:
[xiaobai@hadoop102 spark]$ tar -zxvf spark-3.0.0-bin-without-hadoop.tgz
- 将解压后的Spark纯净版jar包
spark-3.0.0-bin-without-hadoop上传到hdfs/spark-jars路径下:
[xiaobai@hadoop102 spark]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
注⚠️:
- 由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
- Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
5. 修改hive-site.xml文件:
- 在/opt/module/hive/conf路径下修改
hive-site.xml文件:
[xiaobai@hadoop102 jars]$ vim /opt/module/hive/conf/hive-site.xml
- 增加以下内容:
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>

3.1.3 Hive on Spark测试
- 启动hive客户端:
[xiaobai@hadoop102 jars]$ hive
- 创建一张测试表
student:
hive (default)> create table student(id int,name string);
OK
Time taken: 2.96 seconds
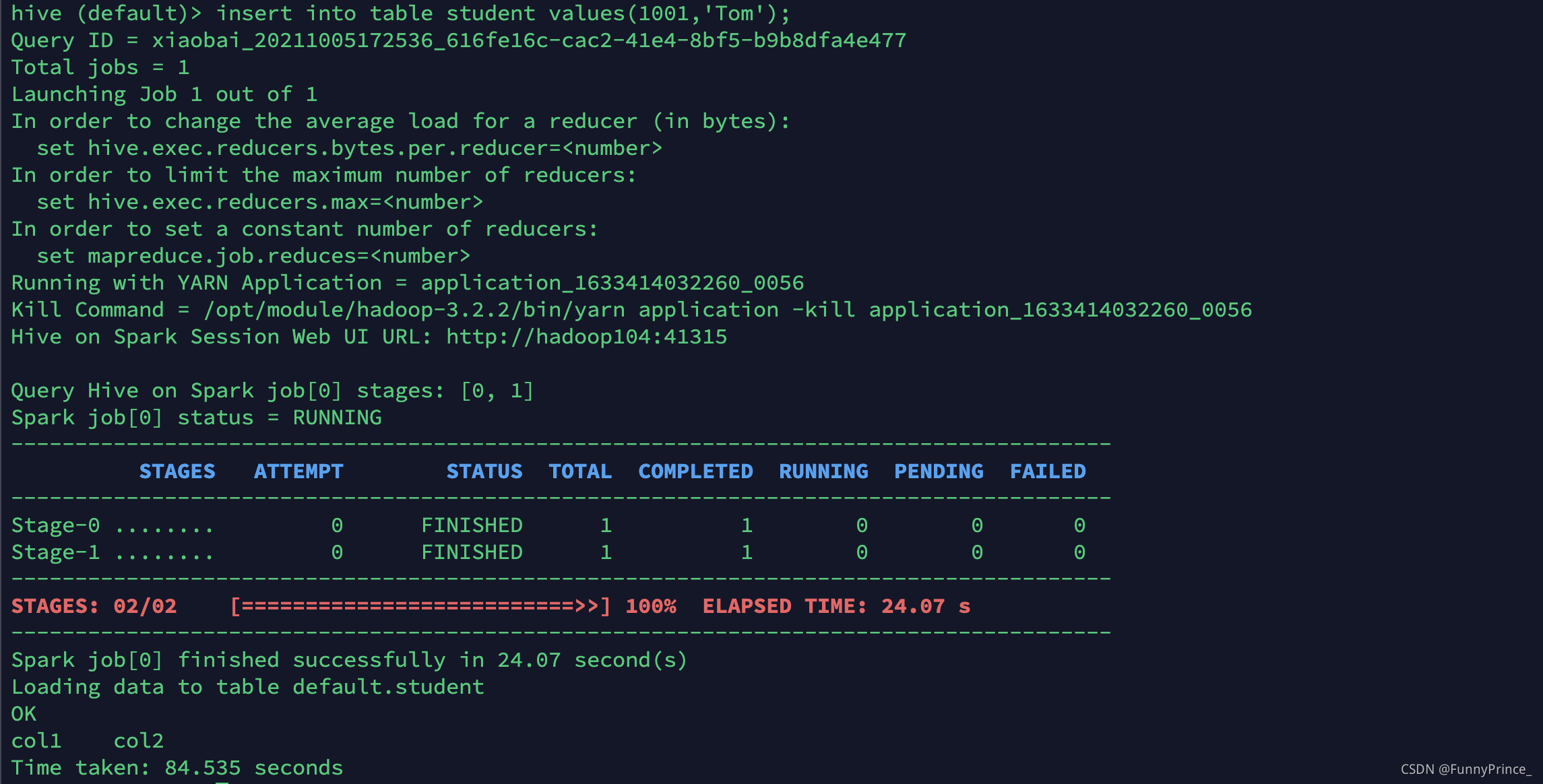
- 通过insert测试效果:
hive (default)> insert into table student values(1001,'Tom');
若出现以下结果,则说明配置成功!
3.2 Yarn配置
3.2.1 增加ApplicationMaster资源比例
容量调度器对每个资源队列中同时运行的Application Master占用的资源进行了限制,该限制通过yarn.scheduler.capacity.maximum-am-resource-percent参数实现,其默认值是0.1,表示每个资源队列上Application Master最多可使用的资源为该队列总资源的10%,目的是防止大部分资源都被Application Master占用,而导致Map/Reduce Task无法执行。
生产环境该参数可使用默认值。
因本项目使用的是Linux虚拟机,集群资源很少,为防止同一时刻只能运行一个Job的情况出现,将默认值调大为0.8;
- 在hadoop102的/opt/module/hadoop-3.2.2/etc/hadoop/
capacity-scheduler.xml文件中修改如下参数值:
[xiaobai@hadoop102 hadoop]$ vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
<description>
2.分发capacity-scheduler.xml配置文件:
[xiaobai@hadoop102 hadoop]$ xsync capacity-scheduler.xml
- 正在运行的任务,在
hadoop103关闭重新启动yarn集群:
[xiaobai@hadoop103 ~]$ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
[xiaobai@hadoop103 ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
可在http://hadoop103:8088/cluster/scheduler–>Application Queues–>>Queue:default下查看默认值和修改后的值:
修改前:
修改后:

3.3 数仓开发环境
数仓开发工具可选用DBeaver或DataGrip,
官方链接:
https://www.jetbrains.com/datagrip/
https://dbeaver.io/download/
以下为Mac版本下载⬇️

两者都需要用到JDBC协议连接到Hive,故需要启动HiveServer2!
- 启动
HiveServer2
[xiaobai@hadoop102 hive]$ hiveserver2
- 配置DataGrip连接
1). 创建连接
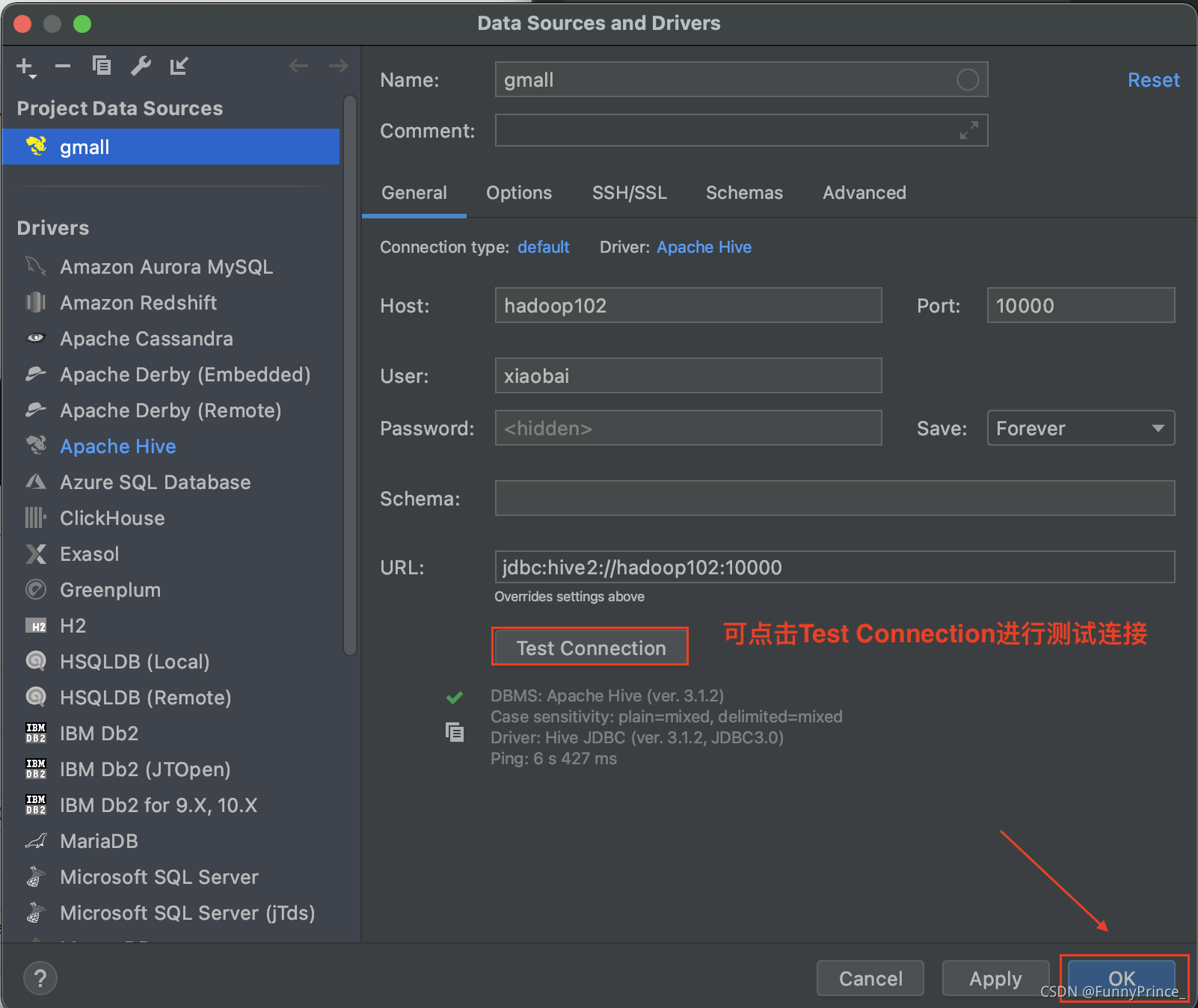
2). 配置连接属性:可点击Test Connection进行连接测试,随机点击OK⬇️
- 测试使用
创建数据库gmall,并观察是否创建成功。
1). 创建数据库
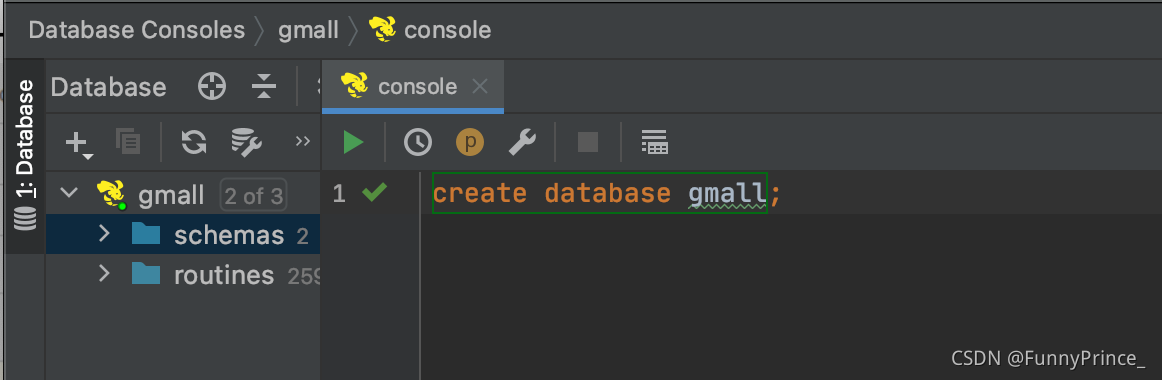
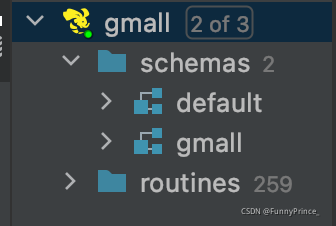
2). 查看数据库
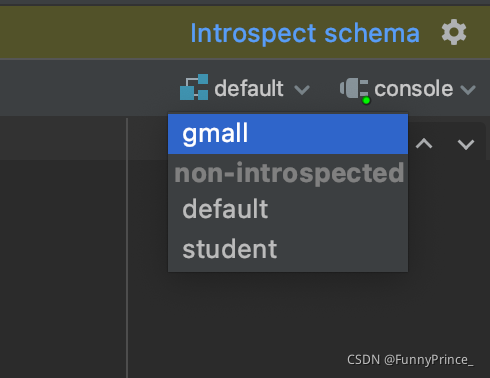
3). 修改连接,指明连接数据库
如图,需在右上角选择gmall数据库,为防止遗忘,可修改properties为gmall
点击properties按钮,修改连接:
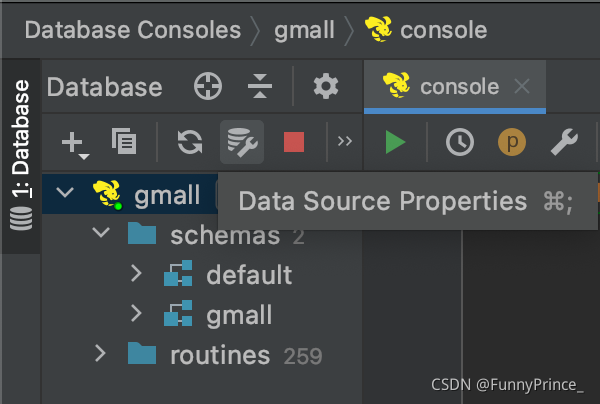
将Schema设置为我们需要的数据库gmall:
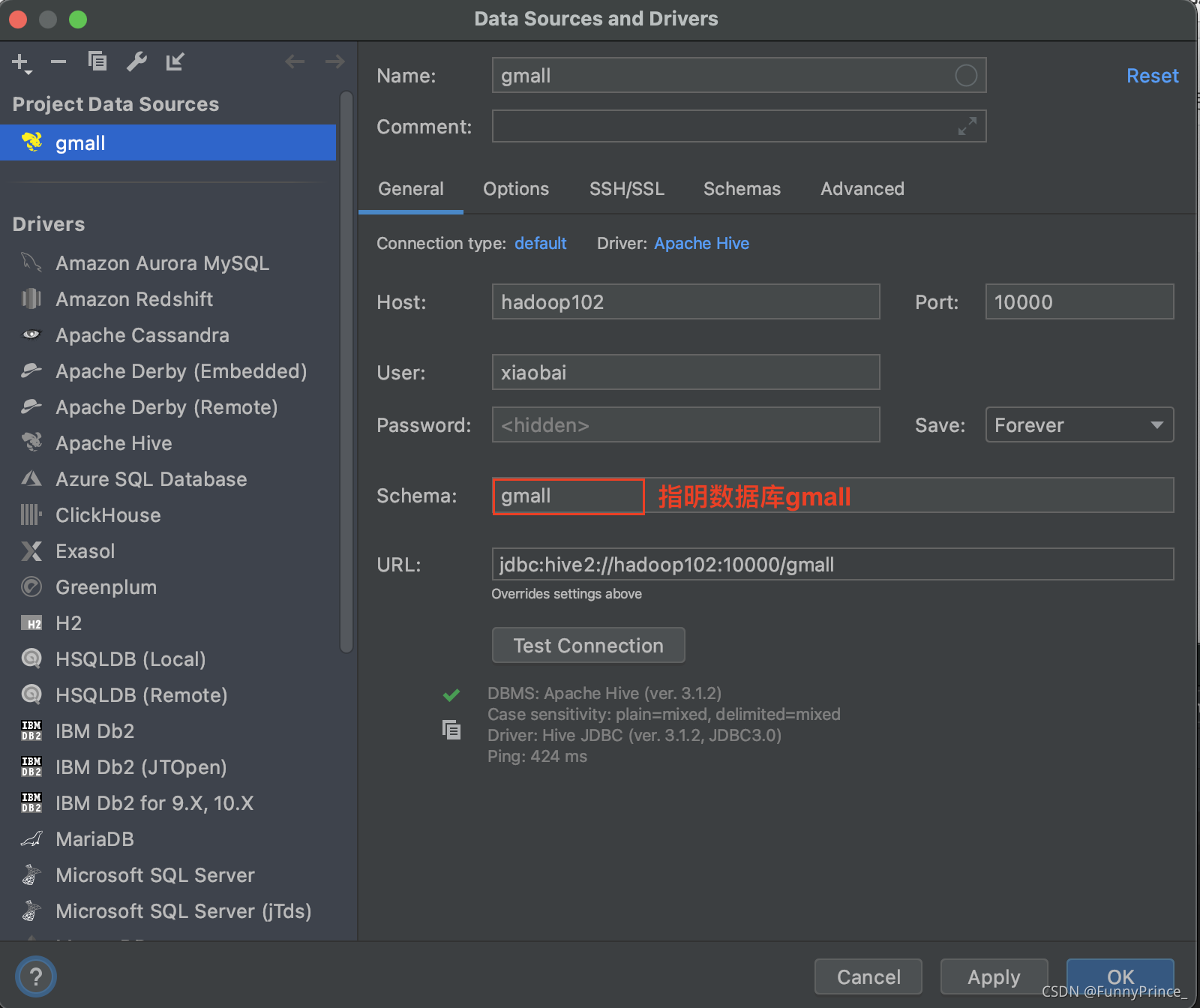
4). 选择当前数据库为gmall;
3.4 数据准备
假定数仓上线的日期为2020-06-14.
1. 用户行为日志
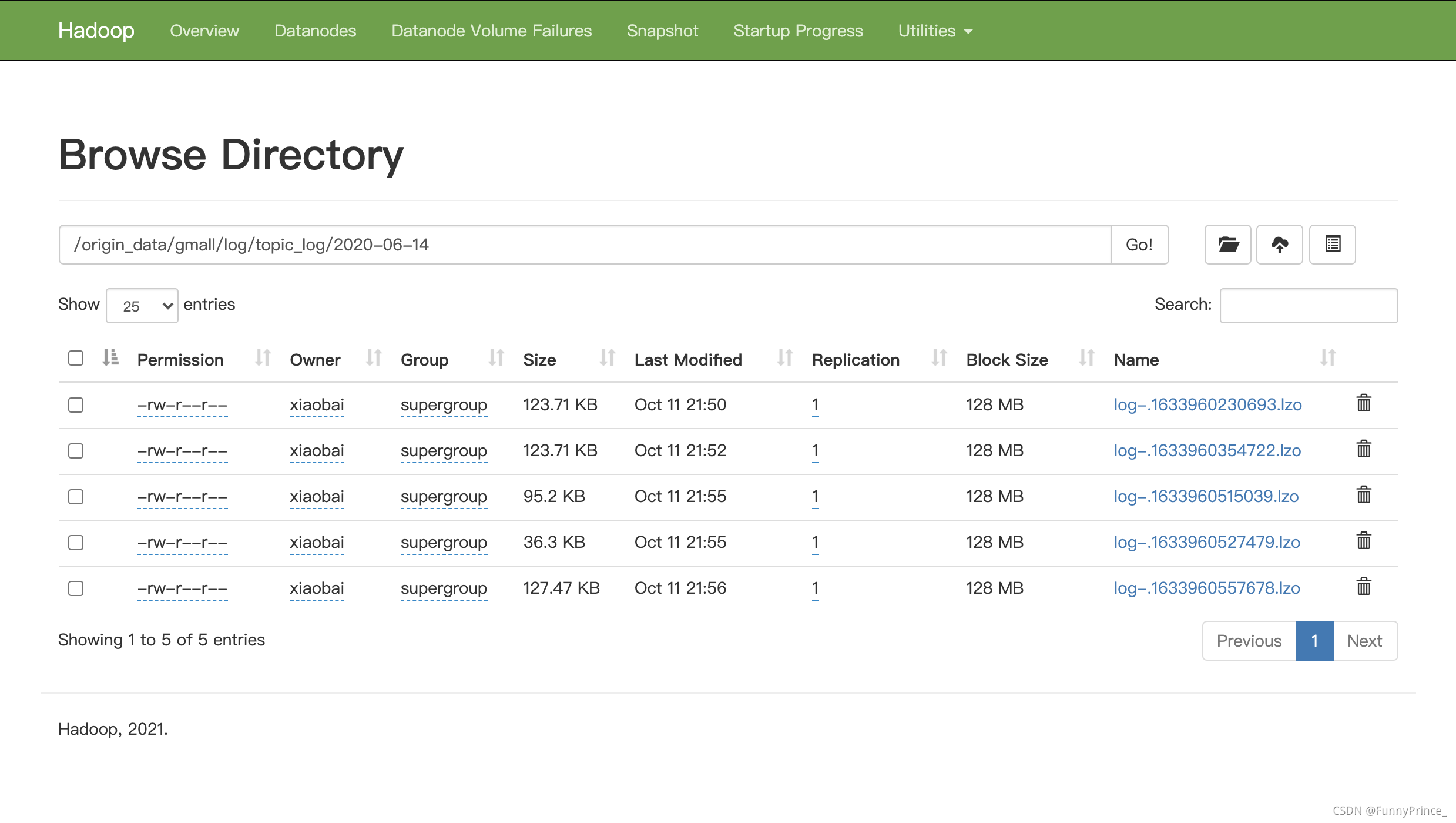
用户行为日志,一般是没有历史数据的,故日志只需要准备2020-06-14一天的数据。
1). 启动日志采集通道,包括Flume、Kafak等;
2). 修改两个日志服务器(hadoop102、hadoop103)中的/opt/module/applog/application.yml配置文件,将mock.date参数改为2020-06-14;
[xiaobai@hadoop102 applog]$ vim application.yml

3). 执行日志生成脚本lg.sh;
[xiaobai@hadoop102 applog]$ lg.sh
4). 查看HDFS是否出现相应文件⬇️
2. 业务数据
业务数据一般存在历史数据,此处需准备2020-06-10至2020-06-14的数据。具体操作如下。
1). 修改hadoop102节点上的/opt/module/db_log/application.properties文件,将mock.date、mock.clear,mock.clear.user三个参数:
[xiaobai@hadoop102 db_log]$ vim application.properties
tips:2020-06-10为第一天数据,所以重置需设为1!

2). 执行模拟生成业务数据的命令,生成第一天2020-06-10的历史数据:
[xiaobai@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar
3). 设置第二天2020-06-11的数据,修改参数为:

注⚠️:重置参数只有第一天需要设置为1!
4). 执行模拟生成业务数据的命令,生成第二天2020-06-11的历史数据:
[xiaobai@hadoop102 db_log]$ java -jar gmall2020-mock-db-2021-01-22.jar
以此类推,设置2020-06-10到2020-06-14多天数据并生成!
5). 在/home/xiaobai/bin目录下执行mysql_to_hdfs_init.sh脚本,将模拟生成的业务数据同步到HDFS。
[xiaobai@hadoop102 bin]$ ./mysql_to_hdfs_init.sh all 2020-06-14
四、数仓搭建-ODS层
- 保持数据原貌不做任何修改,起到备份数据的作用;
- 数据采用LZO压缩,减少磁盘存储空间。100G数据可以压缩到10G以内;
- 创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表;
- 创建外部表,在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。
4.1 ODS层(用户行为数据)
4.1.1 创建日志表ods_log
- 创建支持lzo压缩的分区表
1). 建表语句
create database gmall;
--ODS层
--ods日志表
drop table if exists ods_log;
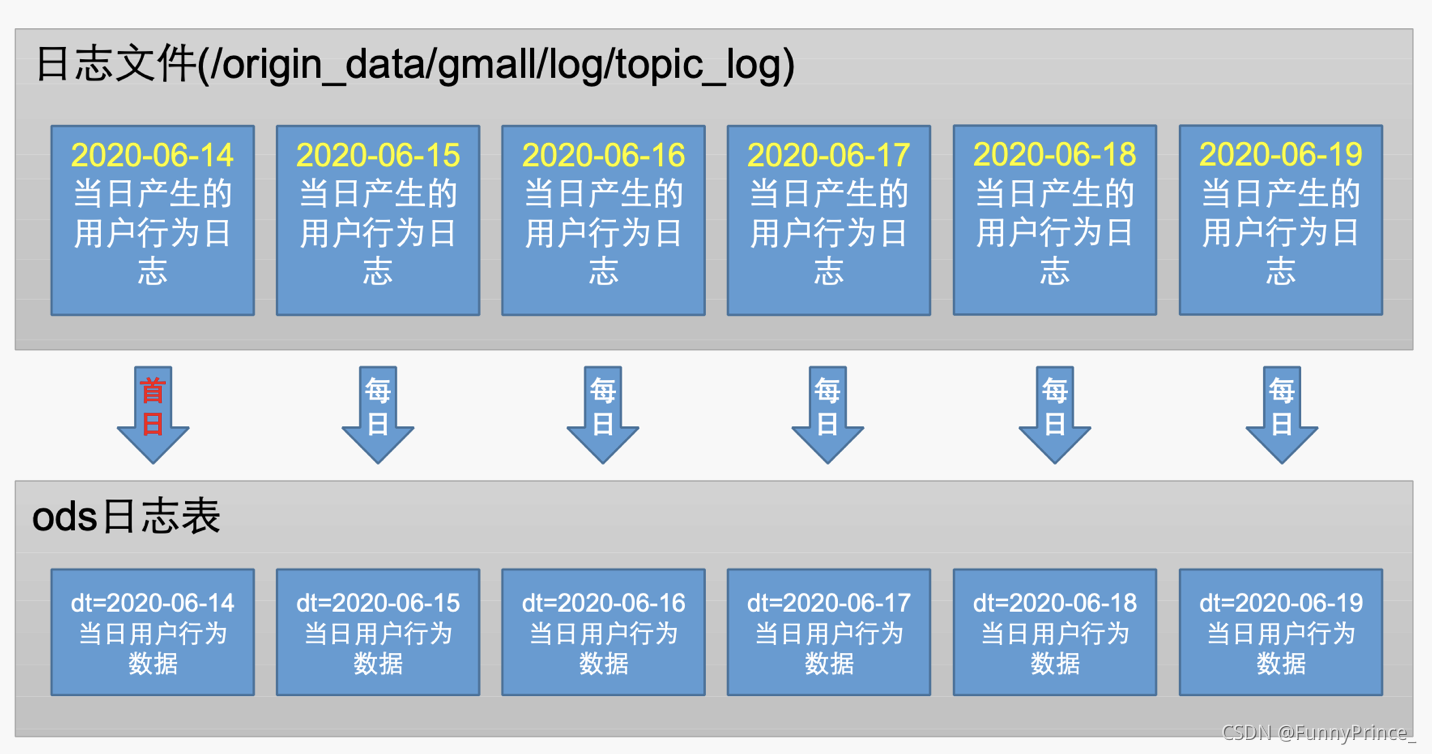
CREATE EXTERNAL TABLE ods_log (`line` string)
PARTITIONED BY (`dt` string) -- 按照时间创建分区
STORED AS -- 指定存储方式,读数据采用LzoTextInputFormat;
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_log' -- 指定数据在hdfs上的存储位置
;
2). 分区规划

2. 加载数据
4.1.2 ODS层日志表加载数据脚本
- 在/home/xiaobai/bin创建一个
hdfs_to_ods_log.sh文件:
[xiaobai@hadoop102 bin]$ vim hdfs_to_ods_log.sh
在文件中添加如下内容:
#!/bin/bash
# 定义变量方便修改
APP=gmall
# 如果是输入的日期按照取输入日期;如果没输入日期取当前时间的前一天
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
echo ================== 日志日期为 $do_date ==================
sql="
load data inpath '/origin_data/$APP/log/topic_log/$do_date' into table ${APP}.ods_log partition(dt='$do_date');
"
hive -e "$sql"
hadoop jar /opt/module/hadoop-3.2.2/share/hadoop/common/hadoop-lzo-0.4.20.jar com.hadoop.compression.lzo.DistributedLzoIndexer /warehouse/$APP/ods/ods_log/dt=$do_date
tips:
[ -n 变量值 ] 判断变量的值,是否为空;
– 变量的值,非空,返回true;
– 变量的值,为空,返回false;
注意:[ -n 变量值 ]不会解析数据,使用[ -n 变量值 ]时,需要对变量加上双引号(" ");
查看date命令的使用,date --help.
- 增加脚本执行权限:
[xiaobai@hadoop102 bin]$ chmod +x hdfs_to_ods_log.sh
- 脚本使用:
执行脚本:
[xiaobai@hadoop102 bin]$ ./hdfs_to_ods_log.sh 2020-06-14
在dataGrip中查看导入数据
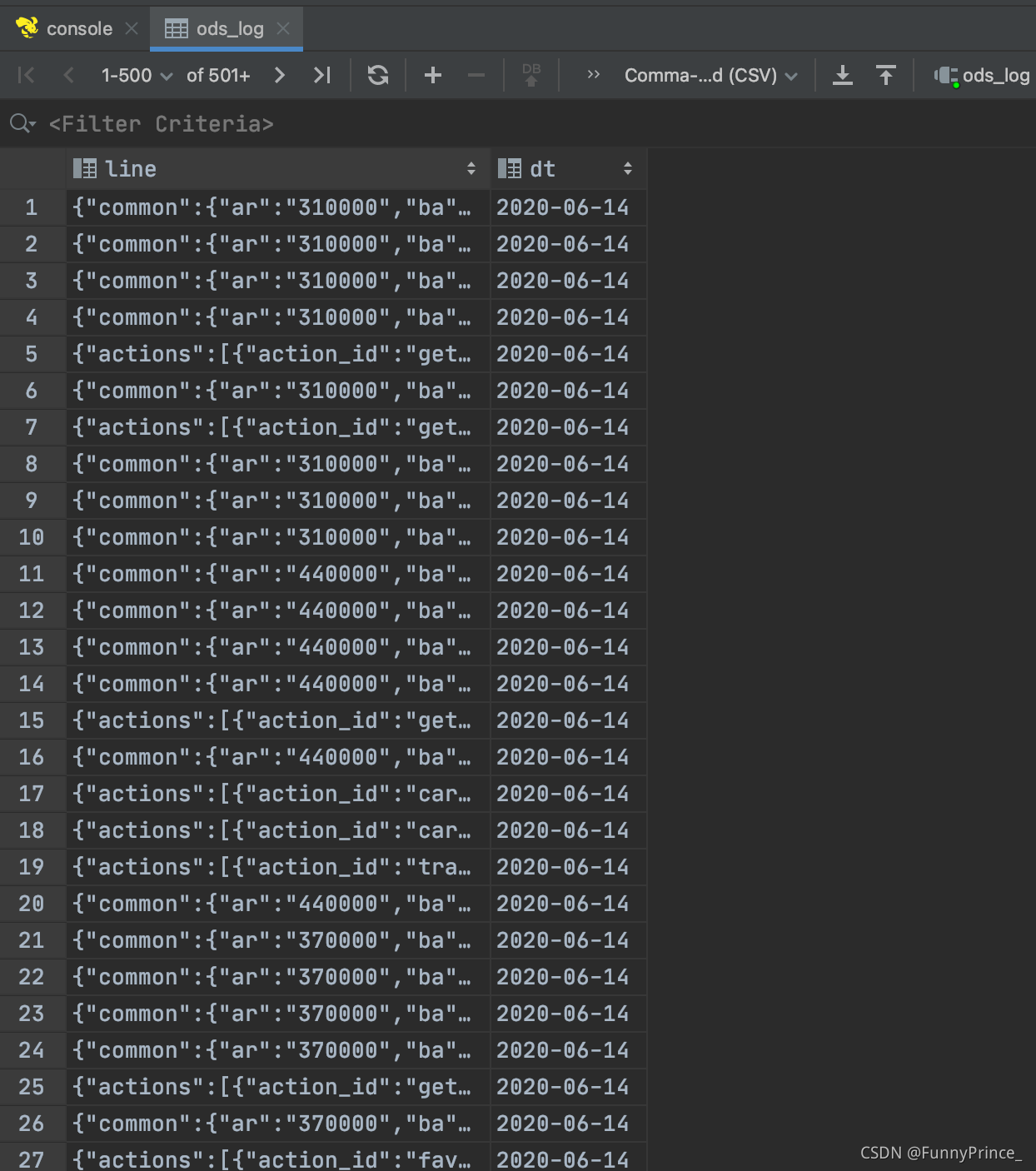
4.2 ODS层(业务数据)
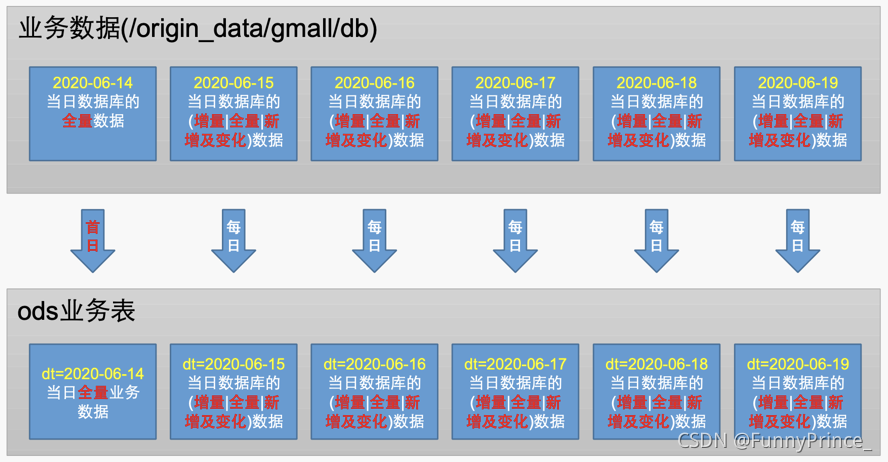
ODS层业务表分区规划如下:

ODS层业务表数据装载思路如下:
4.2.1 活动信息表
DROP TABLE IF EXISTS ods_activity_info;
CREATE EXTERNAL TABLE ods_activity_info(
`id` STRING COMMENT '编号',
`activity_name` STRING COMMENT '活动名称',
`activity_type` STRING COMMENT '活动类型',
`start_time` STRING COMMENT '开始时间',
`end_time` STRING COMMENT '结束时间',
`create_time` STRING COMMENT '创建时间'
) COMMENT '活动信息表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_activity_info/';
4.2.2 活动规则表
DROP TABLE IF EXISTS ods_activity_rule;
CREATE EXTERNAL TABLE ods_activity_rule(
`id` STRING COMMENT '编号',
`activity_id` STRING COMMENT '活动ID',
`activity_type` STRING COMMENT '活动类型',
`condition_amount` DECIMAL(16,2) COMMENT '满减金额',
`condition_num` BIGINT COMMENT '满减件数',
`benefit_amount` DECIMAL(16,2) COMMENT '优惠金额',
`benefit_discount` DECIMAL(16,2) COMMENT '优惠折扣',
`benefit_level` STRING COMMENT '优惠级别'
) COMMENT '活动规则表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_activity_rule/';
4.2.3 一级品类表
DROP TABLE IF EXISTS ods_base_category1;
CREATE EXTERNAL TABLE ods_base_category1(
`id` STRING COMMENT 'id',
`name` STRING COMMENT '名称'
) COMMENT '商品一级分类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_category1/';
4.2.4 二级品类表
DROP TABLE IF EXISTS ods_base_category2;
CREATE EXTERNAL TABLE ods_base_category2(
`id` STRING COMMENT ' id',
`name` STRING COMMENT '名称',
`category1_id` STRING COMMENT '一级品类id'
) COMMENT '商品二级分类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_category2/';
4.2.5 三级品类表
DROP TABLE IF EXISTS ods_base_category3;
CREATE EXTERNAL TABLE ods_base_category3(
`id` STRING COMMENT ' id',
`name` STRING COMMENT '名称',
`category2_id` STRING COMMENT '二级品类id'
) COMMENT '商品三级分类表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_category3/';
4.2.6 编码字典表
DROP TABLE IF EXISTS ods_base_dic;
CREATE EXTERNAL TABLE ods_base_dic(
`dic_code` STRING COMMENT '编号',
`dic_name` STRING COMMENT '编码名称',
`parent_code` STRING COMMENT '父编码',
`create_time` STRING COMMENT '创建日期',
`operate_time` STRING COMMENT '操作日期'
) COMMENT '编码字典表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_dic/';
4.2.7 省份表
DROP TABLE IF EXISTS ods_base_province;
CREATE EXTERNAL TABLE ods_base_province (
`id` STRING COMMENT '编号',
`name` STRING COMMENT '省份名称',
`region_id` STRING COMMENT '地区ID',
`area_code` STRING COMMENT '地区编码',
`iso_code` STRING COMMENT 'ISO-3166编码,供可视化使用',
`iso_3166_2` STRING COMMENT 'IOS-3166-2编码,供可视化使用'
) COMMENT '省份表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_province/';
4.2.8 地区表
DROP TABLE IF EXISTS ods_base_region;
CREATE EXTERNAL TABLE ods_base_region (
`id` STRING COMMENT '编号',
`region_name` STRING COMMENT '地区名称'
) COMMENT '地区表'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_region/';
4.2.9 品牌表
DROP TABLE IF EXISTS ods_base_trademark;
CREATE EXTERNAL TABLE ods_base_trademark (
`id` STRING COMMENT '编号',
`tm_name` STRING COMMENT '品牌名称'
) COMMENT '品牌表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_base_trademark/';
4.2.10 购物车表
DROP TABLE IF EXISTS ods_cart_info;
CREATE EXTERNAL TABLE ods_cart_info(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT 'skuid',
`cart_price` DECIMAL(16,2) COMMENT '放入购物车时价格',
`sku_num` BIGINT COMMENT '数量',
`sku_name` STRING COMMENT 'sku名称 (冗余)',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间',
`is_ordered` STRING COMMENT '是否已经下单',
`order_time` STRING COMMENT '下单时间',
`source_type` STRING COMMENT '来源类型',
`source_id` STRING COMMENT '来源编号'
) COMMENT '加购表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_cart_info/';
4.2.11 评论表
DROP TABLE IF EXISTS ods_comment_info;
CREATE EXTERNAL TABLE ods_comment_info(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`sku_id` STRING COMMENT '商品sku',
`spu_id` STRING COMMENT '商品spu',
`order_id` STRING COMMENT '订单ID',
`appraise` STRING COMMENT '评价',
`create_time` STRING COMMENT '评价时间'
) COMMENT '商品评论表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_comment_info/';
4.2.12 优惠券信息表
DROP TABLE IF EXISTS ods_coupon_info;
CREATE EXTERNAL TABLE ods_coupon_info(
`id` STRING COMMENT '购物券编号',
`coupon_name` STRING COMMENT '购物券名称',
`coupon_type` STRING COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` DECIMAL(16,2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16,2) COMMENT '减金额',
`benefit_discount` DECIMAL(16,2) COMMENT '折扣',
`create_time` STRING COMMENT '创建时间',
`range_type` STRING COMMENT '范围类型 1、商品 2、品类 3、品牌',
`limit_num` BIGINT COMMENT '最多领用次数',
`taken_count` BIGINT COMMENT '已领用次数',
`start_time` STRING COMMENT '开始领取时间',
`end_time` STRING COMMENT '结束领取时间',
`operate_time` STRING COMMENT '修改时间',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_coupon_info/';
4.2.13 优惠券领用表
DROP TABLE IF EXISTS ods_coupon_use;
CREATE EXTERNAL TABLE ods_coupon_use(
`id` STRING COMMENT '编号',
`coupon_id` STRING COMMENT '优惠券ID',
`user_id` STRING COMMENT 'skuid',
`order_id` STRING COMMENT 'spuid',
`coupon_status` STRING COMMENT '优惠券状态',
`get_time` STRING COMMENT '领取时间',
`using_time` STRING COMMENT '使用时间(下单)',
`used_time` STRING COMMENT '使用时间(支付)',
`expire_time` STRING COMMENT '过期时间'
) COMMENT '优惠券领用表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_coupon_use/';
4.2.14 收藏表
DROP TABLE IF EXISTS ods_favor_info;
CREATE EXTERNAL TABLE ods_favor_info(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT 'skuid',
`spu_id` STRING COMMENT 'spuid',
`is_cancel` STRING COMMENT '是否取消',
`create_time` STRING COMMENT '收藏时间',
`cancel_time` STRING COMMENT '取消时间'
) COMMENT '商品收藏表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_favor_info/';
4.2.15 订单明细表
DROP TABLE IF EXISTS ods_order_detail;
CREATE EXTERNAL TABLE ods_order_detail(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单号',
`sku_id` STRING COMMENT '商品id',
`sku_name` STRING COMMENT '商品名称',
`order_price` DECIMAL(16,2) COMMENT '商品价格',
`sku_num` BIGINT COMMENT '商品数量',
`create_time` STRING COMMENT '创建时间',
`source_type` STRING COMMENT '来源类型',
`source_id` STRING COMMENT '来源编号',
`split_final_amount` DECIMAL(16,2) COMMENT '分摊最终金额',
`split_activity_amount` DECIMAL(16,2) COMMENT '分摊活动优惠',
`split_coupon_amount` DECIMAL(16,2) COMMENT '分摊优惠券优惠'
) COMMENT '订单详情表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_order_detail/';
4.2.16 订单明细活动关联表
DROP TABLE IF EXISTS ods_order_detail_activity;
CREATE EXTERNAL TABLE ods_order_detail_activity(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单号',
`order_detail_id` STRING COMMENT '订单明细id',
`activity_id` STRING COMMENT '活动id',
`activity_rule_id` STRING COMMENT '活动规则id',
`sku_id` BIGINT COMMENT '商品id',
`create_time` STRING COMMENT '创建时间'
) COMMENT '订单详情活动关联表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_order_detail_activity/';
4.2.17 订单明细优惠券关联表
DROP TABLE IF EXISTS ods_order_detail_coupon;
CREATE EXTERNAL TABLE ods_order_detail_coupon(
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单号',
`order_detail_id` STRING COMMENT '订单明细id',
`coupon_id` STRING COMMENT '优惠券id',
`coupon_use_id` STRING COMMENT '优惠券领用记录id',
`sku_id` STRING COMMENT '商品id',
`create_time` STRING COMMENT '创建时间'
) COMMENT '订单详情活动关联表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_order_detail_coupon/';
4.2.18 订单表
DROP TABLE IF EXISTS ods_order_info;
CREATE EXTERNAL TABLE ods_order_info (
`id` STRING COMMENT '订单号',
`final_amount` DECIMAL(16,2) COMMENT '订单最终金额',
`order_status` STRING COMMENT '订单状态',
`user_id` STRING COMMENT '用户id',
`payment_way` STRING COMMENT '支付方式',
`delivery_address` STRING COMMENT '送货地址',
`out_trade_no` STRING COMMENT '支付流水号',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '操作时间',
`expire_time` STRING COMMENT '过期时间',
`tracking_no` STRING COMMENT '物流单编号',
`province_id` STRING COMMENT '省份ID',
`activity_reduce_amount` DECIMAL(16,2) COMMENT '活动减免金额',
`coupon_reduce_amount` DECIMAL(16,2) COMMENT '优惠券减免金额',
`original_amount` DECIMAL(16,2) COMMENT '订单原价金额',
`feight_fee` DECIMAL(16,2) COMMENT '运费',
`feight_fee_reduce` DECIMAL(16,2) COMMENT '运费减免'
) COMMENT '订单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_order_info/';
4.2.19 退单表
DROP TABLE IF EXISTS ods_order_refund_info;
CREATE EXTERNAL TABLE ods_order_refund_info(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`order_id` STRING COMMENT '订单ID',
`sku_id` STRING COMMENT '商品ID',
`refund_type` STRING COMMENT '退单类型',
`refund_num` BIGINT COMMENT '退单件数',
`refund_amount` DECIMAL(16,2) COMMENT '退单金额',
`refund_reason_type` STRING COMMENT '退单原因类型',
`refund_status` STRING COMMENT '退单状态',--退单状态应包含买家申请、卖家审核、卖家收货、退款完成等状态。此处未涉及到,故该表按增量处理
`create_time` STRING COMMENT '退单时间'
) COMMENT '退单表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_order_refund_info/';
4.2.20 订单状态日志表
DROP TABLE IF EXISTS ods_order_status_log;
CREATE EXTERNAL TABLE ods_order_status_log (
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单ID',
`order_status` STRING COMMENT '订单状态',
`operate_time` STRING COMMENT '修改时间'
) COMMENT '订单状态表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_order_status_log/';
4.2.21 支付表
DROP TABLE IF EXISTS ods_payment_info;
CREATE EXTERNAL TABLE ods_payment_info(
`id` STRING COMMENT '编号',
`out_trade_no` STRING COMMENT '对外业务编号',
`order_id` STRING COMMENT '订单编号',
`user_id` STRING COMMENT '用户编号',
`payment_type` STRING COMMENT '支付类型',
`trade_no` STRING COMMENT '交易编号',
`payment_amount` DECIMAL(16,2) COMMENT '支付金额',
`subject` STRING COMMENT '交易内容',
`payment_status` STRING COMMENT '支付状态',
`create_time` STRING COMMENT '创建时间',
`callback_time` STRING COMMENT '回调时间'
) COMMENT '支付流水表'
PARTITIONED BY (`dt` STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS
INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION '/warehouse/gmall/ods/ods_payment_info/';
4.2.22 退款表
DROP TABLE IF EXISTS ods_refund_payment;
CREATE EXTERNAL TABLE ods_refund_payment(
`id` STRING COMMENT '编号',
`out_trade_no` STRING COMMENT '对外业务编号',
`order_id` STRING COMMENT '订单编号',
`sku_id` STRING COMMENT 'SKU编号',
`payment_type` STRING COMMENT '支付类型',
`trade_no` STRING COMMENT '交易编号',
`refund_amount` DECIMAL(16,2) COMMENT '支付金额',
`subject` STRING COMMENT '交易内容',
`refund_status` STRING COMMENT '支付状态',
`create_time`  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2596
2596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









