




 本文介绍了一种基于注意力机制的seq2seq模型改进方法,通过read-again机制与copy机制解决了传统模型存在的次优化及UNK问题,有效提高了文本摘要的质量。
本文介绍了一种基于注意力机制的seq2seq模型改进方法,通过read-again机制与copy机制解决了传统模型存在的次优化及UNK问题,有效提高了文本摘要的质量。
论文:Efficient summarization with read-again and copy mechanism
来自:ICLR2017
本文属于NLP的文本摘要任务,采用的是生成式摘要。本文提出了目前生成式摘要所流行的基于attention的seq2seq模型所存在的两个问题:
- encoder的过程中在计算每一个词的向量表示或者隐层状态时仅仅考虑了该词之前的一些词,导致了次优化;
- UNK的问题(就是不在词表范围的词)。目前解决UNK的方法大多是通过增大词表来最小化该问题,但这样会占用大量存储空间和解码时间。
针对这两个问题,本文提出了模型的两个改进:
- 首先提出一个read-again机制,就是在encoder计算每一个词的表示之前先阅读一遍输入序列,该想法的出发点也符合人的大脑机制,在阅读一篇文章时,要读完一遍才能去确认文中哪些词是重点
- 采用copy机制来处理OOV问题,同时可以使用非常小的词库,提高了解码的效率
Baseline模型(seq2seq-attention)
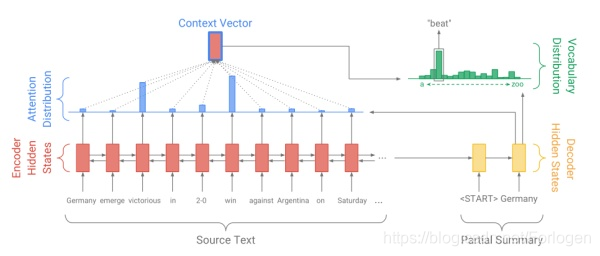
自于《 Get To The Point: Summarization with Pointer-Generator Networks》
seq2seq-attention模型通常由三部分组成:encoder、decoder和attention机制。在encoder部分可以采用一个双向LSTM或GRU,该篇文章对两个都进行了实验。输入原文的词向量序列,输出一个编码后的隐层状态序列 h i h_{i} hi;decoder部分采用一个单层单向LSTM,每一步的输入是前一步预测的词的词向量,同时输出一个解码的状态序列 s t s_{t} st,用于当前步的预测;attention是针对原文的概率分布,目的在于告诉模型在当前步的预测过程中,原文中的哪些词更重要,具体的计算公式为 e i t = v T tanh ( W h h i + W s s t + b a t t n ) a t = softmax ( e t ) \begin{array}{c}{e_{i}^{t}=v^{T} \tanh \left(W_{h} h_{i}+W_{s} s_{t}+b_{a t t n}\right)} \\ {a^{t}=\operatorname{softmax}\left(e^{t}\right)}\end{array} eit=vTtanh(Whhi+Wsst+battn)at=softmax(et)
在计算出当前步的attention分布后,对encoder输出的隐层做加权平均,获得原文的动态表示,称为语境向量最终,依靠decoder输出的隐层和语境向量,共同决定当前步预测在词表上的概率分布。
Read-Again
GRU Encoder
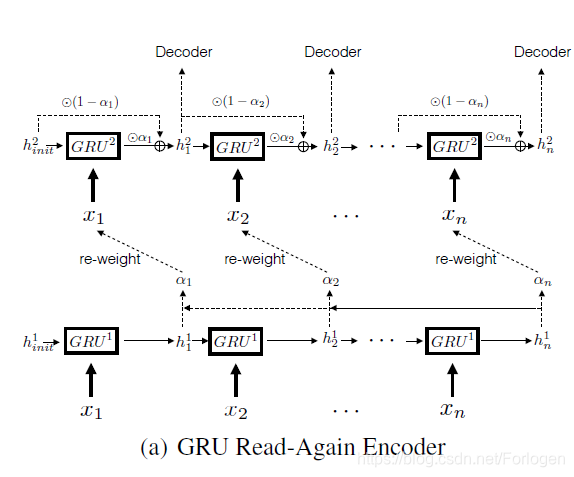
首先是在encoder采用GRU的时候加入read-again机制,首先第一层就是通读一下输入序列。得到隐层状态:
h
i
1
=
GRU
1
(
x
i
,
h
i
−
1
1
)
h_{i}^{1}=\operatorname{GRU}^{1}\left(\mathbf{x}_{\mathbf{i}}, h_{i-1}^{1}\right)
hi1=GRU1(xi,hi−11)
然后
h
n
1
h_{n}^1
hn1此时就相当于整个句子的特征向量,和对应的每个输入的隐层向量非线性组合得到
α
i
\alpha_{i}
αi,
α
i
=
tanh
(
W
e
h
i
1
+
U
e
h
n
1
+
V
e
x
i
)
\alpha_{i}=\tanh \left(W_{e} h_{i}^{1}+U_{e} h_{n}^{1}+V_{e} \mathbf{x}_{\mathbf{i}}\right)
αi=tanh(Wehi1+Uehn1+Vexi)
然后将 α i \alpha_{i} αi代入到下一个encoder中: h i 2 = ( 1 − α i ) ⊙ h i − 1 2 + α i ⊙ GRU 2 ( x i , h i − 1 2 ) h_{i}^{2}=\left(1-\alpha_{i}\right) \odot h_{i-1}^{2}+\alpha_{i} \odot \operatorname{GRU}^{2}\left(\mathbf{x}_{\mathbf{i}}, h_{i-1}^{2}\right) hi2=(1−αi)⊙hi−12+αi⊙GRU2(xi,hi−12)
当 α i \alpha_{i} αi接近于1时,左边为0,此时就是一个正常的GRU,当 α i \alpha_{i} αi接近于0的时候,此时就直接前一隐层状态,不再考虑当前输入xi了。
LSTM encoder
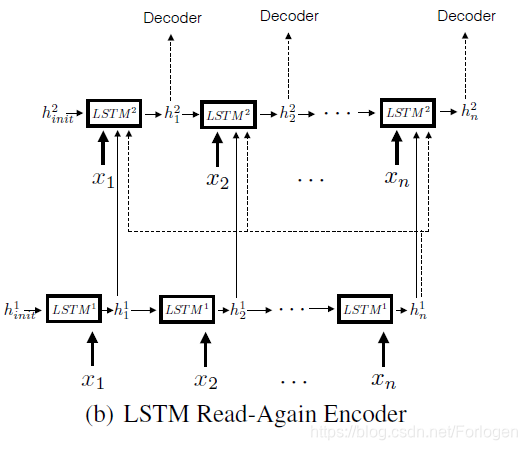
第二层隐层状态为: h i 2 = LSTM 2 ( [ x i , h i 1 , h n 1 ] , h i − 1 2 ) h_{i}^{2}=\operatorname{LSTM}^{2}\left(\left[\mathbf{x}_{\mathbf{i}}, h_{i}^{1}, h_{n}^{1}\right], h_{i-1}^{2}\right) hi2=LSTM2([xi,hi1,hn1],hi−12)
COPY机制:
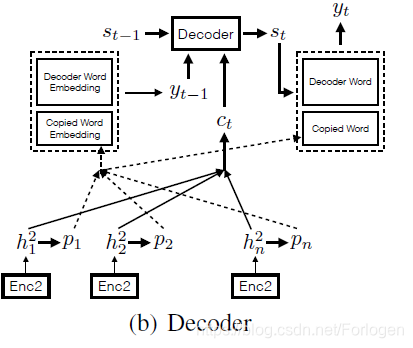
首先得到当前时刻解码的隐层状态 S t S_{t} St,通过输入之前的摘要词 y t − 1 y_{t-1} yt−1,以及context vector C t C_{t} Ct(通过attention机制得到的)。然后生成 y t y_{t} yt,而yt的生成不仅考虑target vocabulary,同时也将输入序列的词复制过来同时进行考虑。然后上一轮的 y t − 1 y_{t-1} yt−1如果是来自input的copy,那么其embedding表示为下,如果来自目标词库,就用其对应的decoder embedding即可。 y t − 1 = p i = tanh ( W c h i 2 + b c ) \mathbf{y}_{\mathbf{t}-\mathbf{1}}=\mathbf{p}_{\mathbf{i}}=\tanh \left(W_{c} h_{i}^{2}+b_{c}\right) yt−1=pi=tanh(Wchi2+bc)
实验
数据集采用的是Gigaword corpus,预处理部分用的是最初的ABS模型那篇文章的(A neural attention model for abstractive sentence summarization)。由于存在copy机制,所以target vocabulary的大小只需要15K,便得到了很好的的效果。下面是DUC2004数据集的评估:
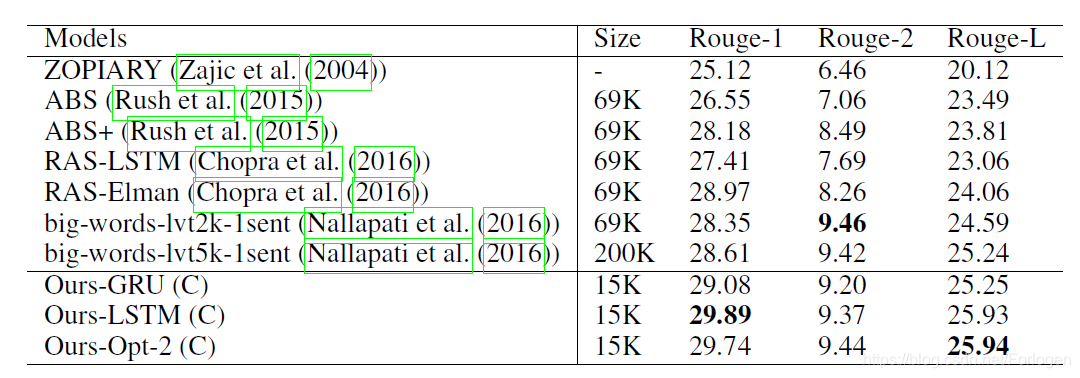
在ACL2017上的一篇论文Selective Encoding for Abstractive Sentence Summarization,与该篇论文思路相似,下面是ACL论文上的模型图:
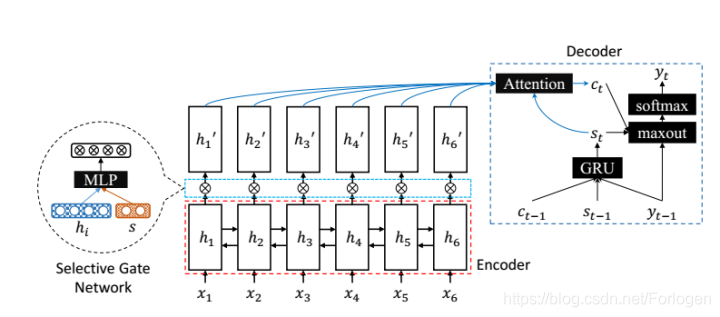
可以看出这是在原有的双向GRU的基础上对encoder的隐层状态进行了二次处理,增加了选择门网络,通过这个门网络来对输入的信息进行一次筛选,控制输入信息流向解码过程,减少了解码的压力,同时使得attention的重心更加明确。
用 s s s来表示整个输入,前向的末尾和后向的末尾隐层状态 s = [ h ‾ 1 h ⃗ n ] s=\left[\begin{array}{l}{\overline{h}_{1}} \\ {\vec{h}_{n}}\end{array}\right] s=[h1hn],首先通过输入 h i h_{i} hi和 s s s来得到门向量,然后再让对应的 h i h_{i} hi去点乘门向量。 s G a t e i = σ ( W s h i + U s s + b ) h i ′ = h i ⊙ s G a t e i \begin{aligned} s G a t e_{i} &=\sigma\left(\mathbf{W}_{s} h_{i}+\mathbf{U}_{s} s+b\right) \\ h_{i}^{\prime} &=h_{i} \odot s G a t e_{i} \end{aligned} sGateihi′=σ(Wshi+Uss+b)=hi⊙sGatei
这就很类似于上面的read-again机制,先得到整个句子的向量表示,然后再对其进行encoder,更加明确句子重点。
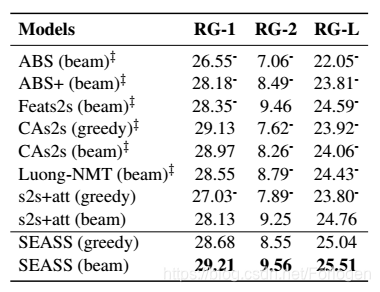
这是该模型用在DUC2004的实验结果:
总结
从目前来看,在生成摘要这一块,大多数还是采用基于attention的seq2seq模型,不过都是从改进该模型入手,该模型输出摘要是从头开始一个个输出词,这样难免会出现重要信息漏下,语句不通顺之类问题。当然还有生成模型固有的一些问题,包括重复问题,UNK问题等。但是当前的评估机制ROUGE不会关心语句通顺和重要信息漏下的问题,该评估只是看你的摘要匹配程度。

















 3107
3107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









