




 本文探讨了生成对抗网络(GAN)在文本摘要领域的创新应用,包括解决Seq2Seq模型的局限性,提升摘要的多样性和可读性。通过结合策略梯度和注意力机制,实现了自动摘要生成的最新进展。
本文探讨了生成对抗网络(GAN)在文本摘要领域的创新应用,包括解决Seq2Seq模型的局限性,提升摘要的多样性和可读性。通过结合策略梯度和注意力机制,实现了自动摘要生成的最新进展。
本系列博文主要介绍了在文本摘要领域神经网络模型的一些发展,主要基于如下几类模型:
- Basic Encoder-Decoder model
- Encoder-Decoder + Attention
- Deep Reinforced model
- Bert based model
- GAN based model
- consideration
Generative Adversarial Network Based Model
AAAI 2018 《Generative Adversarial Network for Abstractive Text Summarization》
github:textSumGAN
抽象式摘要生成任务目的是从原始输入文本中生成一段较短且精炼的可以表述原文大意的总结性文本,它不仅包含原文中存在的词或是短语,同时还可能生新的的短语和句子。因为如何做好抽象式摘要任务是近些年来自动摘要生成领域一个很重要的任务,不同的研究人员提出了不同的模型,但是以往的模型普遍无法很好的解决如下的这些挑战:
- 基于Seq2Seq的模型生成的简洁及通用的摘要通常包含大量的高频短语,导致模型难以较为精确的表达不同类型文本的大意
- 生成的摘要通常在语法和可读性上乏善可陈
- 以往Seq2Seq的模型通常是使用最大似然估计(MLE)来不断的预测当前文本的下一个词来逐步的生成摘要
传统上基于Seq2Seq的模型不仅无法真正的解决以上的诸多挑战,而且还有一些其他的问题:
- 评价指标不同于训练损失
- 训练阶段每个时间步编码器的输入是真实摘要中的词,而测试时每个时间步编码器的输入是上一时间生成的词,这就可能会导致错误不断的累积,最后生成的文本摘要不能使用
本文是采用GAN和RL的结合来解决离散数据的处理任务,G接受原始输入文本生成一段摘要,然后和真实摘要共同输入到D中,D这里作为一个文本分类器需要判断出输入的摘要是真实的还是G生成的。D会根据判断给出反馈,G使用策略梯度进行更新,经过不断的交替训练,G最终学会生成接近于真实摘要的文本。
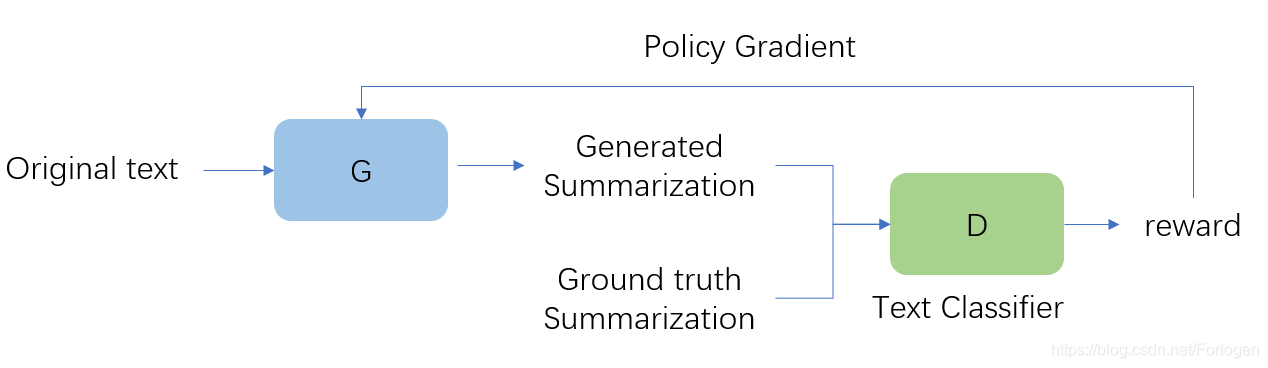
Generator
假设原始输入文本记为
x
=
{
w
1
,
w
2
,
…
,
w
n
}
x=\left\{w_{1}, w_{2}, \ldots, w_{n}\right\}
x={w1,w2,…,wn},G生成的摘要记为
y
^
=
{
y
^
1
,
y
^
2
,
…
,
y
^
m
}
\hat{y}=\left\{\hat{y}_{1}, \hat{y}_{2}, \ldots, \hat{y}_{m}\right\}
y^={y^1,y^2,…,y^m}。这里G采用的仍然是Encoder-Decoder的结构,Encoder使用的是双向LSTM,将
x
x
x转换为隐状态序列
h
=
{
h
1
,
.
.
.
,
h
n
}
h=\{h_{1},...,h_{n}\}
h={h1,...,hn}。Decoder使用基于Attention的单向LSTM,在每个时间步计算隐状态
s
t
s_{t}
st和上下文向量
c
t
c_{t}
ct,最后将
s
t
s_{t}
st和
c
t
c_{t}
ct拼接起来输入到全连接层和Softmax层中,得到每个时间步从词汇表中预测下一个词的概率
P
v
o
c
a
b
(
y
^
t
)
=
softmax
(
V
′
(
V
[
s
t
,
c
t
]
+
b
)
+
b
′
)
P_{v o c a b}\left(\hat{y}_{t}\right)=\operatorname{softmax}\left(V^{\prime}\left(V\left[s_{t}, c_{t}\right]+b\right)+b^{\prime}\right)
Pvocab(y^t)=softmax(V′(V[st,ct]+b)+b′)
其中
V
′
,
V
,
b
′
,
b
V',V,b',b
V′,V,b′,b都是需要学习的参数。
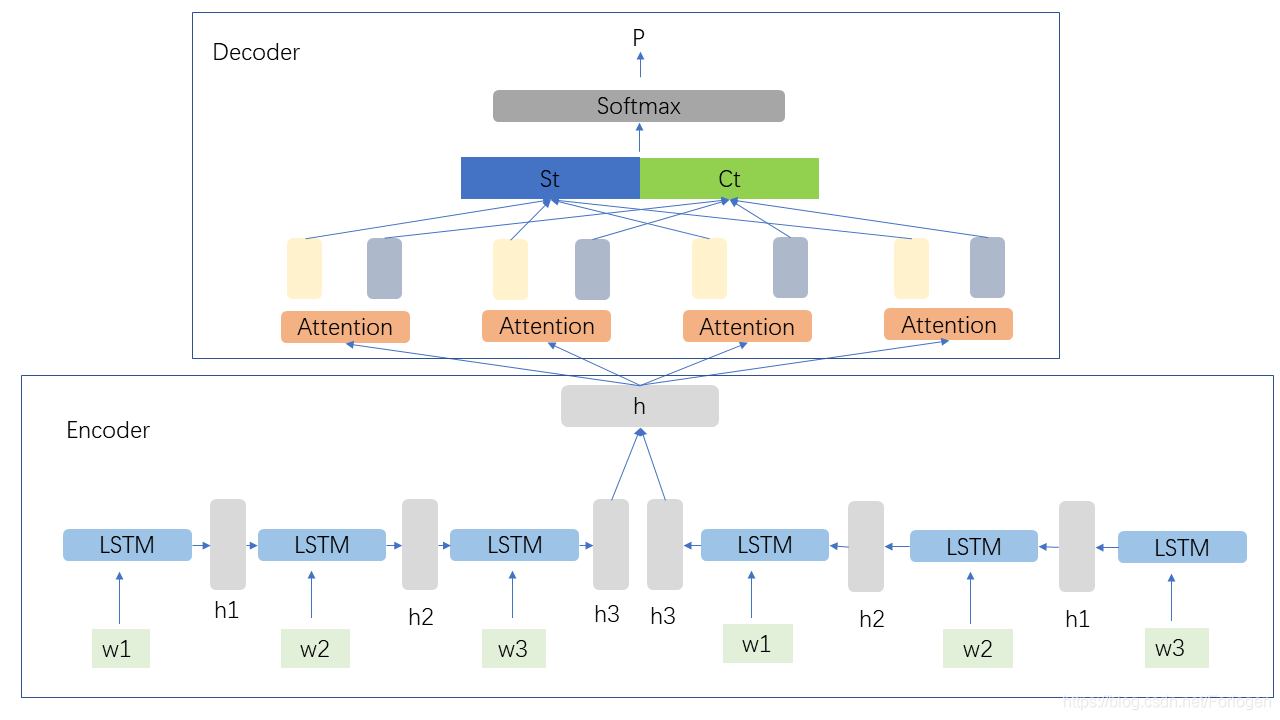
[仅是个人理解所画]
Discriminator
D这里是当作一个文本二分类器,判别输入的摘要文本是人产生的还是机器生成的。D使用CNN来处理输入序列,CNN中使用多个卷积核和变化的窗口大小来捕获不同的特征,并使用了max-pooling-over-time。最后将得到的特征输入到使用softmax的全连接层中得到判别为真实摘要的概率。
在解码阶段,先计算每个时间步的注意力分布
e
i
t
=
v
T
tanh
(
W
h
h
i
+
W
s
s
t
+
b
a
t
t
n
)
a
t
=
softmax
(
e
t
)
\begin{array}{c}{e_{i}^{t}=v^{T} \tanh \left(W_{h} h_{i}+W_{s} s_{t}+b_{a t t n}\right)} \\ {a^{t}=\operatorname{softmax}\left(e^{t}\right)}\end{array}
eit=vTtanh(Whhi+Wsst+battn)at=softmax(et)
然后计算
c
t
c_{t}
ct最后得到
P
v
o
c
a
b
(
y
^
t
)
=
softmax
(
V
′
(
V
[
s
t
,
c
t
]
+
b
)
+
b
′
)
P_{v o c a b}\left(\hat{y}_{t}\right)=\operatorname{softmax}\left(V^{\prime}\left(V\left[s_{t}, c_{t}\right]+b\right)+b^{\prime}\right)
Pvocab(y^t)=softmax(V′(V[st,ct]+b)+b′)
在训练过程中,G和D仍然采用传统GAN的对抗方式进行训练
min
ϕ
−
E
Y
∼
p
d
a
t
a
[
log
D
ϕ
(
Y
)
]
−
E
Y
∼
G
θ
[
log
(
1
−
D
ϕ
(
Y
)
)
]
\min _{\phi}-\mathbf{E}_{Y \sim p_{d a t a}}\left[\log D_{\phi}(Y)\right]-\mathbf{E}_{Y \sim G_{\theta}}\left[\log \left(1-D_{\phi}(Y)\right)\right]
ϕmin−EY∼pdata[logDϕ(Y)]−EY∼Gθ[log(1−Dϕ(Y))]
D这里作为二分类器,损失函数使用交叉熵即可,G的损失函数包含两项,由策略梯度计算的损失项
J
p
g
J_{pg}
Jpg和由最大似然估计得到的损失项
J
m
l
J_{ml}
Jml。
J
p
g
(
θ
)
=
∑
t
=
1
T
G
θ
(
y
t
∣
Y
1
:
t
−
1
,
X
)
R
D
G
o
(
(
Y
1
:
t
−
1
,
X
)
,
y
t
)
J
m
l
(
θ
)
=
−
∑
t
=
1
T
logp
(
y
t
∗
∣
y
1
∗
,
y
2
∗
,
…
,
y
t
−
1
∗
,
x
)
J_{p g}(\theta)=\sum_{t=1}^{T} G_{\theta}\left(y_{t} | Y_{1 : t-1}, X\right) R_{D}^{G_{o}}\left(\left(Y_{1 : t-1}, X\right), y_{t}\right) \\ J_{m l}(\theta)=-\sum_{t=1}^{T} \operatorname{logp}\left(y_{t}^{*} | y_{1}^{*}, y_{2}^{*}, \ldots, y_{t-1}^{*}, x\right)
Jpg(θ)=t=1∑TGθ(yt∣Y1:t−1,X)RDGo((Y1:t−1,X),yt)Jml(θ)=−t=1∑Tlogp(yt∗∣y1∗,y2∗,…,yt−1∗,x)
其中
y
∗
=
y
1
∗
,
y
2
∗
,
.
.
.
,
y
n
′
∗
y^* = {y_{1}^*, y_{2}^*, ..., y_{n^{'}}^*}
y∗=y1∗,y2∗,...,yn′∗是真实摘要的词序列。两者通过线性插值的方式得到完整的损失项
J
=
β
J
p
g
+
(
1
−
β
)
J
m
l
J=\beta J_{p g}+(1-\beta) J_{m l}
J=βJpg+(1−β)Jml,
β
\beta
β是缩放参数。
根据策略梯度的计算,参数
θ
\theta
θ的更新为
∇
θ
J
p
g
=
1
T
∑
t
=
1
T
∑
y
t
R
D
G
θ
(
(
Y
1
:
t
−
1
,
X
)
,
y
t
)
⋅
∇
θ
(
G
θ
(
y
t
∣
Y
1
:
t
−
1
,
X
)
)
=
1
T
∑
t
=
1
T
E
y
t
∈
G
θ
[
R
D
G
θ
(
(
Y
1
:
t
−
1
,
X
)
,
y
t
)
∇
θ
log
p
(
y
t
∣
Y
1
:
t
−
1
,
X
)
]
\begin{array}{l}{\nabla_{\theta} J_{p g}=\frac{1}{T} \sum_{t=1}^{T} \sum_{y_{t}} R_{D}^{G} \theta\left(\left(Y_{1 : t-1}, X\right), y_{t}\right) \cdot \nabla_{\theta}\left(G_{\theta}\left(y_{t} | Y_{1 : t-1}, X\right)\right)} \\ {\quad=\frac{1}{T} \sum_{t=1}^{T} \mathbf{E}_{y_{t} \in G_{\theta}}\left[R_{D}^{G_{\theta}}\left(\left(Y_{1 : t-1}, X\right), y_{t}\right) \nabla_{\theta} \log p\left(y_{t} | Y_{1 : t-1}, X\right)\right]}\end{array}
∇θJpg=T1∑t=1T∑ytRDGθ((Y1:t−1,X),yt)⋅∇θ(Gθ(yt∣Y1:t−1,X))=T1∑t=1TEyt∈Gθ[RDGθ((Y1:t−1,X),yt)∇θlogp(yt∣Y1:t−1,X)]
其中
R
D
G
θ
(
(
Y
1
:
t
−
1
,
X
)
,
y
t
)
R_{D}^{G_{\theta}}\left(\left(Y_{1 : t-1}, X\right), y_{t}\right)
RDGθ((Y1:t−1,X),yt)作为action-value函数,而且有
R
D
G
θ
(
(
Y
1
:
t
−
1
,
X
)
,
y
t
)
=
D
ϕ
(
Y
1
:
T
)
R_{D}^{G_{\theta}}\left(\left(Y_{1 : t-1}, X\right), y_{t}\right)=D_{\phi}\left(Y_{1 : T}\right)
RDGθ((Y1:t−1,X),yt)=Dϕ(Y1:T),同样使用SGD进行参数的更新,这里和常规使用GAN处理文本的方式并没有区别。
实验部分使用的数据集为CNN/Daily Mail Corpus,对比基准模型为:
- abstractive model(ABS)
- pointer-generator coverage networks (PGC)
- abstractive deep reinforced model (DeepRL)
评估指标为ROUGE-1、ROUGE-2、ROUGE-L和human evaluation。实验结果为:
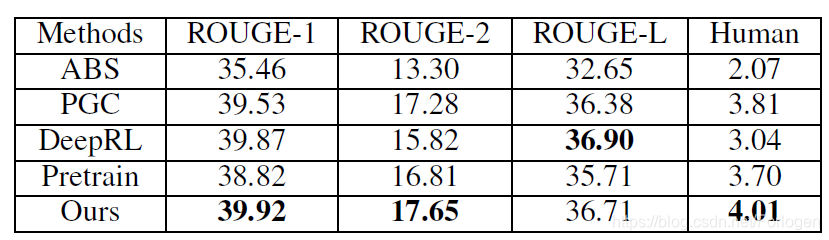
实验证明了本文提出的模型可以产生可读性更好、多样性更好的摘要,相比于基准模型在多个评估指标上都取得了state-of-the-art的效果。
此外在实验中还使用了Trigram Avoidance 避免生成重复的短语,使用Quotation Weight Alleviation 减少直接从源文本摘取短语或句子的比例。
参考文献
[1] Bahdanau, D.; Cho, K.; and Bengio, Y. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[2] See, A.; Liu, P. J.; and Manning, C. D. 2017. Get to the point: Summarization with pointer-generator networks. arXiv preprint arXiv:1704.04368.
[3] Kim, Y. 2014. Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882.
[4] Yu, L.; Zhang, W.; Wang, J.; and Seqgan, Y. Y. 2016. Sequence generative adversarial nets with policy gradient. arXiv preprint arXiv:1609.05473 2(3):5.
[5] Paulus, R.; Xiong, C.; and Socher, R. 2017. A deep reinforced model for abstractive summarization. arXiv preprint arXiv:1705.04304.
IEEE ICSC 2019 《GenerativeAdversarial Networks with Policy Gradient for Text Summarization》
这篇文章同样是使用GAN来解决抽象式摘要生成任务,与上一篇的不同之处在于引入了time-decay intra-emporal attention机制,以及在强化学习应用中使用了Stochastic Policy Gradient进行模型的更新。
抛开文章不看,首先来看一下Stochastic Policy Gradient(SPG)和之前的Policy Gradient由什么区别。
先前使用的policy gradient也称为Deterministic Policy Gradient,(DPG)。DPG的policy是从state到action的映射,因此模型的目标函数定义为
J
(
μ
θ
)
=
∫
S
ρ
μ
(
s
)
r
(
s
,
μ
θ
(
s
)
)
d
s
=
E
s
∼
ρ
μ
[
r
(
s
,
μ
θ
(
s
)
)
]
J(\mu_{\theta})= \int_{S} \rho^{\mu}(s) r(s,\mu_{\theta}(s))ds = E_{s \sim \rho^{\mu}}[r(s,\mu_{\theta}(s))]
J(μθ)=∫Sρμ(s)r(s,μθ(s))ds=Es∼ρμ[r(s,μθ(s))]
它只需要求一次积分,从它的梯度求解公式中也可以看出,DPG因需要考虑状态概率分布。
SPG中的policy是state到action概率分布的映射
π
θ
(
a
∣
s
)
=
P
(
a
∣
s
,
θ
)
\pi_{\theta}(a|s)=P(a|s,\theta)
πθ(a∣s)=P(a∣s,θ),模型的目标函数为
J
(
μ
θ
)
=
∫
S
ρ
μ
(
s
)
∫
A
∇
θ
π
θ
(
a
∣
s
)
Q
π
(
s
,
a
)
d
a
d
s
=
E
s
∼
ρ
μ
,
a
∼
π
θ
[
r
(
s
,
a
)
]
J(\mu_{\theta})= \int_{S} \rho^{\mu}(s) \int_{A} \nabla_{\theta} \pi_{\theta}(a|s)Q^{\pi}(s,a)dads = E_{s \sim \rho^{\mu},a \sim \pi_{\theta}}[r(s,a)]
J(μθ)=∫Sρμ(s)∫A∇θπθ(a∣s)Qπ(s,a)dads=Es∼ρμ,a∼πθ[r(s,a)]
它需要计算两次积分,从它的梯度求解式中可以看出,SPG同时考虑了状态概率分布以及动作概率分布。如果要进行学习训练,就需要大量的样本来覆盖整个二维的状态动作空间。
作者使用了一种更复杂的策略梯度求解方式嘛?为啥呢?
Generator
生成器同样是使用encoder-decoder模型,其中encoder使用双向LSTM,decoder使用单向LSTM,它和之前的模型并没有不同,唯一区别在于使用了time-decay intra-emporal attention,和前面 ICLR 2018 A Deep Reinforced Model for Abstractive Summarization中所使用的第二套注意力机制应该是一样的。
Discriminator
判别器使用CNN模型做二分类,正样本是文档和配套的人写的摘要,负样本为文档和生成的摘要,其他的并没有什么特别。
train
训练过程使用策略梯度进行更新,没什么不同。因为D只接收完整的序列,因此这里同样使用了SeqGAN中的蒙特卡洛搜索,最后的奖励值为N个奖励的平均值。
此外在Training stategies部分给出了详细的参数设置,还是有点借鉴意义。
实验在CNN/Daily Mail上做,评判指标是ROUGE。实验结果如下
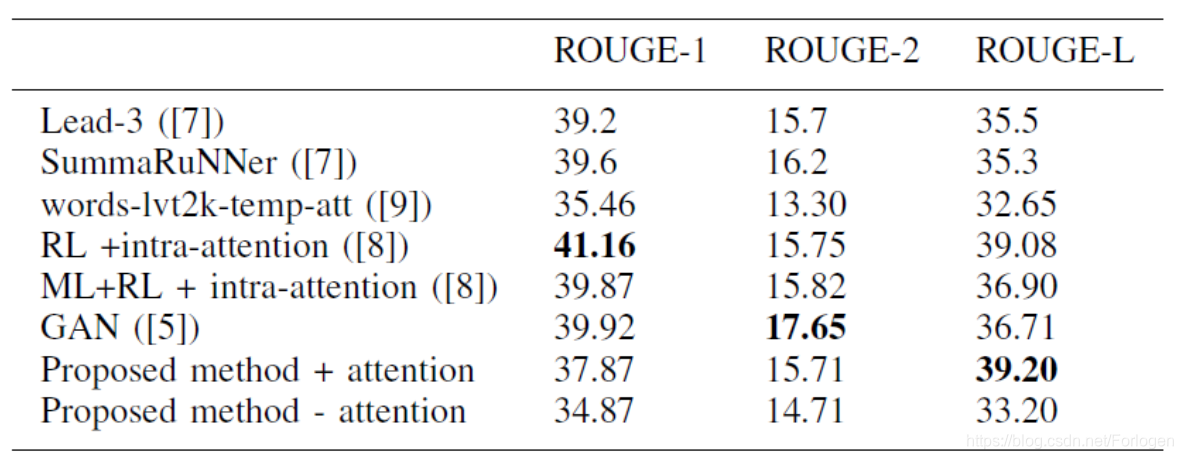
从中可以看出GAN的确可以提升模型效果,而且intra-attention也是有用的。
ICCS 2018 《Adversarial Reinforcement Learning for Chinese Text summarization》
中科院在本文中提出了一种用于中文文档的摘要生成模型,由于中文和英文有一定的区别,所以在处理方式上还是有一定的差异。
模型如下所示
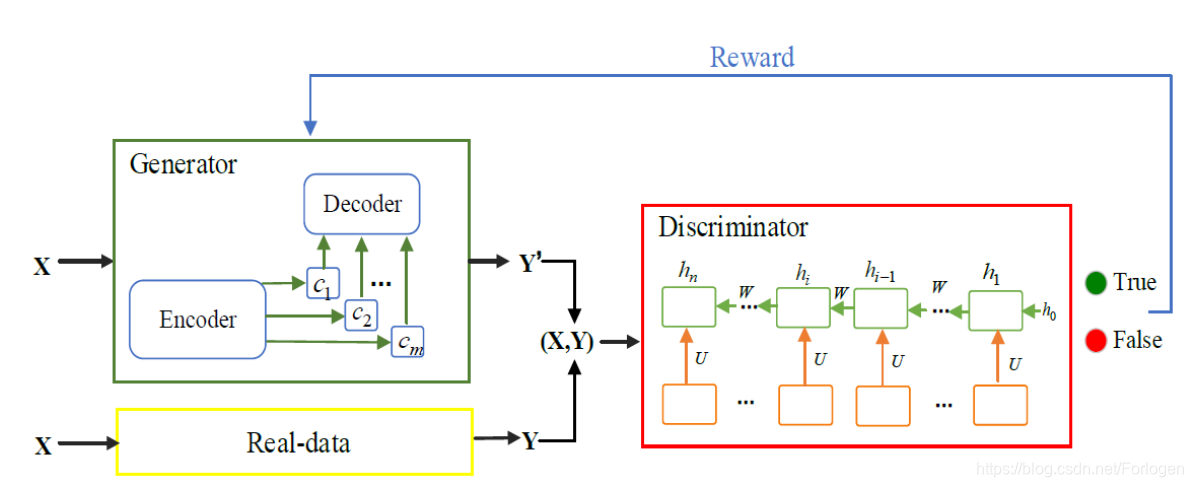
生成器同样采用了encoder-decoder模型,两部分都是使用了LSTM,在decoder中同样引入了注意力机制。
其中在decoder中使用的注意力机制称为Text-Attention。
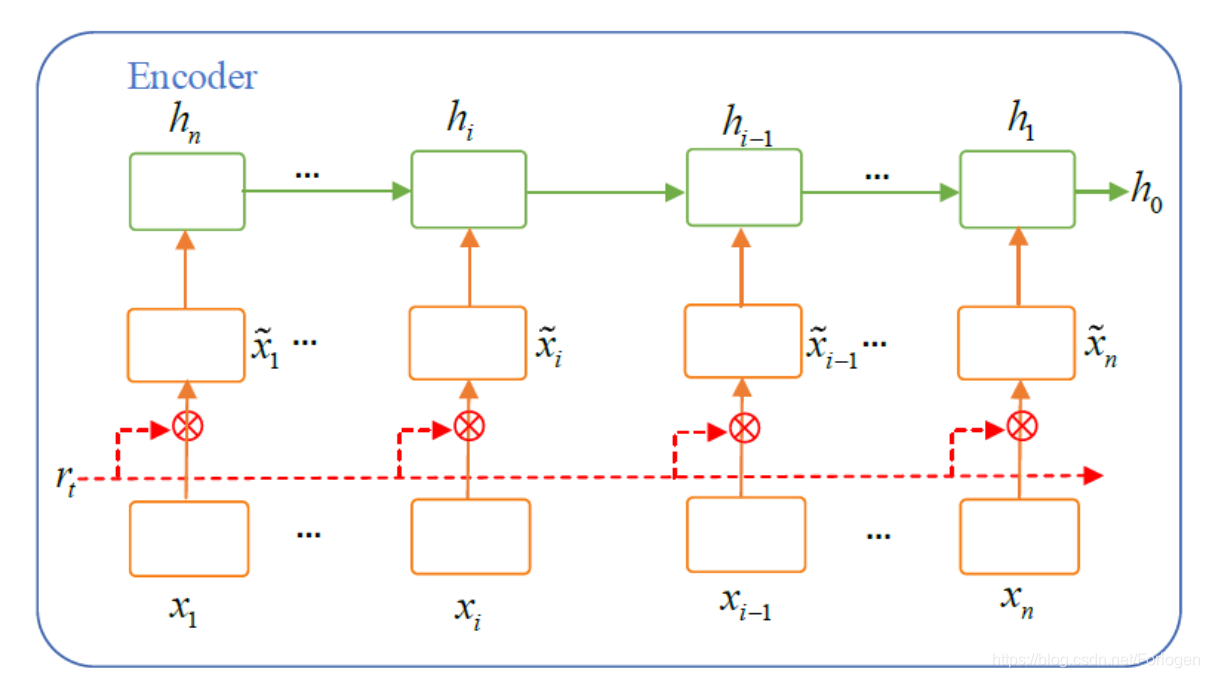
它用于在将输入文本序列
X
X
X 送到RNN之前,计算公式为:
β
i
=
σ
(
r
i
m
t
i
x
i
)
x
i
~
=
β
i
∗
x
i
\beta_{i}=\sigma(r_{i}m_{ti}x_{i}) \\ \tilde{x_{i}}=\beta_{i}* x_{i}
βi=σ(rimtixi)xi~=βi∗xi
其中
m
t
i
m_{ti}
mti为注意力矩阵,它将文本表示
x
i
x_{i}
xi转换为词嵌入的形式,
β
i
∈
[
0
,
1
]
\beta_{i} \in [0,1]
βi∈[0,1]是标量。然后就没有介绍了,不是很懂。
训练部分就是使用策略梯度,没有什么不同。
实验
实验所使用的数据集为Large Scale Chinese Short Text Summarization Dataset (LCSTS)和NLPCC Evaluation Task 4。评价指标为ROUGE-1、ROUGE-2和ROUGE-L。
基准模型有
- Abs(basic Seq2Seq model)
- Abs+(Seq2Seq model + Attention)
- Abs + TA (Seq2Seq model + Text-Attention)
- DeepRL(Deep Reinforced model)
本文提出的模型记为ARL。
在数据预处理中,为了减少中文切词的效果优劣对后续结果的影响,这里大部分使用的是字(character)而不是词(word)。
在LCSTS关于word-level的实验中,为了减小词汇表,这里只保留了前150K个频繁词,其余的用UNK标记。此外,在两种实验中都使用了word embedding来表示输入。
在训练过程中还使用了如下的tricks帮助训练:
- teacher-forcing
- gradient clipping
- mini-batch
- learning rate decay
- pre-train
在输入到判别器的负样本中,一般是使用基于互信息的beam search生成,一半是从人写的摘要中采样。
两个数据集上的实验结果如下:
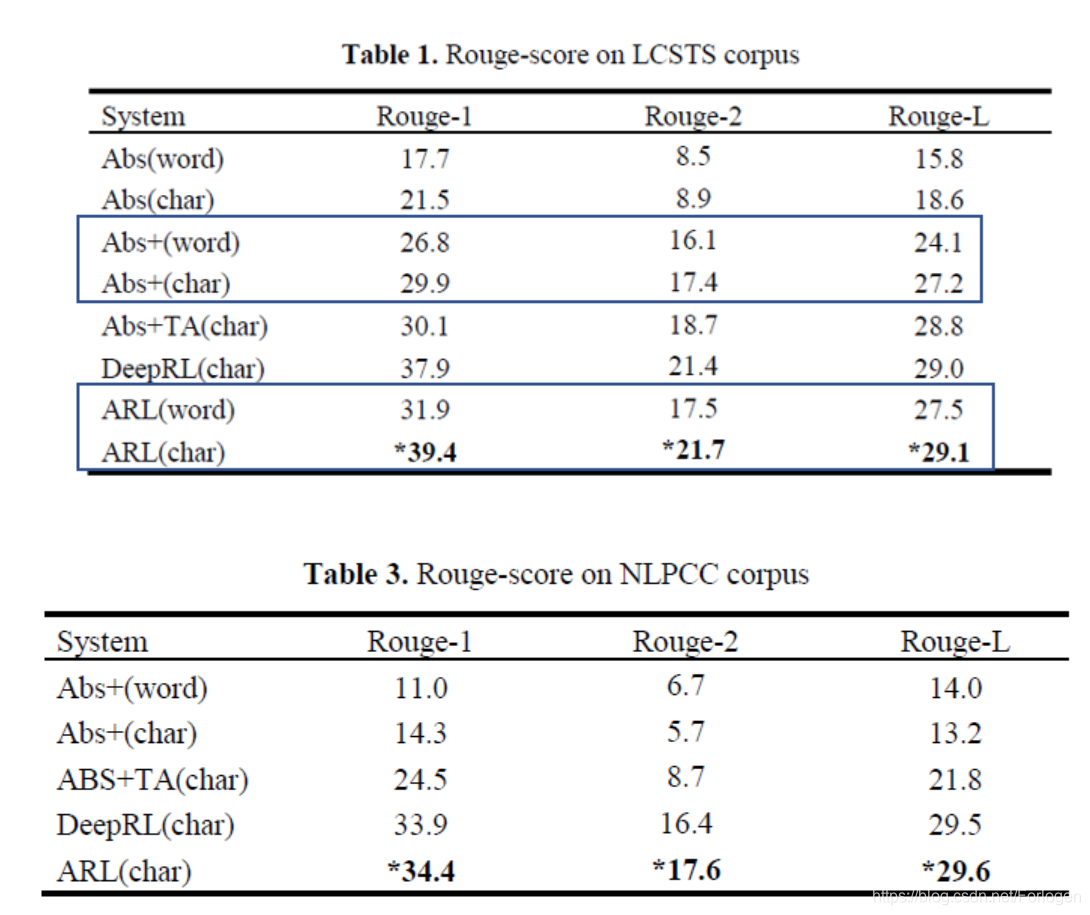
从结果中可以看出char-level的方式得到的效果更好,而且有证明了RL确实有用。

从具体实例中也可以看出ARLc方式得到的结果更好。
最后作者提出了两个思考方向:
- 如何结合汉语本身的特点构建模型
- 如何建立适用于文本摘要任务的无监督或半监督框架,减少对于高质量数据集的依赖
在整个过程中参考了很多网上的资料,由于忘记保存链接,这里就给出参考资料地址了,衷心感谢他人的付出~

















 1万+
1万+




 到【灌水乐园】发言
到【灌水乐园】发言







