




IEEE Trans 《StackGAN++:Realistic Image Synthesis with Stacked Generative Adversarial Networks》

StackGAN++是StackGAN同一团队针对StackGAN所存在的一些问题所提出的改进版本,因此在文中也称为StackGAN-v2,自然之前的StackGAN就是StackGAN-v1。本文是发表在IEEE Trans上,主要是在《StackGAN:Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks》上增加了关于StackGAN++的内容,因此下面只针对之前没有提到的东西进行说明。
本文认为StackGAN++的优势主要是以下三点:
- 虽然仍然是采用多阶段逐级提高生成图像的分辨率的方式,但是不同于之前的两阶段分开训练,StackGAN++可以采用end-to-end的方式进行训练
- 对于无条件图像生成提出了一种新的正则化方式color-consistency regularization来帮助在不同的分辨率下生成更一致的图像
- 既可以用于text-to-image这样的条件图像生成任务,也可以用于更一般的无条件图像生成任务,均可以取得比其他模型更优异的结果
模型整体的架构如下所示:
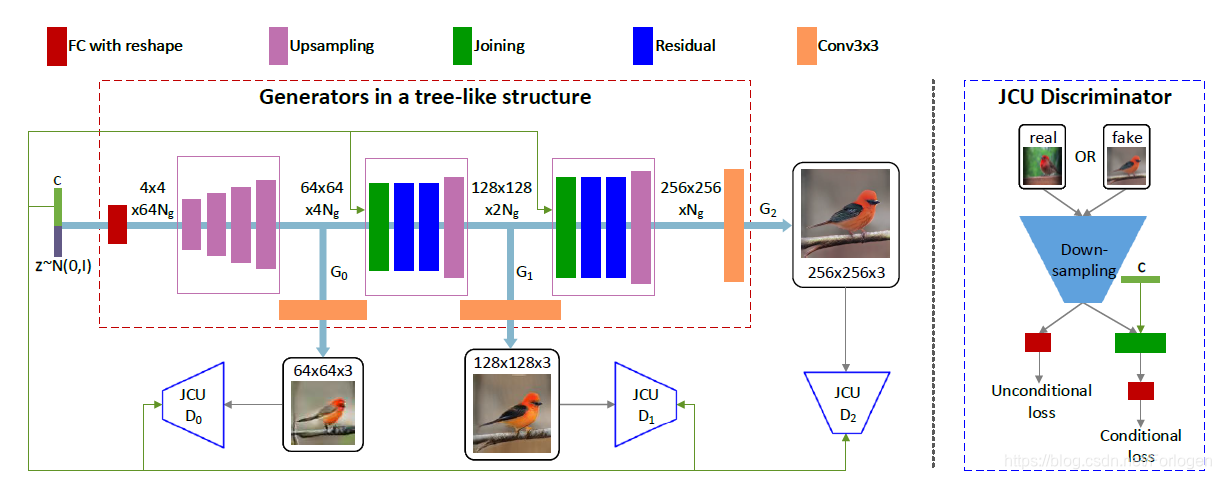
第一点
从上图可以看出,StackGAN++生成图像的分辨率变化是 4 × 4 → 64 × 64 → 128 × 128 → 256 × 256 4 \times 4 \rightarrow64 \times 64 \rightarrow128 \times 128 \rightarrow 256 \times 256 4×4→64×64→128×128→256×256,整体上构成一种树性的结构。如果将每个阶段的部分称为一个分支,那么在每个分支下生成图像用于捕获该分辨率下图像的分布,判别器用于估计生成图像是来自同分辨率真实数据分布而非生成器的概率。之所以可以采用这样的结构帮助生成高分辨率的图像,原理和我之前在StackGAN中提高的思想是一致的。将两阶段的生成变为四阶段的生成方式,那么分辨率越低,生成图像所满足的分布和真实图像所满足的分布之间的交叠就越多,生成器的训练就越容易。
假设随机噪声向量
z
∼
p
n
o
i
s
e
z \sim p_{n o i s e}
z∼pnoise采样自标准正态分布,将其在多个隐藏层之间做非线性变换得到
h
i
h_{i}
hi作为
G
i
G_{i}
Gi的输入,转换方式为
h
0
=
F
0
(
z
)
;
h
i
=
F
i
(
h
i
−
1
,
z
)
,
i
=
1
,
2
,
…
,
m
−
1
h_{0}=F_{0}(z) ; \quad h_{i}=F_{i}\left(h_{i-1}, z\right), i=1,2, \ldots, m-1
h0=F0(z);hi=Fi(hi−1,z),i=1,2,…,m−1
其中
h
i
h_{i}
hi是第
i
i
i个分支隐藏层的特征,
m
m
m是分支的总数,
F
i
F_{i}
Fi通常是神经网络。这里在每个
h
i
h_{i}
hi的产生过程中都会接收
z
z
z做为输入,作者认为这样的方式可以捕获前面分支忽略的信息。
在得到了关于 h i h_{i} hi的结果序列 ( h 0 , h 1 , … , h m − 1 ) \left(h_{0}, h_{1}, \ldots, h_{m-1}\right) (h0,h1,…,hm−1)后,使用 s i = G i ( h i ) , i = 0 , 1 , … , m − 1 s_{i}=G_{i}\left(h_{i}\right), i=0,1, \ldots, m-1 si=Gi(hi),i=0,1,…,m−1就可以生成分辨率从低到高的图像。
目标函数这里并没有太大变化,仍然采用交叉熵 L D i = − E x i ∼ p data i [ log D i ( x i ) ] − E s i ∼ p G i [ log ( 1 − D i ( s i ) ] \mathcal{L}_{D_{i}}=-\mathbb{E}_{x_{i} \sim p_{\text {data}_{i}}}\left[\log D_{i}\left(x_{i}\right)\right]-\mathbb{E}_{s_{i} \sim p_{G_{i}}}\left[\log \left(1-D_{i}\left(s_{i}\right)\right]\right. LDi=−Exi∼pdatai[logDi(xi)]−Esi∼pGi[log(1−Di(si)]。这样不同分辨率下的判别器只需关注某个分辨率尺度即可,另外它们可并行训练。生成器在判别器固定的情况,不断的逼近自己所关注的分辨率下图像所满足的真实分布,目标函数为 L G = ∑ i = 1 m L G i , L G i = − E s i ∼ p C i [ log D i ( s i ) ] \mathcal{L}_{G}=\sum_{i=1}^{m} \mathcal{L}_{G_{i}}, \quad \mathcal{L}_{G_{i}}=-\mathbb{E}_{s_{i} \sim p_{C_{i}}}\left[\log D_{i}\left(s_{i}\right)\right] LG=∑i=1mLGi,LGi=−Esi∼pCi[logDi(si)]。
通过这样的方式,StackGAN++就实现了使用端到端的方式最后生成 256 × 256 256 \times 256 256×256的高分辨率图像。
第二点
因为在整个图像的生成过程中,不同分辨率图像可能细节部分会有不同,但是它们在结构和颜色的基本方面应是一致的。因此可以通过在这些方面加些限制,帮助生成器生成色彩一致的高质量图像。
将生成图像所有的像素表示为 x k = ( R , G , B ) T \boldsymbol{x}_{\boldsymbol{k}}=(R, G, B)^{T} xk=(R,G,B)T,然后得到 μ \mu μ和 Σ \Sigma Σ ,计算公式为 μ = ∑ k x k / N , Σ = ∑ k ( x k − μ ) ( x k − μ ) T / N \boldsymbol{\mu}=\sum_{k} \boldsymbol{x}_{\boldsymbol{k}} /N,\boldsymbol{\Sigma}=\sum_{k}\left(\boldsymbol{x}_{\boldsymbol{k}}-\right.\mu)(x_{k}-\mu)^T/N μ=k∑xk/N,Σ=k∑(xk−μ)(xk−μ)T/N
而本文所提出的color-consistency regularization所做的就是最小化不同分辨率图像下 μ \mu μ和 Σ \Sigma Σ的差别,目标函数为 L C i = 1 n ∑ j = 1 n ( λ 1 ∥ μ s i j − μ s i − 1 j ∥ 2 2 + λ 2 ∥ Σ s i j − Σ s i − 1 j ∥ F 2 ) \mathcal{L}_{C_{i}}=\frac{1}{n} \sum_{j=1}^{n}\left(\lambda_{1}\left\|\boldsymbol{\mu}_{s_{i}^{j}}-\boldsymbol{\mu}_{s_{i-1}^{j}}\right\|_{2}^{2}+\lambda_{2}\left\|\boldsymbol{\Sigma}_{s_{i}^{j}}-\boldsymbol{\Sigma}_{s_{i-1}^{j}}\right\|_{F}^{2}\right) LCi=n1j=1∑n(λ1∥∥∥μsij−μsi−1j∥∥∥22+λ2∥∥∥Σsij−Σsi−1j∥∥∥F2)
但它只用在无条件图像生成中,因为在条件图像生成任务中,所附件的条件已经提供了一种很强的限制,这种低尺度下的限制就没有那么重要了。
第三点
对于无条件图像生成来说,判别只需要关注图像是真还是假,但是对于条件图像生成来说,除了判别真假外,还需要判别所给的图像是否和给的条件相符。因此关于 h i h_{i} hi的计算式为 h 0 = F 0 ( c , z ) , h i = F i ( h i − 1 , c ) h_{0}=F_{0}(c, z) , h_{i}=F_{i}\left(h_{i-1}, c\right) h0=F0(c,z),hi=Fi(hi−1,c),这里使用 c c c而不是 z z z是希望生成器更多的关注所给条件中所包含的信息。生成器和判别器的目标函数为 L D i = − E x i ∼ p d a t a i [ log D i ( x i ) ] − E s i ∼ p G i [ log ( 1 − D i ( s i ) ] ⎵ unconditional loss + − E x i ∼ p data [ log D i ( x i , c ) ] − E s i ∼ p G i [ log ( 1 − D i ( s i , c ) ] ⎵ conditional loss \mathcal{L}_{D_{i}}=\underbrace{-\mathbb{E}_{x_{i} \sim p_{d a t a_{i}}}\left[\log D_{i}\left(x_{i}\right)\right]-\mathbb{E}_{s_{i} \sim p_{G_{i}}}\left[\log \left(1-D_{i}\left(s_{i}\right)\right]\right.}_{\text { unconditional loss }}+\underbrace{-\mathbb{E}_{x_{i} \sim p_{\text {data}}}\left[\log D_{i}\left(x_{i}, c\right)\right]-\mathbb{E}_{s_{i} \sim p_{G_{i}}}\left[\log \left(1-D_{i}\left(s_{i}, c\right)\right]\right.}_{\text { conditional loss }} \\ LDi= unconditional loss −Exi∼pdatai[logDi(xi)]−Esi∼pGi[log(1−Di(si)]+ conditional loss −Exi∼pdata[logDi(xi,c)]−Esi∼pGi[log(1−Di(si,c)] L G i = − E s i ∼ p G i [ log D i ( s i ) ] ⎵ unconditional loss + − E s i ∼ p G i [ log D i ( s i , c ) ] ⎵ conditional loss \mathcal{L}_{G_{i}}=\underbrace{-\mathbb{E}_{s_{i} \sim p_{G_{i}}}\left[\log D_{i}\left(s_{i}\right)\right]}_{\text { unconditional loss }}+\underbrace{-\mathbb{E}_{s_{i} \sim p_{G_{i}}}\left[\log D_{i}\left(s_{i}, c\right)\right]}_{\text { conditional loss }} LGi= unconditional loss −Esi∼pGi[logDi(si)]+ conditional loss −Esi∼pGi[logDi(si,c)]但因为生成器使用了color-consistency 正则项,所以最后的目标函数为 L G i ′ = L G i + α ∗ L C i \mathcal{L}_{G_{i}}^{\prime}=\mathcal{L}_{G_{i}}+\alpha * \mathcal{L}_{C_{i}} LGi′=LGi+α∗LCi。
总结
整体上来说,StackGAN++做为StackGAN的改进版,它可以以端到端的方式生成更好质量的图像,而且训练过程更加稳定。但是StackGAN分阶段的训练方式收敛速度更加快,所需的GPU内存也更少。


















 1104
1104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









