




 本文详细介绍了FP-growth算法的工作原理及其在频繁模式挖掘中的应用。对比Apriori算法,FP-growth通过构建FP树和条件数据库显著减少了计算开销。文章还探讨了算法的具体实现步骤,包括FP树构建、条件模式基的获取以及频繁模式的挖掘。
本文详细介绍了FP-growth算法的工作原理及其在频繁模式挖掘中的应用。对比Apriori算法,FP-growth通过构建FP树和条件数据库显著减少了计算开销。文章还探讨了算法的具体实现步骤,包括FP树构建、条件模式基的获取以及频繁模式的挖掘。
算法提出的背景
尽管有着很多的办法用来提升Apriori算法效率,但是如下的两个问题并没有得到很好的解决:
- 仍会产生大量的候选集,比如10410^4104个频繁1项集,就需要产生10710^7107个频繁2项集
- 在产生频繁K项集的过程中,需要重复的扫描数据库,开销很大
FP-growth算法的基本原理
FP-growth算法的提出,就很好的解决了在产生候选项集过程中巨大的开销。
它采用了分治的策略,基本步骤如下:
- 首先,将代表频繁项集的数据库压缩到一棵频繁模式树(FP-Tree)
- 然后把这种压缩后的数据库划分成一组条件数据库,每个数据库关联一个频繁项或“模式段”,并分别挖掘每个条件数据库。
随着被考察模式的“增长”,这种方法可以显著地压缩被搜索的数据集大小。
构造FP树
下面我们首先来看FP-growth算法的第一步,如何根据给定的事务集构造一颗FP树。构造FP树的算法流程如下所示
- 扫描事务数据库DDD一次。收集频繁项的集合FFF和它们的支持度。对FFF按支持度降序排序,结果为频繁项表LLL。
- 创建FPFPFP树的根结点,以nullnullnull标记它。对于DDD中每个事务TransTransTrans,执行如下操作:选择 TransTransTrans中的频繁项,并按LLL中的次序排序。设排序后的频繁项表为[p∣P][p | P][p∣P],其中ppp 是第一个元素,而PPP是剩余元素的l列表。调用insert_tree([p | P], T)。该过程执行情况如下:如果TTT有子女NNN使得N.item−name=p.item−nameN.item-name = p.item-nameN.item−name=p.item−name,则NNN的计数增加1;否则创建一个新结点NNN,将其计数设置为1,链接到它的父结点TTT,并且通过结点链结构将其链接到具有相同item−nameitem-nameitem−name的结点。如果PPP非空,递归地调用insert_tree(P, N)。
下面我们通过一个具体的例子来看一下FP树的构造过程,假设事务集如下所示
| TID | List of item_IDs |
|---|---|
| T100 | I1, I2, I5 |
| T200 | I2,I4 |
| T300 | I2,I3 |
| T400 | I1,I2,I4 |
| T500 | I1,I3 |
| T600 | I2,I3 |
| T700 | I1,I3 |
| T800 | I1,I2,I3,I5 |
| T900 | I1,I2,I3 |
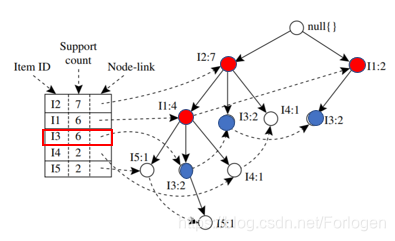
按照算法的流程,我们首先扫描事务数据库,找到频繁1项集和它们对应的支持度,并降序排列,结果如下
| Item ID | Support count |
|---|---|
| I2 | 7 |
| I1 | 6 |
| I3 | 6 |
| I5 | 2 |
| I4 | 2 |
然后开始构造TP树,首先创建根节点null,然后看第一条事务T100T100T100={I1,I2,I5I1,I2,I5I1,I2,I5},因为此时只有根节点,所以按序创建如下的子树(书上叫节点链结构)
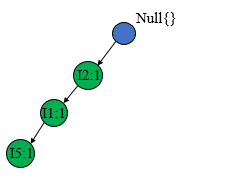
接着处理第二条事务T200T200T200={I2,I4I2,I4I2,I4},因为已经有了I2I2I2的节点,只需要创建新的I4I4I4节点,并将I2I2I2的计数加1,其余的节点不受影响 。
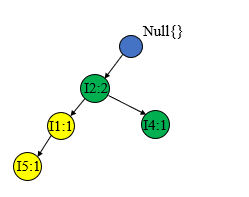
T300T300T300={I2,I3I2,I3I2,I3}和T200T200T200进行相似的处理,将I2I2I2计数加1,并创建新的节点I3I3I3
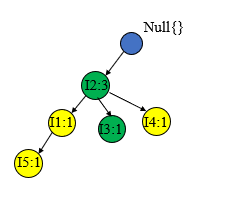
处理T400T400T400={I1,I2,I4I1,I2,I4I1,I2,I4},方法一样
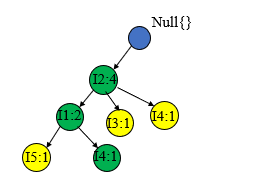
处理T500T500T500={I1,I3I1,I3I1,I3}时子树不是以I2I2I2开始的,所以需要新建一个子树包含I1I1I1和I3I3I3
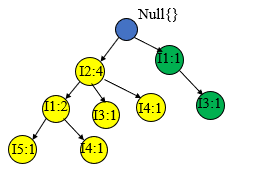
T600、T700、T800、T900T600、T700、T800、T900T600、T700、T800、T900的过程和上面的类似,这里就不一一赘述,直接给出构造过程
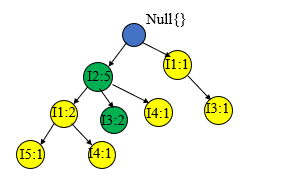
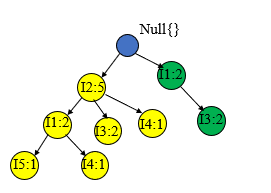
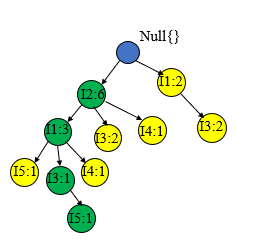
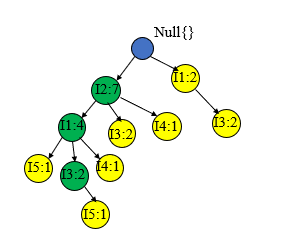
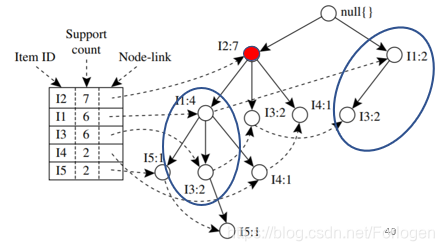
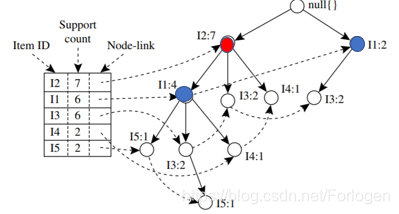
最后我们就可以生成如下的一颗FP树,为了后边挖掘时遍历的方便,创建项头表,使每项通过节点链指向它树中的位置,如下所示。
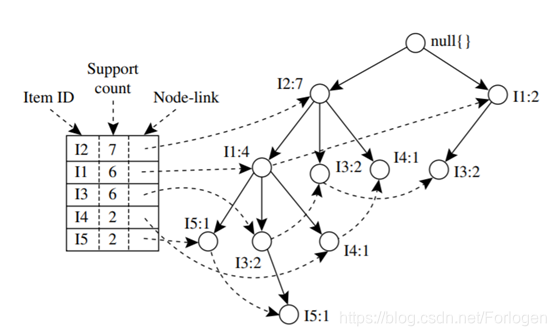
从FP树中挖掘频繁模式
在构造好FP树之后,我们就可以对其进行挖掘。在此之前先阐述两个概念:
-
条件模式基:当选择一后缀,FP树中与该后缀一起出现的前缀路径集。如下所示,当后缀为I5I 5I5时,它的条件模式基就是{I2,I1:1I2,I1:1I2,I1:1}和{I2,I1,I3:1I2,I1,I3:1I2,I1,I3:1}
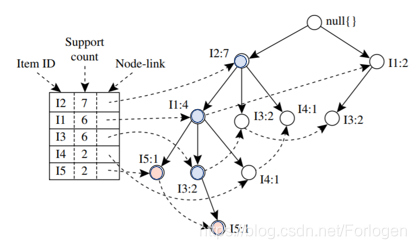
-
条件FP树:将得到得条件模式基作为新的事务数据库构造FP树得到的就是条件FP树
在明白了其中涉及的概念后,我们开始从FP树中挖掘频繁模式。
下面先给出从FP树中进行频繁模式挖掘的算法流程,,接下来的挖掘过程就是按照这样的思想一步步进行

为了方便查看,这里再次给出频繁1项集和其支持度的表
| Item ID | Support count |
|---|---|
| I2 | 7 |
| I1 | 6 |
| I3 | 6 |
| I5 | 2 |
| I4 | 2 |
I5I5I5
按照算法的流程,首先看项头表的第一项I5I5I5(倒序排列),α=null\alpha=nullα=null,α1=I5\alpha_{1}=I 5α1=I5,β=α∪α1=I5\beta=\alpha ∪ \alpha1=I 5β=α∪α1=I5,β.sup=2\beta.sup=2β.sup=2。然后找到I5I5I5的条件模式基如下所示为{{I2,I1:1I2,I1:1I2,I1:1},{I2,I1,I3:1I2,I1,I3:1I2,I1,I3:1}}
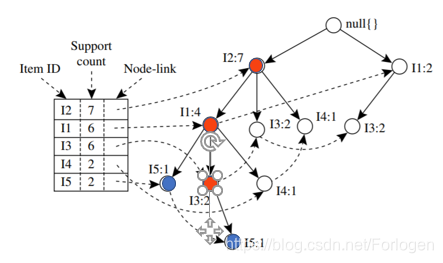
将其作为新的事务集构造FP树如下所示,因为{I1,I2,I3:1I1,I2,I3:1I1,I2,I3:1}支持度小于2,所以将其删除。得到最后的Treeβ=Tree_{\beta}=Treeβ= <I2:2,I1:2I2:2,I1:2I2:2,I1:2>,如下所示:
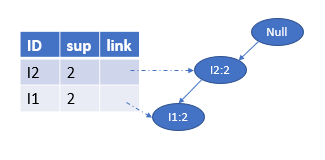
它只有一条路径,包含两个节点,所以只有三种组合方式β=\beta=β= {I2:2I2:2I2:2},{I1:2I1:2I1:2},{I2,I1:2I2,I1:2I2,I1:2},β∪α=\beta ∪ \alpha=β∪α={I2,I5:2I2, I5: 2I2,I5:2}, {I1,I5:2I1, I5: 2I1,I5:2}, {I2,I1,I5:2I2, I1, I5: 2I2,I1,I5:2}
故得到的频繁模式为:{I2,I5:2I2, I5: 2I2,I5:2}, {I1,I5:2I1, I5: 2I1,I5:2}, {I2,I1,I5:2I2, I1, I5: 2I2,I1,I5:2}
I4I4I4
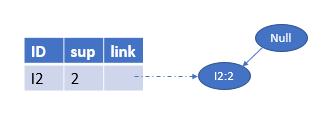
然后看I4I4I4,α=null\alpha=nullα=null,α2=I5\alpha_{2}=I 5α2=I5,β=α∪α2=I5\beta=\alpha ∪ \alpha_{2}=I 5β=α∪α2=I5,β.sup=2\beta.sup=2β.sup=2。然后找到I4I4I4的条件模式基如下所示为{{I2,I1:1I2,I1:1I2,I1:1},{I2:1I2:1I2:1}}

然后同样构造新的FP树Treeβ=Tree_{\beta}=Treeβ=<I2:2I2:2I2:2>,它同样只有一条路径且只包含一个节点,故只有一种组合方式 β=\beta=β={I2,I4:2I2,I4:2I2,I4:2},得到新的频繁模式{I2,I4:2I2,I4:2I2,I4:2}
I3I3I3
接着看α3=I3\alpha_{3}=I3α3=I3,同样有α=null\alpha=nullα=null,α3=I3\alpha_{3}=I 3α3=I3,β=α∪α3=I3\beta=\alpha ∪ \alpha_{3}=I 3β=α∪α3=I3,β.sup=6\beta.sup=6β.sup=6。然后找到I3I3I3的条件模式基如下所示为{{I2,I1:2I2,I1:2I2,I1:2},{I2:2I2:2I2:2},{I1:2I1:2I1:2}}
构造的新的FP树Treeβ=Tree_{\beta}=Treeβ= <I2:4,I1:2I2:4,I1:2I2:4,I1:2>,<I1:2I1:2I1:2>,这里和上面的情况不同,这里有两条路径
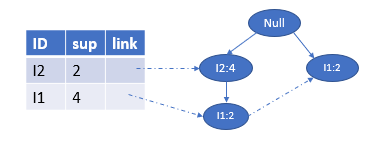
我们需要跳到步骤4,重新继续前面类似的过程如下所示:
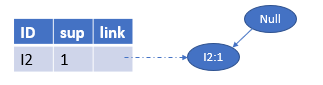
先看第一个分支<I2:4,I1:2I2:4,I1:2I2:4,I1:2>,α1=I1,β=α1∪α=\alpha_{1}=I1,\beta=\alpha_{1}∪\alpha=α1=I1,β=α1∪α={I1,I3I1,I3I1,I3},βsup=4\beta_{sup}=4βsup=4,β\betaβ的条件模式基为{I2:1I2:1I2:1},故Treeβ=Tree_{\beta}=Treeβ=<I2:1I2:1I2:1>
非空,只有一条路径且只包含一个节点,故β=β∪α=\beta=\beta ∪\alpha=β=β∪α={I2,I1,I3:2I2,I1,I3:2I2,I1,I3:2},,得到频繁模式{I2,I1,I3:2I2,I1,I3:2I2,I1,I3:2}
看第二个分支<I1:2I1:2I1:2>,α2=I2\alpha_{2}=I2α2=I2,β=α2∪α=\beta=\alpha_{2}∪\alpha=β=α2∪α={I2,I3I2,I3I2,I3},βsup=4\beta_{sup}=4βsup=4,β\betaβ的条件模式基为{∅∅∅},故Treeβ=Tree_{\beta}=Treeβ={∅∅∅},这里TreeβTree_{\beta}Treeβ为空,所以不再产生新的频繁模式.
故针对I3I3I3产生的全部频繁模式为{I2,I1,I3:2I2,I1,I3:2I2,I1,I3:2},{I1,I3:4I1,I3:4I1,I3:4},{I2,I3:4I2,I3:4I2,I3:4}
之所以有频繁模式{I1,I3:4I1,I3:4I1,I3:4},{I2,I3:4I2,I3:4I2,I3:4}是因为I1I1I1和I2I2I2在最初的FP树中就是I3I3I3的前缀,所以它们的计数一定大于I3I3I3,所以它们的组合一定是频繁模式。
I1I1I1
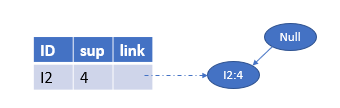
再看α4=\alpha_{4}=α4= I1I1I1,β=α4∪α=\beta=\alpha_{4}∪\alpha=β=α4∪α={I1I1I1},βsup=6\beta_{sup}=6βsup=6,条件模式基为{I2:4I2:4I2:4}
Treeβ=Tree_{\beta}=Treeβ=<I2:4I2:4I2:4>只有一条路径,一个节点,一种组合方式,所以β=\beta=β={I2,I1:4I2,I1:4I2,I1:4},得到频繁模式{I2,I1:4I2,I1:4I2,I1:4}
I2I2I2
最后只包含一个节点I1I1I1的条件模式基为{I2:4I2:4I2:4},Treeβ=Tree_{\beta}=Treeβ=<I2:4I2:4I2:4>,所以得到一个频繁模式{I2:I1:4I2:I1:4I2:I1:4}。
所以挖掘原始的事务集构造的FP树得到如上所示的所有频繁模式。
P.S. 最初看这部分内容一下懵住了,么看懂,后来听同学讲才理解了它的整个过程,感谢刘老师的讲述!!
加强强关联规则的提取
前面在Apriori算法中由最小支持度和最小置信度得到的强关联规则具有一定的欺骗性,所以引入了相关性度量来扩充度量框架。
提升度
lift(A,B)=P(A∪B)P(A)P(B)lift(A,B)=\frac{P(A∪B)}{P(A)P(B)}lift(A,B)=P(A)P(B)P(A∪B)
如果值小于1,表示A的出现和B的出现是负相关的;如果值大于1,表示两者是正相关的;如果值等于1,表示A和B是独立的,两者不具有相关性。
全置信度
all_conf(A,B)=SUP(A∪B)max{sup(A),sup(B)}=min{P(A∣B),P(B∣A)}all\_conf(A,B)=\frac{SUP(A∪B)}{max\{sup(A),sup(B)\}}=min\{P(A|B),P(B|A)\}all_conf(A,B)=max{sup(A),sup(B)}SUP(A∪B)=min{P(A∣B),P(B∣A)}
最大置信度
max_conf(A,B)=max{P(A∣B),P(B∣A)}max\_conf(A,B)=max\{P(A|B),P(B|A)\}max_conf(A,B)=max{P(A∣B),P(B∣A)}
Kulczynski度量
Kulc(A,B)=12(P(A∣B),P(B∣A))Kulc(A,B)=\frac{1}{2}(P(A|B),P(B|A))Kulc(A,B)=21(P(A∣B),P(B∣A))
余弦
cosine(A,B)=P(A∪B)P(A)×P(B)=sup(A∪B)sup(A)×sup(B)=P(A∣B)×P(B∣A)cosine(A,B)=\frac{P(A∪B)}{\sqrt{P(A)\times P(B)}}=\frac{sup(A∪B)}{\sqrt{sup(A)\times sup(B)}}=\sqrt{P(A|B)\times P(B|A)}cosine(A,B)=P(A)×P(B)P(A∪B)=sup(A)×sup(B)sup(A∪B)=P(A∣B)×P(B∣A)
以上的度量方式只受P(A∣B),P(B∣A)P(A|B),P(B|A)P(A∣B),P(B∣A)的影响,而不受事务总数的影响,每个度量值都0~1,而且值越大,两者的联系越密切。
同时为了评估两个项集之间的不平衡度引入了不平衡比,定义如下:
IR(A,B)=∣sup(A)−sup(B)∣sup(A)+sup(B)−sup(A∪B)IR(A,B)=\frac{|sup(A)-sup(B)|}{sup(A)+sup(B)-sup(A∪B)}IR(A,B)=sup(A)+sup(B)−sup(A∪B)∣sup(A)−sup(B)∣
在实际使用中推荐Kulczynski度量和不平衡比一起使用,来提供项集间的模式联系。

















 3687
3687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









