






一. 痛点
美女小路今天很不开心!运维侠小白表现的时候到了。
有无数个Excel工作簿中的含有关键字的内容要提取另存?随着“一两“这几天的突飞猛进,小路也想不费事解决问题。
雪上加霜 她今天感冒了喉咙痛,中午吃饭休息时间想去买点梨,可是老球又给她安排新任务。
小路,我去帮你买梨 运维侠才不会这么傻。事实胜于雄辩,他已经到超市买完了梨,就剩下帮女神写好python代码了…

pandas是什么
是一种强大的数据分析工具,广泛应用于数据处理、清洗和分析领域。
二.基础版:使用openpyxl库代码示例
通过方法、分支循环,实现案例:将工作簿中收藏数为0的数据提取另存一个新工作簿。
⚠️建议运行前检查:
确认原始文件有"收藏数"列
确认至少有1条收藏数为0的记录
关闭所有Excel文件避免占用
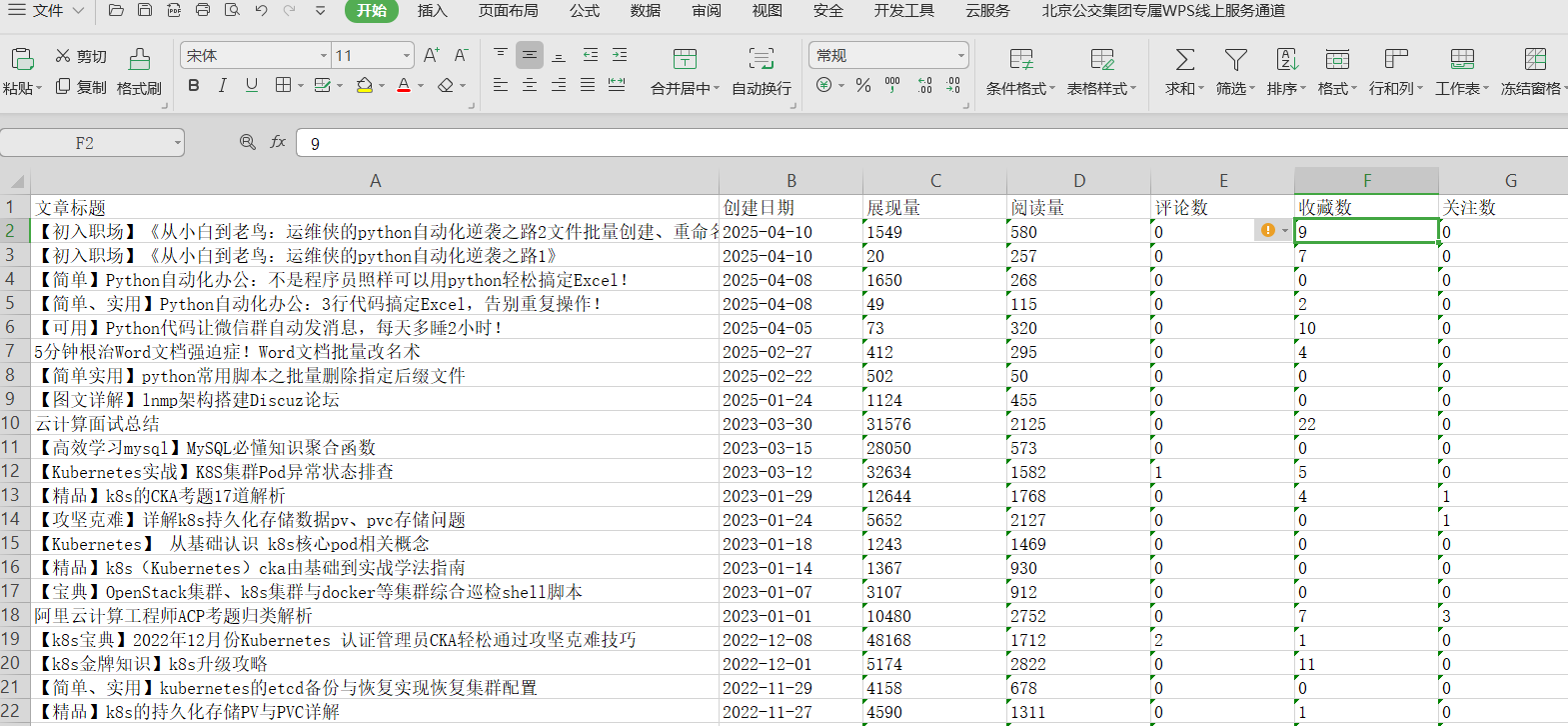
⚠️避免报错:
- 文件路径 没有写绝对路径默认是处理python代码所在路径的文件,因此需要把代码文件放到这个处理的文件同一文件夹里。
(1)学会方法def,找列位置
🚨 释义:就像我们公用的电脑,我要创建文件,判断下以前的员工有没有创建这个文件,没有就创建,有就不创建。
💻 代码:测试每个用例
# 📍 功能:像查字典目录一样找列的位置
from openpyxl import load_workbook
def 找列位置(文件路径, 列名):
"""返回列号(数字),找不到返回0"""
try:
表格 = load_workbook(文件路径).active
for 格子 in 表格[1]: # 只看标题行
if str(格子.value).strip() == 列名.strip():
return 格子.column
return 0
except:
return 0
# 🧪 独立测试功能
if __name__ == "__main__":
# 测试用例1:正常情况
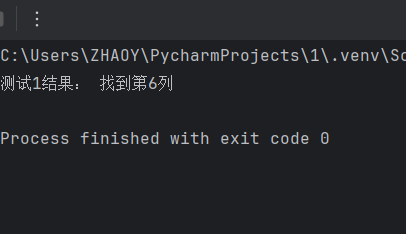
结果 = 找列位置("单篇文章分析-4月11日.xlsx", "收藏数")
print("测试1结果:", "找到第{}列".format(结果) if 结果 else "找不到列")
# # 测试用例2:列名带空格
# 结果 = 找列位置("单篇文章分析-4月11日.xlsx", " 收藏数 ")
# print("测试2结果:", "找到第{}列".format(结果) if 结果 else "找不到列")
#
# # 测试用例3:不存在的列
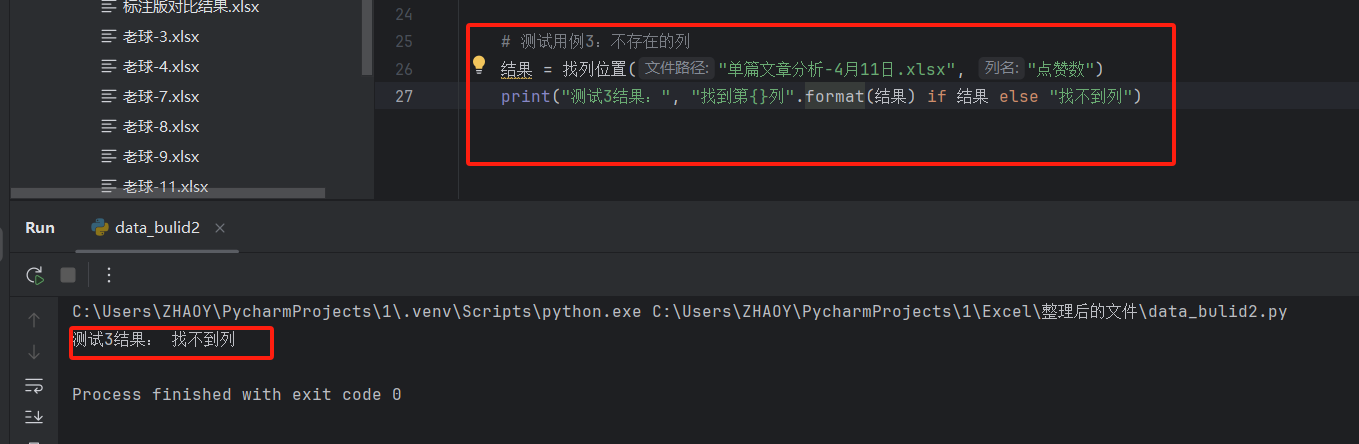
# 结果 = 找列位置("单篇文章分析-4月11日.xlsx", "点赞数")
# print("测试3结果:", "找到第{}列".format(结果) if 结果 else "找不到列")
执行代码效果:
正常用例
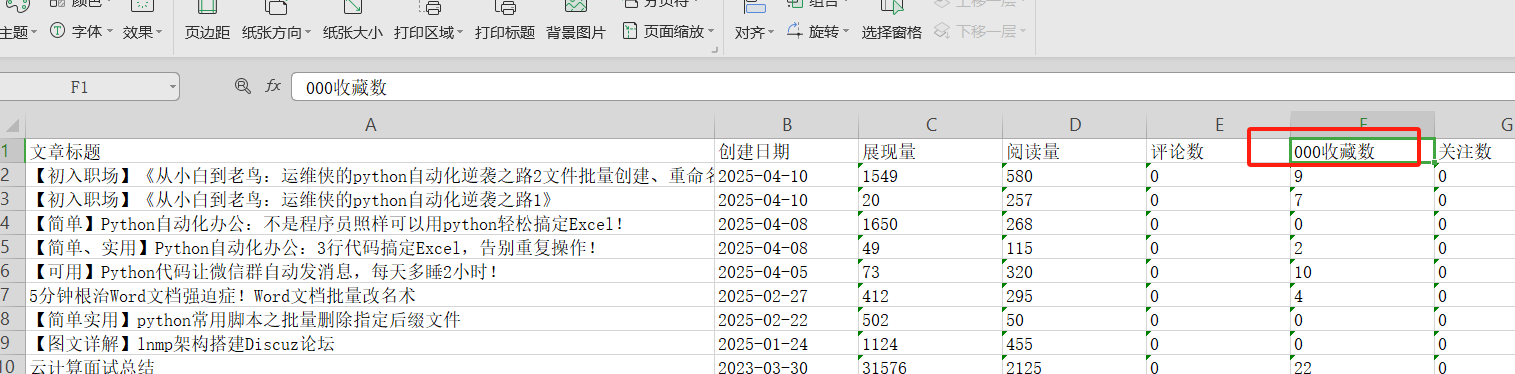
测试用例3:不存在的列,修改成错误的列名
(2)综合脚本
💻 代码:
import os # 新增的导入语句
from openpyxl import load_workbook, Workbook
def 找列位置(表格, 列名):
"""像查字典一样找列的位置"""
for 格子 in 表格[1]: # 假设标题在第一行
if str(格子.value).strip() == 列名.strip():
return 格子.column
return None
def 提取数据(原文件路径, 目标列名, 目标值):
"""主处理流程"""
try:
原文件 = load_workbook(原文件路径)
原表格 = 原文件.active
列位置 = 找列位置(原表格, 目标列名)
if not 列位置:
print(f"❌ 找不到【{目标列名}】列,请检查:")
print("当前标题行:", [cell.value for cell in 原表格[1]])
return
print(f"✅ 找到目标列:第{列位置}列({原表格.cell(1,列位置).value})")
结果数据 = []
标题行 = [cell.value for cell in 原表格[1]]
结果数据.append(标题行)
找到数量 = 0
for 行 in 原表格.iter_rows(min_row=2):
当前值 = 行[列位置-1].value
if 当前值 is not None and int(当前值) == 目标值:
结果数据.append([cell.value for cell in 行])
找到数量 += 1
if 找到数量 == 0:
print("⚠️ 没有符合条件的记录")
return
新文件 = Workbook()
新表格 = 新文件.active
新表格.title = "零收藏文章"
for 行 in 结果数据:
新表格.append(行)
新文件.save("单篇文章分析-收藏数0.xlsx")
# ✅ 已修复:添加了os模块导入后,这行就能正常工作了
print(f"✅ 成功保存{找到数量}条数据!新文件大小:{os.path.getsize('单篇文章分析-收藏数0.xlsx')}字节")
except FileNotFoundError:
print(f"❌ 文件不存在:{原文件路径}")
except Exception as e:
print(f"❌ 发生错误:{str(e)}")
# 使用示例
提取数据("单篇文章分析-4月11日.xlsx", "收藏数", 0)
执行代码效果:
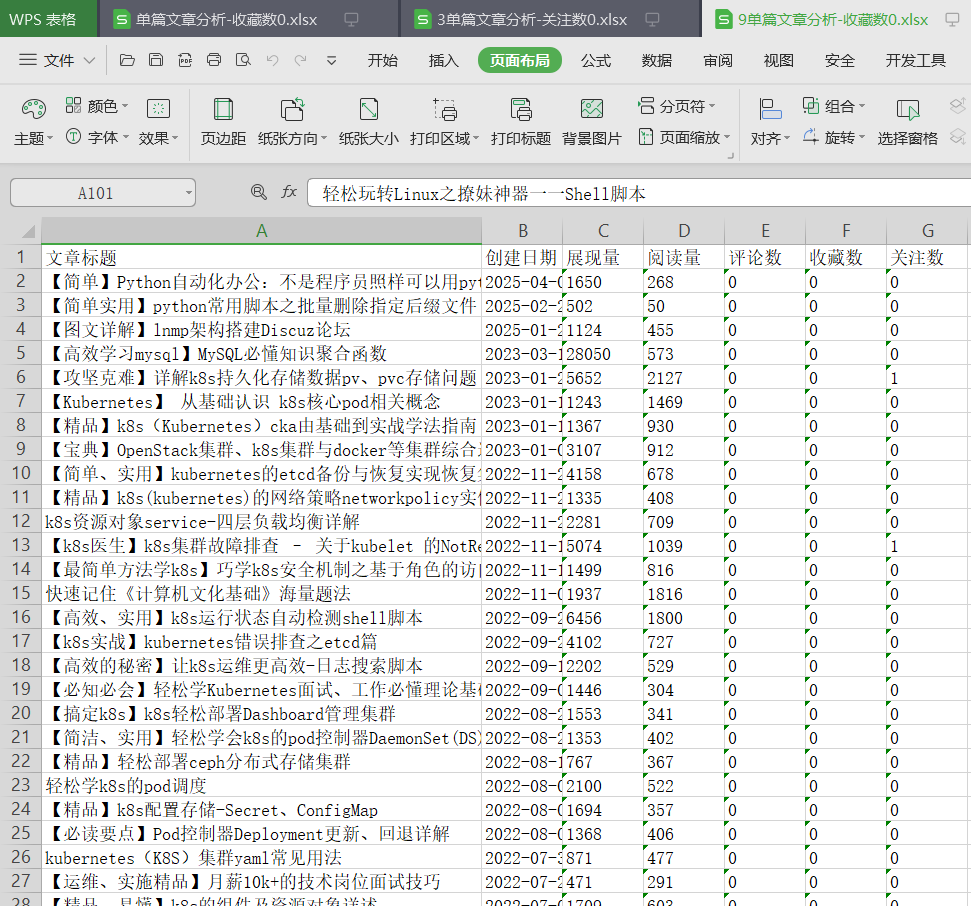
三. 进阶版:使用pandas库,代码示例
⏰提示:一种需求可以有多种类型代码实现,实际中,我们可以从中选择,最适合的。
🚨 释义:这个脚本执行速度更快
💻 代码:
import pandas as pd
# 🧺 第一步:打开文件(像打开抽屉拿文件)
原数据 = pd.read_excel('单篇文章分析-4月11日.xlsx')
# 🔍 第二步:筛选收藏数为0的行(像用放大镜找特定内容)
零收藏数据 = 原数据[原数据['收藏数'] == 0]
# 📂 第三步:保存新文件(像把找到的文件放进新文件夹)
零收藏数据.to_excel('单篇文章分析-收藏数0.xlsx', index=False)
print("已完成!新文件已保存")
执行代码效果:
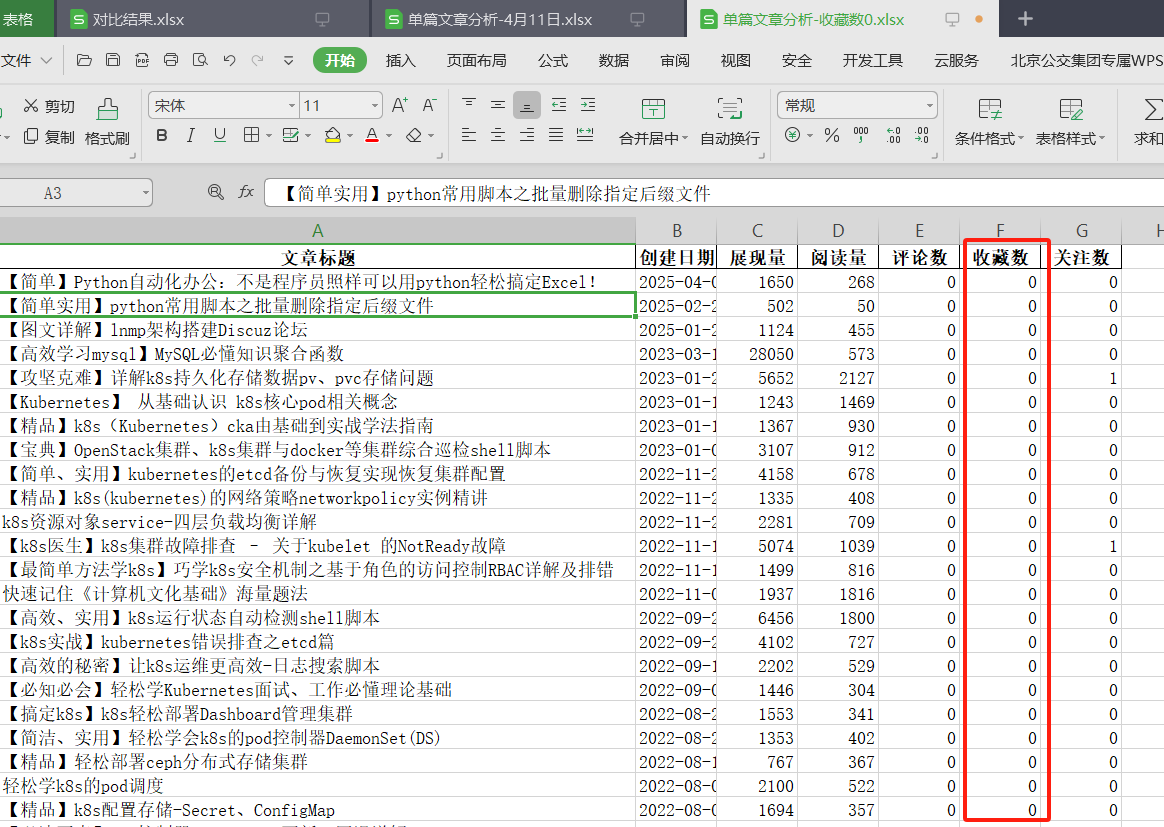
💡 朋友们!你平时用Excel最头疼的操作是什么?
💡在评论区告诉我,下期教你用Python搞定!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











