




 文章讲述了语义搜索的概念,它超越了关键词搜索的局限,利用自然语言处理和机器学习理解用户意图。文中详细介绍了文本嵌入、相似度度量(如余弦相似度)、最近邻算法在语义搜索中的应用,以及如何使用CohereAI实现一个实例。
文章讲述了语义搜索的概念,它超越了关键词搜索的局限,利用自然语言处理和机器学习理解用户意图。文中详细介绍了文本嵌入、相似度度量(如余弦相似度)、最近邻算法在语义搜索中的应用,以及如何使用CohereAI实现一个实例。
一、什么是语义搜索
语义搜索提供基于文本段落的上下文含义的搜索功能。它解决了替代方法(关键字搜索)的局限性。
例如我们来查询:“吃饭的地方”。使用语义搜索模型就能够自动将其与“餐馆”联系起来,因为它们的含义相似。而通过关键字搜索却无法做到这一点,因为搜索结果将局限于“地点”、“去”和“吃”等关键字。
这就像是与搜索引擎进行一场对话,它不仅理解你询问的内容,还理解你为什么要询问。这正是自然语言处理、人工智能和机器学习的魅力所在。它们共同努力理解用户的查询、查询的上下文以及用户的意图。语义搜索研究单词之间的关系或单词的含义,以提供比传统关键词搜索更准确、更相关的搜索结果。
二、什么是关键词搜索
在语义搜索出现之前,最流行的搜索方式是关键词搜索。假设你有一组很多句子的列表,这些句子是搜索引擎的响应内容。当你提出一个问题(查询)时,关键词搜索会查找与查询具有最大词汇共现数的句子(响应)。例如,以下面的查询和响应为例:
查询:北京天安门在哪里?
使用关键词搜索,你可以注意到响应与查询具有以下词汇共现数: 响应:
1、天安门在北京。 (共有6个词)
2、北京有很多好吃的小吃。 (共有1个词)
3、我喜欢去北京旅游。 (共有1个词)
4、北京是中国的首都。 (共有1个词)
在这种情况下,获胜的响应是编号 1,“天安门在北京”。比较幸运,这是正确的答案。然而,并不一定每次都能答对。假如还有下面这个答案:
1、在北京天安门是一个历史悠久的建筑?
这个答案与查询有 6 个词汇共现,因此如果它在响应列表中,它将会获胜。但是这却不是正确的响应。
那么这种情况一般会如何来解决呢? 我们可以通过删除“在”、“的”、“是”等停用词来改进关键字搜索。我们还可以使用 TF-IDF 等方法来区分相关词和不相关词。然而,正如您可能想象的那样,总会有这样的情况,由于语言、同义词和其他障碍的模糊性,关键字搜索将无法找到最佳响应。语义搜索在这种场景将派上了用场。
简单的理解,语义搜索的工作原理如下:
-
首先使用文本嵌入将单词转换为向量。
-
然后使用相似度算法在响应结果中查找与查询对应的向量最相似的向量。
-
最后输出与这个最相似的向量对应的响应结果。
接下来,我们将构建一个简单的语义搜索引擎。语义搜索的应用不仅仅限于构建网络搜索引擎。他们可以为内部文档或记录提供私人搜索引擎。它可用于增强 StackOverflow 的“类似问题”功能等功能。
三、如何使用文本嵌入进行搜索
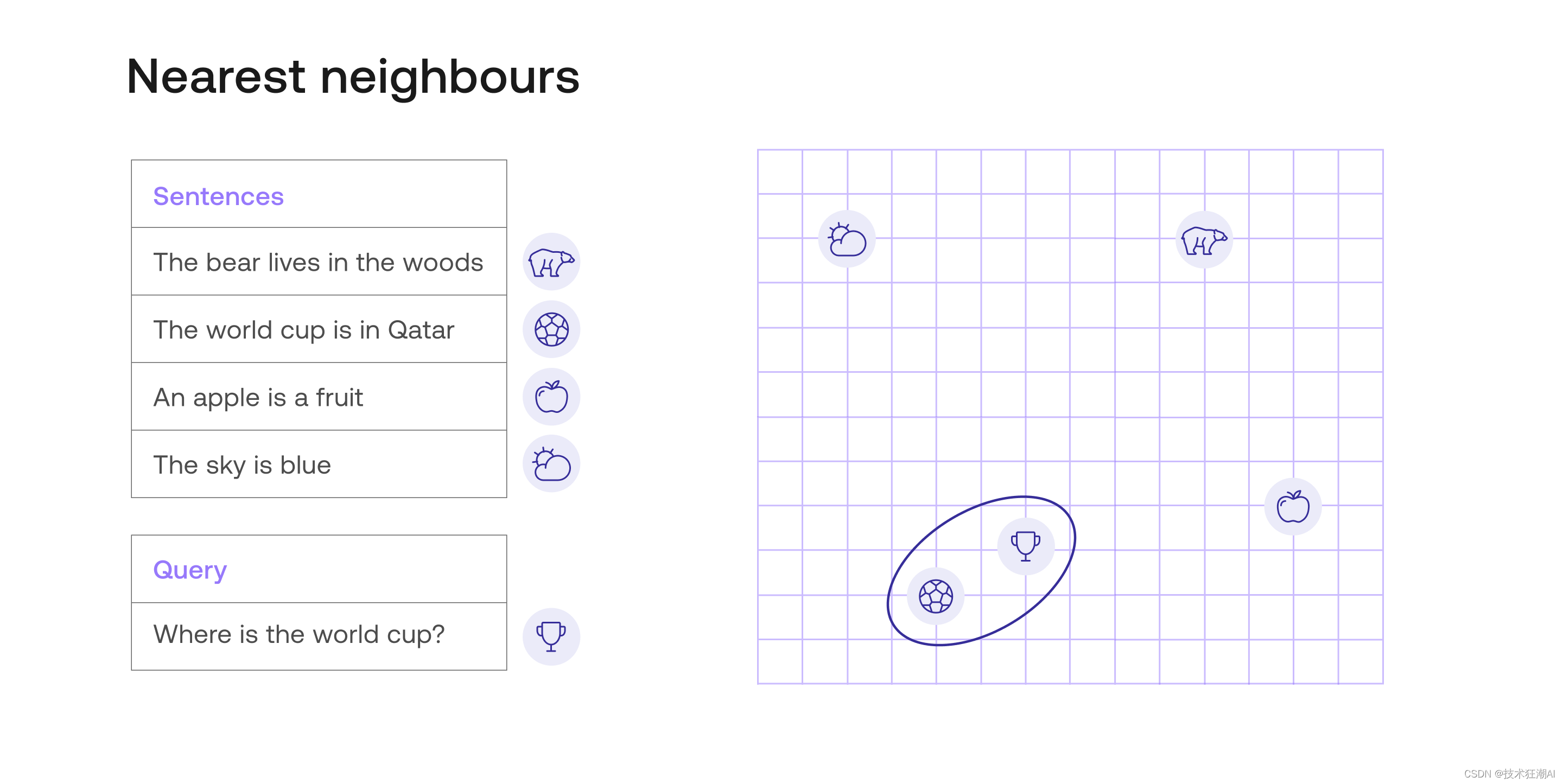
Embedding 是一种为每个句子(每个文本片段,可以是一个单词或一篇完整文章)分配向量的方法,该向量是一个数字列表。本文中使用的Cohere嵌入模型返回长度为4096的向量。这是一个包含4096个数字的列表(而其他的Cohere嵌入模型,如多语言模型,则返回长度较小的向量,例如768)。嵌入的一个非常重要的特性是相似的文本片段会被分配到相似的数字列表。例如,“你好,你好吗?”和“嗨,最近怎么样?”这两个句子将被分配到类似的数字列表中,而“明天是星期五”则被分配到与前两个句子完全不同的数字列表。
下图展示了一个嵌入示例。为了便于理解,在这个示例中每个句子都被赋予长度为2(即包含两个数字) 的向量。这些数字在右侧图表中以坐标形式绘制出来。例如,“世界杯在卡塔尔”这个句子被赋予向量(4, 2),因此它在坐标点 (4, 2) 处绘制出来。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











