 预训练语言模型与事件抽取:角色重叠解决与数据生成
预训练语言模型与事件抽取:角色重叠解决与数据生成





 本文介绍了基于预训练语言模型的事件抽取方法,解决角色重叠问题并利用生成数据增强模型。研究提出了一种损失函数重新加权策略,以提高参数提取性能,并采用事件生成技术生成高质量训练样本,改善模型在有限标注数据上的表现。实验结果显示,提出的模型在触发器和参数提取上取得了显著提升。
本文介绍了基于预训练语言模型的事件抽取方法,解决角色重叠问题并利用生成数据增强模型。研究提出了一种损失函数重新加权策略,以提高参数提取性能,并采用事件生成技术生成高质量训练样本,改善模型在有限标注数据上的表现。实验结果显示,提出的模型在触发器和参数提取上取得了显著提升。
 https://aclanthology.org/P19-1522/
https://aclanthology.org/P19-1522/关于BERT的简要介绍:
 https://zhuanlan.zhihu.com/p/98855346
https://zhuanlan.zhihu.com/p/98855346目录
一、摘要
ACE事件提取任务的传统方法通常依赖于手工标注的数据,创建这些数据通常很费力,而且大小有限。因此,除了事件提取本身的困难外,训练数据的不足也阻碍了学习过程。为了促进事件抽取,我们首先提出了一个事件抽取模型,通过根据角色分离参数预测来克服角色重叠问题。此外,为了解决训练数据不足的问题,我们提出了一种通过编辑原型自动生成标记数据的方法,并通过对质量进行排序来筛选生成的样本。在ACE2005数据集上的实验表明,我们的提取模型可以超过现有的大多数提取方法。此外,采用我们的生成方法也有了进一步的显著改进。在事件提取任务上获得了最新的研究成果,包括将触发器分类F1得分提升到81.1%,参数分类F1得分提升到58.9%。
二、介绍
事件提取是许多自然语言处理应用中一个关键且具有挑战性的任务。它的目标是检测事件触发器和参数。图1展示了一个句子,其中包含由“meeting”触发的Meet类型事件,有两个参数:“President Bush”和“several Arab leaders”,两者都扮演“Entity”的角色。

在事件提取中有两个有趣的问题需要更多的努力。一方面,事件中的角色在频率上变化很大(图2),他们可能在某些单词上重叠、甚至共享相同的参数(角色重叠问题)。例如,在句子 The explosion killed The bomber and three shoppers 中,“killed” 触发 Attack 事件,而 参数 “The bomber” 同时扮演 “Attacker” 和 “Victim” 的角色。
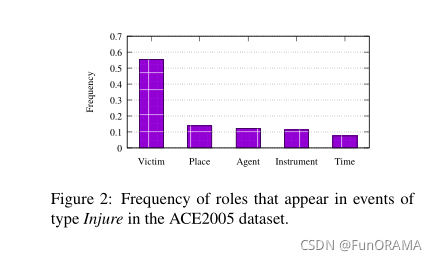
在ACE2005数据集中,大约有10%的事件存在角色重叠问题。然而,尽管有证据表明角色重叠问题,但很少有人关注它。相反,在许多方法的评价环境中,它往往被简化。例如,在以前的大多数工作中,如果一个参数同时在一个事件中扮演多个角色,只要预测击中其中任何一个,模型就能正确分类,这显然远不能准确地应用于现实世界。因此,我们设计了一种有效的机制来解决这一问题,并在实验中采用更严格的评价标准。
另一方面,到目前为止,基于深度学习的事件提取方法大多遵循监督学习范式,这需要大量的标记数据进行训练。然而,准确地注释大量数据是一项非常费力的任务。为了减轻现有方法因预定义事件数据不足而带来的困扰,通常使用事件生成方法生成额外的事件进行训练。而远程监督(Mintz et al.,2009)是一种常用的外部语料库标注技术。但远程监控产生的事件的质量和数量高度依赖于源数据。事实上,预先训练好的语言模型也可以利用外部语料库来生成句子。因此,我们转向预先训练的语言模型,试图利用它们从大规模语料库中学习到的知识来生成事件。
具体来说,本文提出了一个基于预训练语言模型的框架,其中包括一个事件提取模型作为我们的基线和一个标签化事件生成方法。我们提出的事件提取模型由触发器提取器和参数提取器组成,参数提取器引用触发器提取器的结果进行推理。此外,我们还根据角色的重要性对损失函数重新加权(re-weighting),从而提高了参数提取器的性能。
预先训练的语言模型也被用于生成标记数据。受Guu等人(2018)工作的启发,我们将现有的样本作为事件生成的原型,其中包含两个关键步骤:参数替换和附属特征重写(adjunct token rewrite)。通过对生成样本的质量进行评分,我们可以筛选出高质量的样本。将它们与现有数据结合可以进一步提高事件提取器的性能。
(此处省略了论文中相关工作部分)
三、模型介绍
本节描述提取纯文本中发生的事件的方法。我们认为事件提取是一个两阶段的任务,包括触发器提取和参数提取,并提出了基于Pre-trained Languag Model based Event Extractor (PLMEE)。图3展示了PLMEE的架构。它由一个触发器提取器和一个参数提取器组成,两者都依赖于BERT的特征表示。
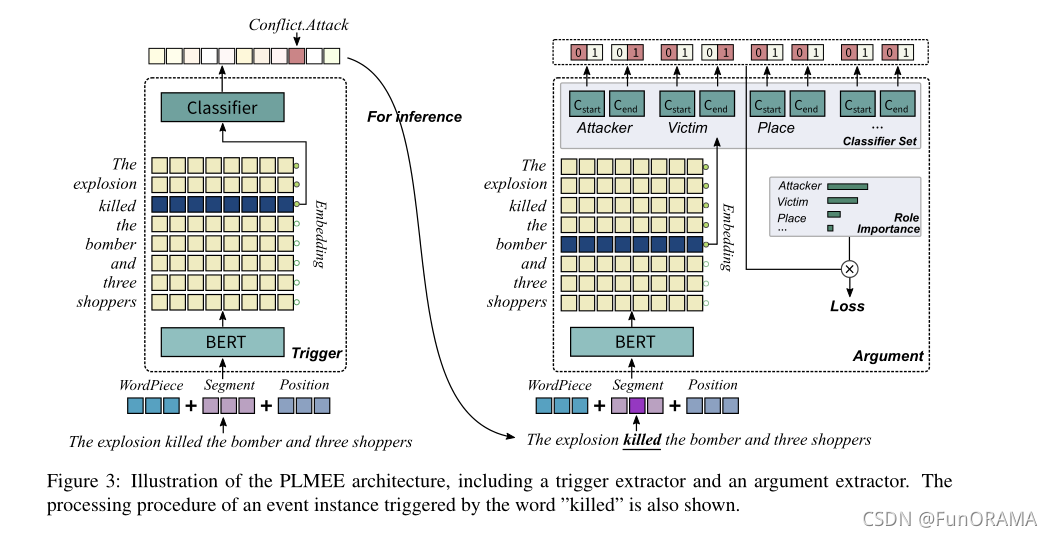
1.触发器提取
触发器提取器的目标是预测token是否触发事件。因此,我们将触发器提取定义为token级别的分类任务,并且带有表示事件类型的 标签,并在BERT上添加一个多分类器来构建触发器提取器。
触发器提取器的输入遵循BERT,即WordPiece嵌入(Wu et al., 2016)、位置嵌入和段嵌入三种类型的嵌入之和。因为输入只包含一个句子,所以它的所有段id都被设置为零。此外,标记[CLS]和[SEP]分别置于句首和句尾。
在许多情况下,触发器是一个短语。因此,我们将共享同一预测标签的连续token视为整个触发器。一般情况下,我们采用交叉熵作为损失函数进行微调。
2.参数提取
给定触发器,参数提取器旨在提取相关参数及其所扮演的所有角色。与触发器提取相比,参数提取更加复杂,主要有三个问题:参数依赖于触发器,参数多为长名词短语,角色重叠问题。我们采取了一系列的行动来处理这些障碍。
与触发器提取器一样,参数提取器也需要三种嵌入。但是,它需要知道哪些token组成触发器。因此,我们提供参数提取器,触发器标记的段id为1。
为了克服参数提取中的后两个问题,我们在BERT上添加了多组二进制分类器。每一组分类器都为一个角色服务,以确定扮演它的所有参数的范围(每个范围包括开始和结束)。这种方法类似于SQuAD (Rajpurkar et al.,2016)的问答任务,其中只有一个答案,而扮演相同角色的多个参数可以同时出现在一个事件中。由于预测是用角色分开的,一个参数可以扮演多个角色,一个token可以属于不同的参数。因此,角色重叠问题也可以得到解决。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









