




 本文介绍了Auto-encoder,它是基本生成模型,提供encoder-decoder框架思想。阐述了其结构、训练方式,还提及用其他方式衡量Encoder表征,如借助GAN思想的Deep InfoMax。此外,介绍了在序列数据上的应用,以及实现特征解耦、获取离散Embedding的方法和相关模型。
本文介绍了Auto-encoder,它是基本生成模型,提供encoder-decoder框架思想。阐述了其结构、训练方式,还提及用其他方式衡量Encoder表征,如借助GAN思想的Deep InfoMax。此外,介绍了在序列数据上的应用,以及实现特征解耦、获取离散Embedding的方法和相关模型。
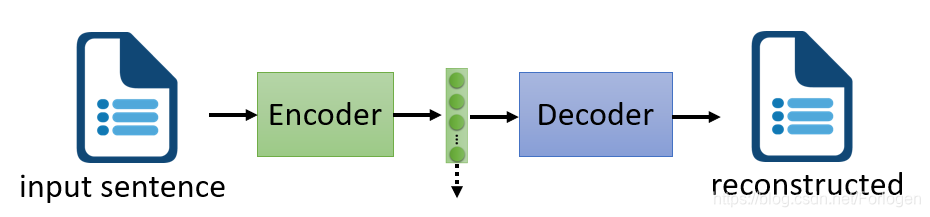
Auto-encoder是一个基本的生成模型,更重要的是它提供了一种encoder-decoder的框架思想,广泛的应用在了许多模型架构中。简单来说,Auto-encoder可以看作是如下的结构,它主要包含一个编码器(Encoder)和一个解码器(Decoder),通常它们使用的都是神经网络。Encoder接收一张图像(或是其他类型的数据,这里以图像为例)输出一个vector,它也可称为Embedding、Latent Representation或Latent code,不管它叫什么,我们只需要知道它是关于输入图像的表示;然后将vector输入到Decoder中就可以得到重建后的图像,希望它和输入图像越接近越好,即最小化重建误差(reconstruction error),误差项通常使用的平方误差。
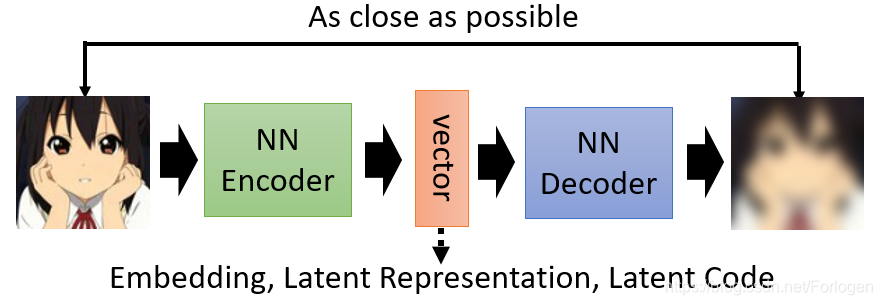
虽然我们希望Decoder输出的重建图像和输入到Encoder中的图像越接近越好,但是通常我们并不关注重建后的图像是什么样的,更多的希望得到一个关于输入图像有意义、解释性强的embedding。如何评价一个embedding是否是好的呢?最直观的想法是它应该包含了关于输入的关键信息,从中我们就可以大致知道输入是什么样的。或是从流形学习的角度来看,希望它可以学到关于高维输入数据的低维嵌入。比如当我们看到蓝色耳机时,我们想到的是三九,而不应是一花,那么蓝色耳机对于三九就是一个好的embedding,对于一花来说就不是一个好的embedding。

题外话:不知道三九、一花的可以看一下《五等分的花嫁》 ,这里给出B站上的? https://www.bilibili.com/bangumi/media/md4316382/?from=search&seid=4116935819205101932
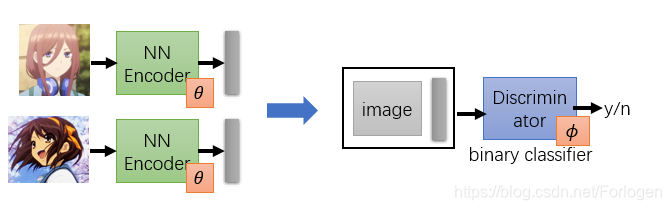
那么除了使用重建误差来驱动模型训练外,可以使用其他的方式来衡量Encoder是否学到了关于输入的重要表征吗?答案自然是YES!假设我们现在有两类动漫人物的图像,一类是三九,一类是凉宫春日。如果将三九的图像丢给Encoder后,它就会给出一个蓝色的Embedding;如果Encoder接收的是凉宫春日的图像,它就会给出一个黄色的Embedding。那么除了Encoder之外,还有一个Discriminator(这里可以就看作一个二分类的Classifier),它接收图像和Embedding,然后给出一个结果表示它们是否是两两对应的。

如果是三九和蓝色的Embedding、凉宫春日和黄色的Embedding,那么Discriminator给出的就是YES;如果它们彼此交换一下,Discriminator给出的就应该是NO。借助GAN的思想,我们用 Φ \Phi Φ来表述Discriminator,希望通过训练最小化D的损失函数 L D ∗ = min ϕ L D L_{D}^{*}=\min _{\phi} L_{D} LD∗=minϕLD,得到最小的损失值 L D ∗ L_{D}^* LD∗。如果 L D L_{D} LD的值比较小,就认为Encoder得到的Embedding很有代表性;相反如何 L D L_{D} LD的值很大时,就认为得到的Embedding不具有代表性。
如果同样的使用 Θ \Theta Θ表示Encoder,希望通过训练Encoder最小化 L D ∗ L_{D}^* LD∗,即 θ ∗ = arg min θ min ϕ L D \theta^*=\arg \min _{\theta} \min _{\phi} L_{D} θ∗=argminθminϕLD,这样的方法也称为Deep InfoMax(DIM)。
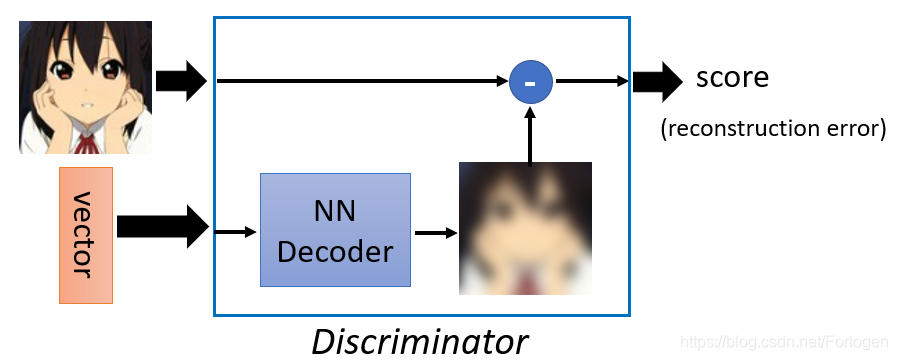
上述的这种方式其实还可以认为是在最小化重建误差,怎么理解呢?Discriminator接收一个图像和vector的组合,然后给出一个判断它们是否是配对的分数。在D的内部它同样是先使用Decoder来解码vector生成一个重建的图像,然后和输入图像相比较,看它们是否是足够的接近。
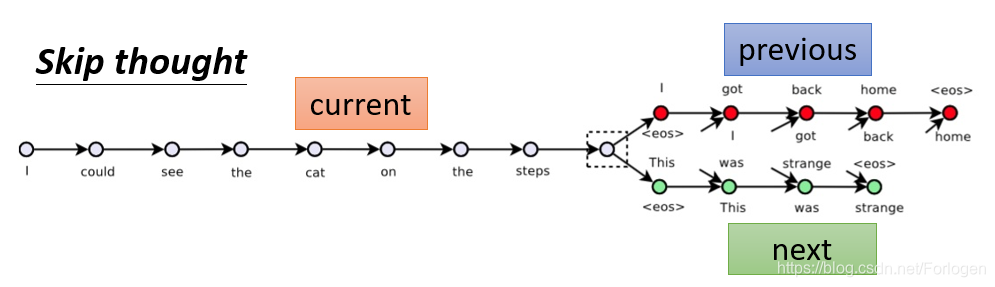
除了图像数据外,我们也可以在序列数据上使用Encoder-Decoder的结构模型。例如有一种叫Skip thought的方法,模型在大量的文档数据上训练结束后,Encoder接收一个句子,然后给出输入句子的上一句和下一句是什么。
而Quick thought是对于Skip thought的改进版本,它不使用Decoder,而是使用一个辅助的分类器。它将当前的句子、当前句子的下一句和一些随机采样得到的句子分别送到Encoder中得到对应的Embedding,然后将它们丢给分类器。因为当前的句子的Embedding和它下一句的Embedding应该是越接近越好,而它和随机采样句子的Embedding应该差别越大越好,因此分类器应该可以根据Embedding判断出哪一个代表的是当前句子的下一句。
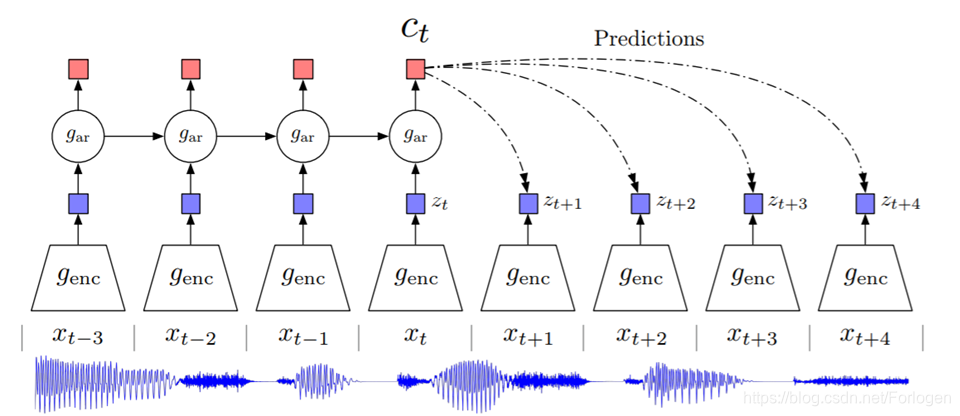
还有一个称为Contrastive Predictive Coding (CPC)的技术,它同样接收一段序列数据,然后给出它的接下来数据的预测结果。模型结构如下所示,具体内容可见原论文。
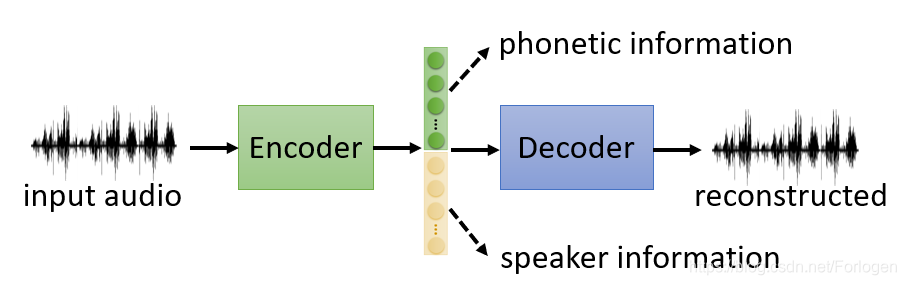
接下来我们来看如何得到解释性更好的Embedding,这样的方法也可以称为Feature Disentangle(特征结构)。因为对于Encoder的输入数据来说,经过Encoder得到的Embedding其实包含了关于它的很多类型的信息。例如,如果现在输入的是一段声音讯号,那么Embedding可能包含内容信息、讲话者的信息……

如果输入的是一段文字,Embedding可能包含关于它的句法信息、语义信息……
我们以声音讯号为例,假设通过Encoder得到的Embedding是一个100维 的向量,它只包含内容和讲话者身份两种信息。我们希望经过不断的训练,它的前50维代表内容信息,后50维代表讲话者的身份信息。
例如现在有两条数据,分别是一个女性讲“How are you?”和一个男性讲“Hello”,如果上述的希望可以实现的话,它们分别的Embedding的表示应该是下面的样子。
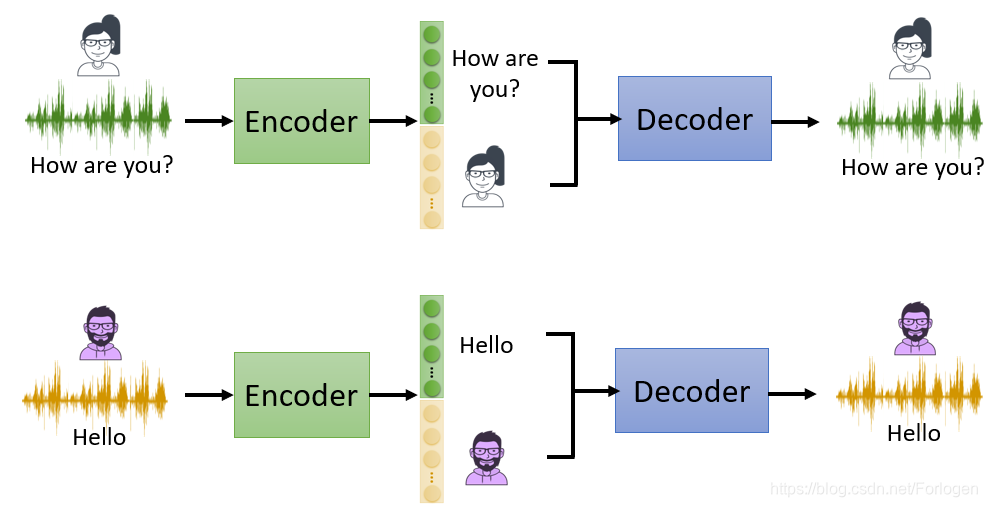
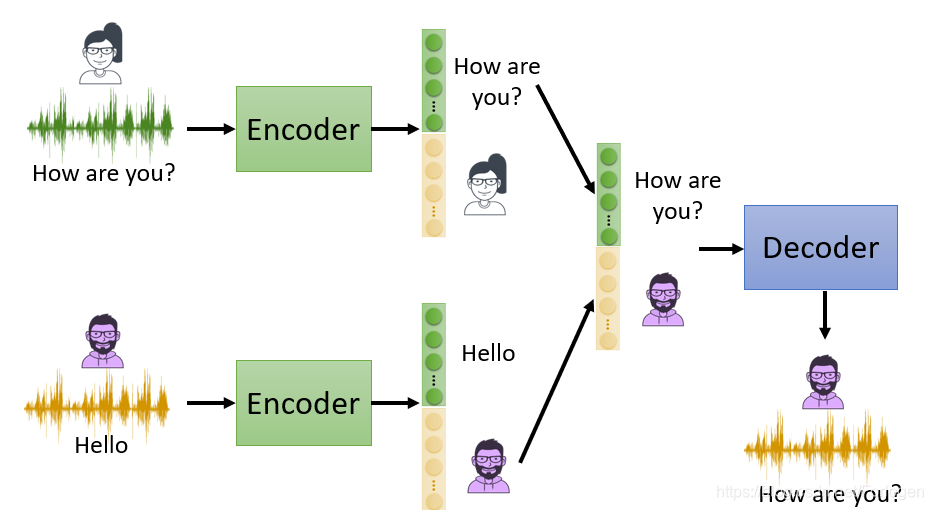
那么这样的方法具体有什么用呢?如果可以实现Embedding的不同部分代表不同的信息,而它代表的信息类型是知道的,我们就可以使用它来做变声器。如下所示,输入的信息还是一个女性讲“How are you?”和一个男性讲“Hello”,中间如果讲它们的Embedding不同的部分组合起来送到Decoder中,就可以得到男性讲“How are you?”或是女性讲“Hello”。
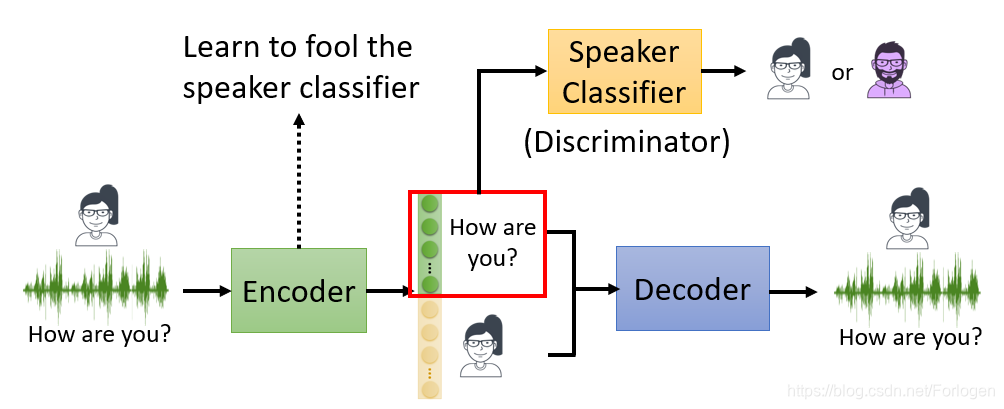
那么如何来实现Feature Disentangle呢?一种方法就是使用GAN对抗的思想,我们在一般的Encoder-Decoder架构中引入一个Classifier,判别Embedding某个具体的部分是否代表了讲话者身份的信息,通过不断地训练,希望Encoder得到的Embedding可以骗过Classifier,那么那个具体的部分就表示了讲话者的信息。
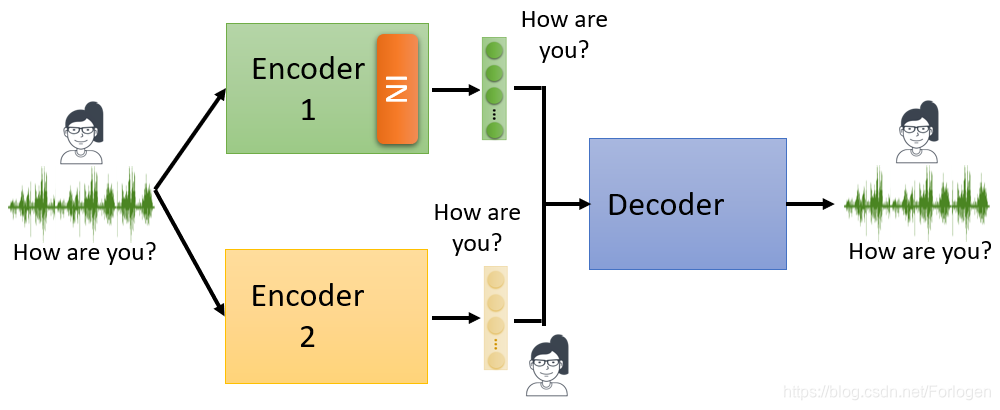
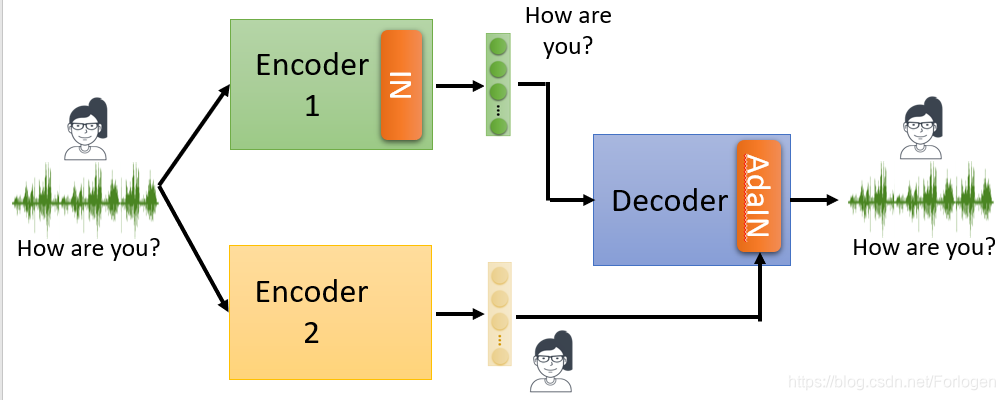
另一种方式是改变网络结构,比如使用两个Encoder来分别得到内容信息和讲话者身份信息的Embedding,同时在Encoder中使用instance normalization,然后将得到的两个Embedding结合起来送入Decoder重建输入数据。
除了将两个Embedding直接组合起来的方式,还可以在Decoder中使用Adaptive instance normalization
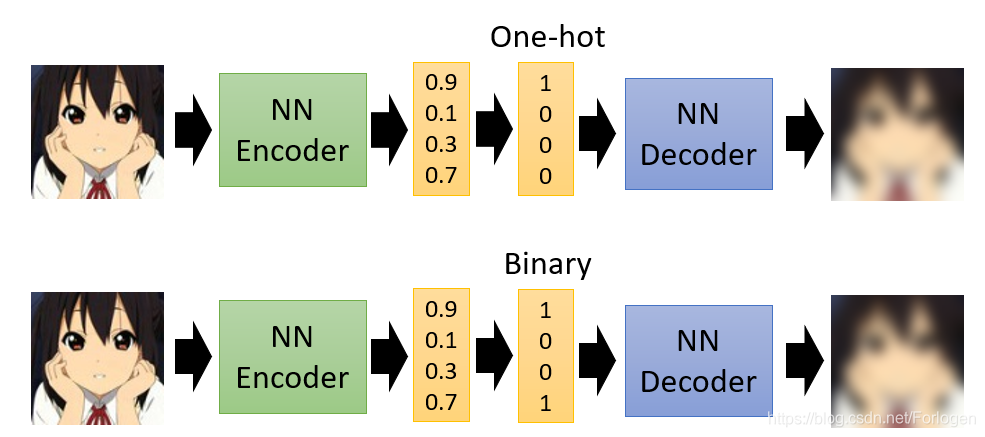
通常情况下,Encoder输出的Embedding都是连续值的向量,这样才可以使用反向传播算法更新参数。但如果可以将其转换为离散值的向量,例如one-hot向量或是binary向量,我们就可以更加方便的观察Embedding的哪一部分表示什么信息。当然此时不能直接使用反向传播来训练模型,一种方式就是用强化学习来进行训练。
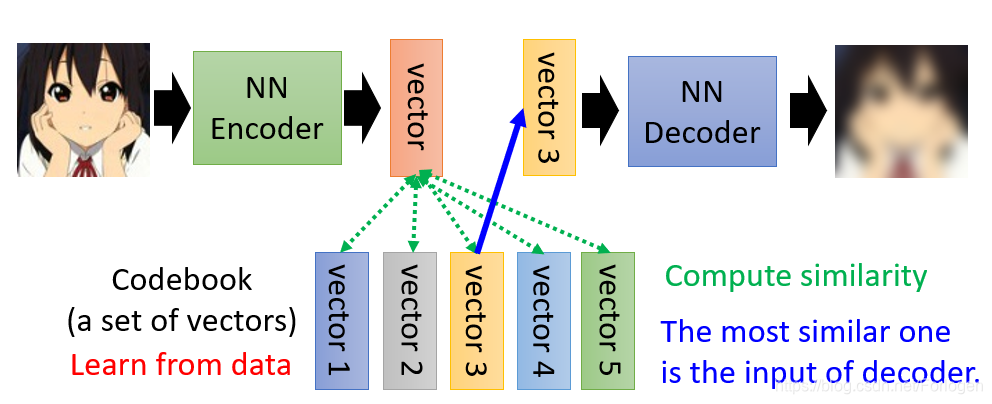
基于这样的想法就出现了一种方法叫Vector Quantized Variational Auto-encoder (VQVAE),它引入了一个Code book。它是将Embedding分为了很多的vector,然后比较哪一个和输入更像,就将其丢给Decoder重建输入。
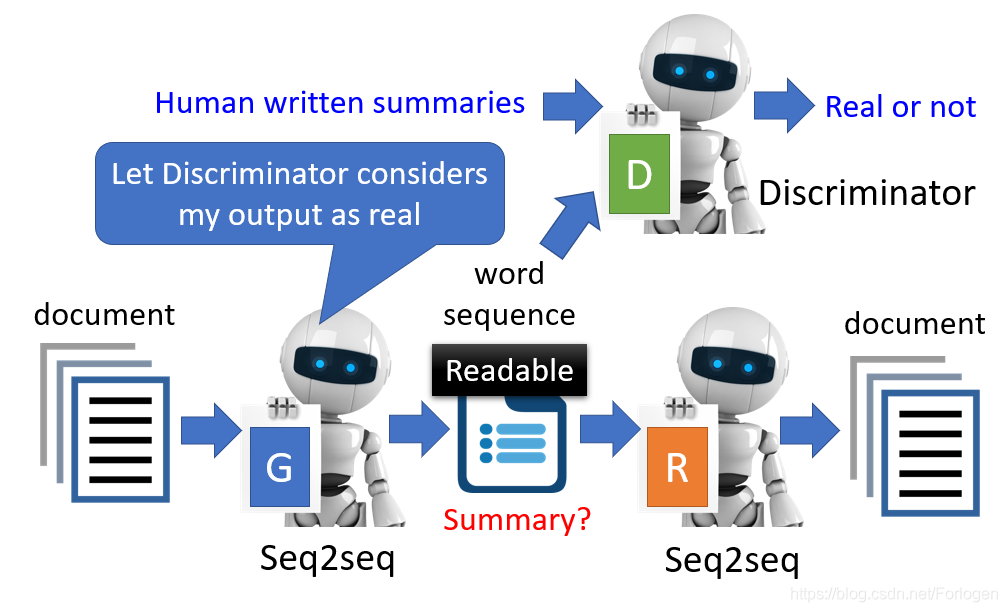
如果我们要训练一个seq2seq2seq的Auto-encoder时,使用其他对抗的思想进行训练,就可以得到类似关于输入文档的摘要信息
其他
https://arxiv.org/pdf/1901.08810.pdf
https://arxiv.org/abs/1806.07832
https://arxiv.org/abs/1904.03746

















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









