






 本文介绍了Hive数据仓库的基本概念,包括其作为基于Hadoop的数据仓库工具的特点与用途,以及安装配置过程。Hive提供了类似SQL的查询语言,简化了大数据处理流程。
本文介绍了Hive数据仓库的基本概念,包括其作为基于Hadoop的数据仓库工具的特点与用途,以及安装配置过程。Hive提供了类似SQL的查询语言,简化了大数据处理流程。
0.hive简介:
hive是基于Hadoop的一个数据仓库工具,并不是一个数据库,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive是十分适合数据仓库的统计分析和Windows注册表文件。
hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。
因此,hive 并不适合那些需要高实性的应用,例如,联机事务处理(OLTP)。hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,hive 将用户的hiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。hive 并非为联机事务处理而设计,hive 并不提供实时的查询和基于行级的数据更新操作。hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
1.特点
优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写MapReduce,减少开发人员的学习成本。
- Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合。(历史数据)
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
1.Hive的HQL表达能力有限
(1)迭代式算法无法表达 递归算法
(2)数据挖掘方面不擅长(数据挖掘和算法 机器学习 硕士以上)
2.Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗(快)
应用场景
对时效性要求不高的数据分析 , 报表分析等
2. Hive架构原理
(mysql记录元数据: hive表的数据映射 , 表结构 )
Hive架构原理
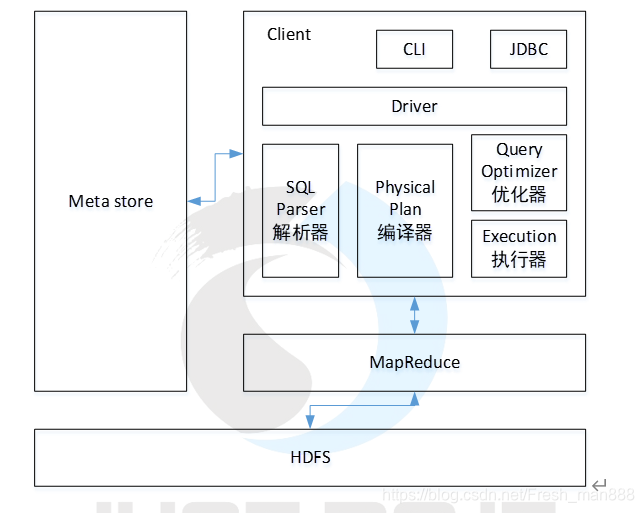
1.用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3.Hadoop
使用HDFS进行存储,yarn资源调度 ,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
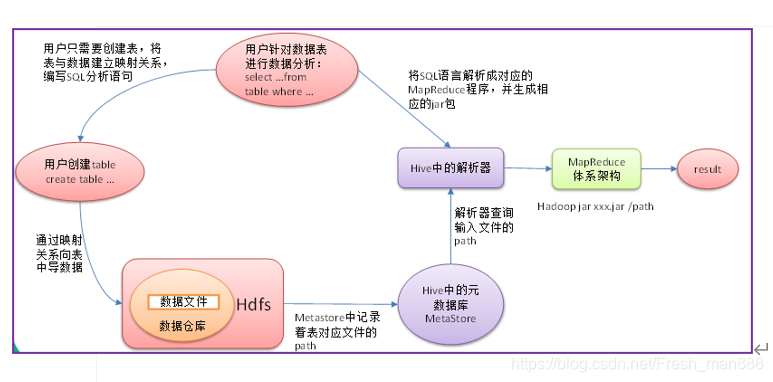
Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
3.hive的安装
1 hive的安装有两种方法:1.上传压缩包,解压 2 通过cdh的方法
2 将mysql中的密码和长度设置简单
set global validate_password_policy=LOW;
set global validate_password_length=6;3 虚拟机中安装了mysql需要开启mysql的远程连接
mysql > grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
mysql > flush privileges;
4 上传hive3.1.2的压缩包到指定的目录:/opt/apps/hive-3.1.2
5 修改配置文件:
5.1先修改hive-env.sh.template 并且改名为:hive-env.sh
# Set HADOOP_HOME to point to a specific hadoop install directory
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/opt/apps/hive-3.1.2/conf
5.2 在配置目录下添加一个hive-site.xml文件,并且添加一下配置信息
<configuration>
<!-- 记录HIve中的元数据信息 记录在mysql中 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://linux01:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
<!-- hive在hdfs中存储的数据路径 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
</property>
<!-- shell客户端连接的端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.server2.webui.host</name>
<value>0.0.0.0</value>
</property>
<!-- hive服务的页面的端口 -->
<property>
<name>hive.server2.webui.port</name>
<value>10002</value>
</property>
<property>
<name>hive.server2.long.polling.timeout</name>
<value>5000</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
<property>
<name>datanucleus.autoCreateSchema </name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore </name>
<value>true</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>mr</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>doit01,doit02,doit03</value>
</property>
</configuration>5.3 开放hive在hdfs中的操作权限,在 vi /opt/apps/hadoop-3.1.1/etc/hadoop/core.site.xml添加一下配置信息
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://linux01:8020</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>5.4 上传mysql的jdbc驱动包到hive_home的家目录下的lib目录:
mysql-connector-java-5.1.49.jar
5.5 重启hadoop进程
5.6 初始化hive的元数据信息初始化到mysql中
[root@linux01 bin]# schematool -initSchema -dbType mysql
5.7 配置hive的环境变量
/etc/profile
6 启动客户端的两种方式:
6.1 在linux中的任意目录下启动hive客户端:hive
6.2 远程连接启动:
在hive的bin目录下启动:hiveserver2 & ,这条命令属于后台启动,启动的是hive的后台服务进程
在后台服务启动之后,在bin目录下执行beeline
[root@lx01 bin]# beeline
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apps/hive-2.3.1/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/apps/hadoop-2.8.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Beeline version 2.3.1 by Apache Hive
beeline> !connect jdbc:hive2://lx01:10000
Connecting to jdbc:hive2://lx01:10000
Enter username for jdbc:hive2://lx01:10000: root
Enter password for jdbc:hive2://lx01:10000: 回车
Connected to: Apache Hive (version 2.3.1)
Driver: Hive JDBC (version 2.3.1)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://lx01:10000>
7 加载数据的两种方法:
7.1 第一种是在创建表的时候指定路径下的文件:如:location +具体文件的绝对路径
7.2 第二种是将数据上传到hdfs中表的目录下如:hdfs dfs -put+ 本地文件 +hdfs中表的目录
8 内部表和外部表
8.1 什么是外部表:
[外部表 external table]共享数据 数据可能会被多个表使用 , 一个表删除 , 不能影响其他表访问数据 , 数据文件在表删除的情况下
不会被删除;
创建外部表的语法:
create external table if not exists tb_model(
uid int,
name string
)
row format delimited fields terminated by ","
location "/data/model";8.2 什么是内部表:
[manage table 管理表]和表对应的业务数据 , 业务不要了 , 表删除 同时表目录下的 也会随着一起数据删除
内部表的创建语法,不被external修饰的就是内部表;

















 6233
6233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









