




 本文深入探讨了线性支持向量机(SVM)的原理与应用,详细讲解了如何通过数学公式推导出最优分类面,并介绍了支持向量机在理论上的优势及其与正则化思想的联系。
本文深入探讨了线性支持向量机(SVM)的原理与应用,详细讲解了如何通过数学公式推导出最优分类面,并介绍了支持向量机在理论上的优势及其与正则化思想的联系。
学习完了机器学习基石课程后,趁热打铁继续学习下机器学习技法的课程啦!完了就要专心看论文了~~~首先看一下两门课的共通点以及这门课所侧重的三个算法:SVM、Adaptive Boosting、Deep Learning,它们分别从不同的思想提出,各有千秋

了解之后,正式开始学习了!第一讲学习有关线性支持向量机的知识

首先我们回顾一下上门课程所学到的有关线性分类的东西,如下图所示,给定一系列不同类的数据点,我们希望可以找到一条线或是一个超平面可以很好将不同的点区分开来,相关的算法比如PLA、Pocket、LR等,在数学上其实是算一个加权的分数,然后利用sign(x)sign(x)sign(x)得出+1或是-1
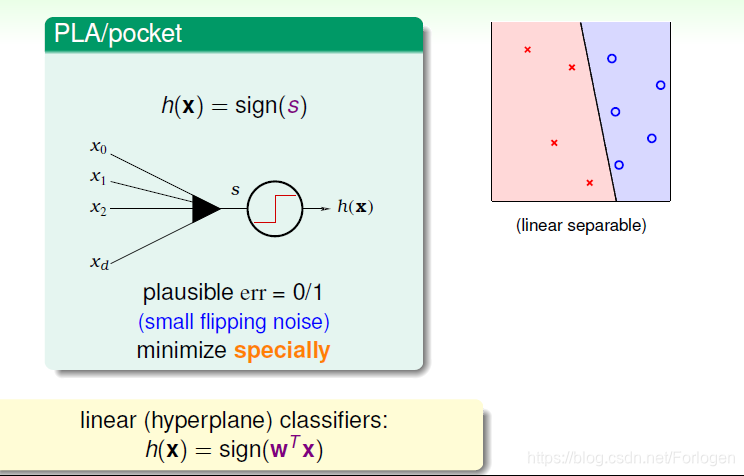
那么由于数据点不是完全贴合在一起的,那么可以找到的线理论上是有无数条的,如下图所示的情况,每一条线都可以正确的分类,那么如何找到最好的一条呢?
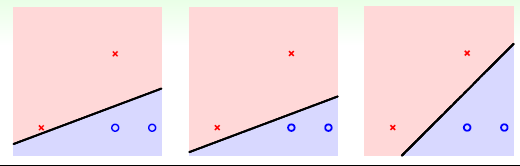
从算法分析可知,PLA等是随机的选择了一条;从VC Dimension的理论来看,也都满足VCBoundVC_{Bound}VCBound的要求,而且模型的复杂度相同,泛化能力相同。但我们直观上来看,仿佛第三条线的效果更好,那有什么根据吗?

首先,我们将图像改为下图所示的形式,点周围的圆形区域表示分类线所能容忍的误差的程度,即区域面积越大,数据点到直线的距离越大,容忍误差的程度越强,反之越小。从另一个角度来看,可以将其形象的将其看成直线的胖瘦
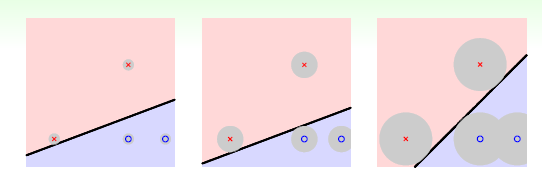
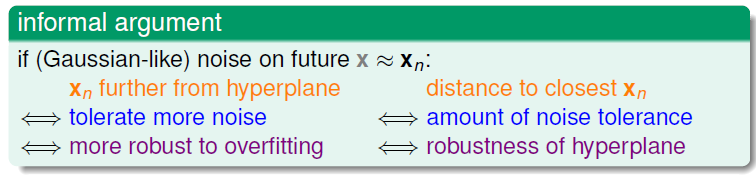
那么对于误差的容忍程度是什么意思呢?如果我们取到和图中数据XnX_{n}Xn相近的新的数据 xxx ,直线也可以将其正确的区分。这样的模型,既可以允许部分数据噪声的存在,也可以很好的避免过拟合的出现
而且这里的胖指的是在正确划分的基础上,直线离两边数据点的最小距离。分类的线由WWW决定,我们的目标是找到使其最胖的时候所对应的WWW值

理论上把这种胖称之为marginmarginmargin,越胖表示marginmarginmargin越大。所以整体上来说,就是希望在满足如下条件的基础上,找到最大的marginmarginmargin对应的WWW,此时我们认为这条分类的线就是最好的!

因此在求解的目标中,最重要的就是通过求解distance(Xn,W)distance(X_{n},W)distance(Xn,W)来求出最优的WWW
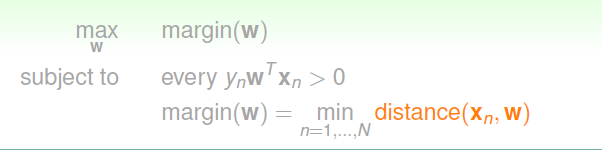
为了方便后面公式的推导,这里我们做一些新的规定:在WWW向量中,将W0W_{0}W0单独分离出来,将其记为bbb;在XXX向量中,不再令X0=1X_{0}=1X0=1,而是将其去掉,这样我们就得到了比之前矮一些的WWW和XXX

那么h(x)h(x)h(x)也就变成了如下的形式

接下来,看一下如何计算点到分类平面的距离。假设图中的超平面wTx+b=0w^Tx+b=0wTx+b=0上有x′x'x′和x′′x''x′′两个,那么必然满足公式①①①,那么x′′−x′x''-x'x′′−x′就是超平面上的一个向量,而公式②②②结果为零,表示WWW是垂直于x′′−x′x''-x'x′′−x′,也就是WWW是超平面的法向量。那么现在平面外有一点xxx,要计算xxx到平面的距离,根据数学的知识,我们知道可以计算x−x′x-x'x−x′在法向量方向上的投影

令x′′−x′x''-x'x′′−x′和www之间的夹角为θ\thetaθ,根据三角函数的知识,距离的计算就可以通过下式求出
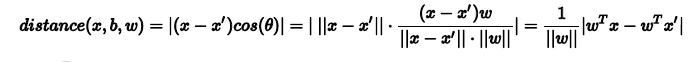
带入①①①式就可得如下得形式,它和www和bbb有关
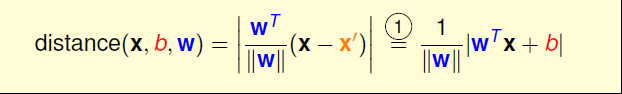
根据上面的条件我们知道,在分类平面已知的情况下,所有的点满足下图公式1,表示所有点都分对了。那么将其带入上面距离的计算公式,去掉绝对值后就是公式2的形式

这样经过转换,我们的求解目标就变成了下面这样,但是这样看来仍然有点抽象,我们很难求解

对于等式左右两边乘以一个相同的数,等式的结果是不变的,在这个问题中,也就是wTx+b=0w^Tx+b=0wTx+b=0和3wTx+3b=03w^Tx+3b=03wTx+3b=0表示的是同一个平面。因此将www和bbb进行放缩得到的平面不会发生改变,所以这里我们令距离分类最近的点满足下图公式2的形式,那么margin就变成了1∣∣w∣∣\frac{1}{||w||}∣∣w∣∣1

即求解目标为如下的形式,因为限制条件强化了,yn(WTxn+b)>0y_{n}(W^Tx_{n}+b)>0yn(WTxn+b)>0就可以省略

上面公式的条件是yn(wTxn+b)=1y_{n}(w^Tx_{n}+b)=1yn(wTxn+b)=1,也就是对所有的点要求yn(wTxn+b)≥1y_{n}(w^Tx_{n}+b)≥1yn(wTxn+b)≥1,根据相关的理论证明可能这样放宽后得到的结果仍然满足最先的条件

所以将其转化为它的对偶问题,同时去掉根号,为了方便计算添加12\frac{1}{2}21,求解目标就如下图所示,形象化的来说就是找到那条分类正确的最胖的线
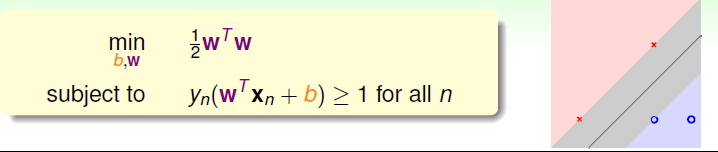
假设上右图中的四个点如下所示,将其表示成矩阵的形式,带入到条件中可得i、ii、iii、iv的形式,如果将i和iii合并可得w1≥+1w_{1}≥+1w1≥+1,将ii和iv合并可得w2≤−1w_{2}≤-1w2≤−1,综合可得12wTw≥1\frac{1}{2}w^Tw≥121wTw≥1。那么如果w1=1、w2=−1、b=−1w1 = 1、w2 = -1、 b = -1w1=1、w2=−1、b=−1的话就有等于1 的情况,也就是得到了最优分类面的解,则分类面用x1−x2−1=0x_{1}-x_{2}-1=0x1−x2−1=0表示。则最后得到的g如下所示

何为Support Vector Machine(SVM),即支持向量机呢?因为分类面仅仅由分类面的两边距离它最近的几个点决定的,其它点对分类面没有影响。故将决定分类面的几个点称之为支持向量(Support Vector),如下右图中方框中的点所示,而利用支持向量得到最佳分类面的方法叫支持向量机。

SVM的求解目标和条件如下所示,仔细一看好像无法使用梯度下降来求,但它是一个二次规划问题Quadratic Programming。
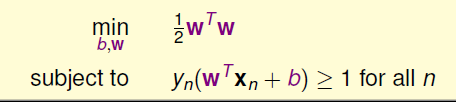
上面的目标表达式是关于w的二次函数,条件是关于www和bbb的一次函数,所以符合二次规划的特征。接下来就需找出SVM与标准二次规划问题的参数对应关系,如下图所示

这样我们就可以将整个过程总结如下
• 计算对应的二次规划参数Q,p,A,cQ,p,A,cQ,p,A,c
• 计算b,wb,wb,w
• 将b和wb和wb和w代入gsvm,得到最佳分类面
这里的向量机称为线性硬间隔支持向量机,线性是指数据集是线性可分的,硬间隔是指不允许有一个数据分错。

那如果像前面一样,我们的数据集是非线性可分的呢?这时学过的线性变换就配上用场了,将非线性可分的xxx域中的数据转换到zzz域中,变成线性可分的问题
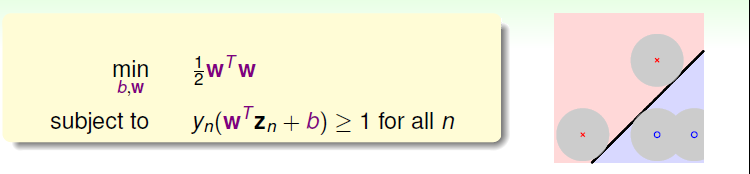
到现在看来,支持向量机的这种方式效果更好一些,那么在理论上是否有保证呢?SVM的这种思想其实与我们之前介绍的正则化思想很类似。regularization的目标是将EinE_{in}Ein最小化,条件是wTw≤Cw^Tw≤CwTw≤C;SVM的目标是最小化wTww^TwwTw,条件是Ein=0E_{in}=0Ein=0或是更严格的限制。哎这样看来,regularization与SVM的目标和限制条件分别对调了。其实两者考虑的内容是类似的,效果也是相近的。SVM也可以说是一种weight-decayregularization,限制条件是Ein=0E_{in}=0Ein=0
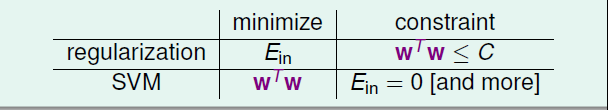
在之前VC Dimension的部分讲到,如果我们不限制线的胖瘦,像PLA将可以将任意的三个点shatter,可以有8种Dichotomies。但是如果线越胖,margin越大,那么它可能shatter的点就可能越少。故当dichotomies越少,VC Dimension就越小,模型的泛化能力就越强
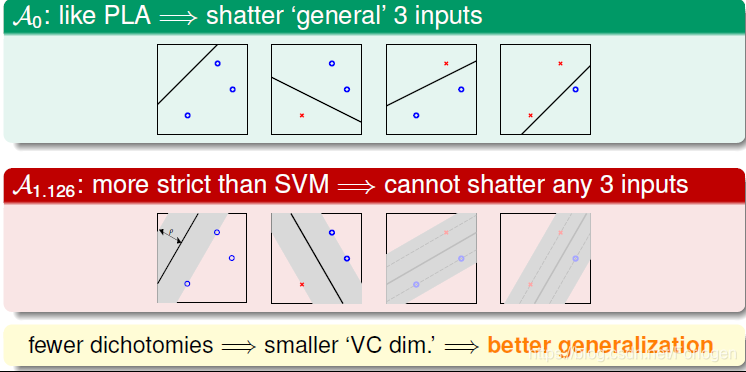
那为什么dichotomies越少,VC Dimension就越小呢?首先我们看一下硬间隔支持向量机的VC Dimension,记为dvc(Aρ)d_{vc}(A_{\rho})dvc(Aρ)。它是与数据有关的,而我们之前介绍的dvcd_{vc}dvc是与数据无关。

假如平面上有3个点分布在单位圆上,如果Margin为0,即ρ\rhoρ=0,这条细直线可以很容易将圆上任意三点分开,那么dvc=3d_{vc}=3dvc=3。如果是如下图第二种情况时,这条粗线无论如何都不能将圆上的任一三点全完分开,因为圆上必然至少存在两个点的距离小于根号3,那么其对应的dvc<3d_{vc} < 3dvc<3

根据相关理论可以证明,在d维空间中,当数据点分布在半径为R的超球体中,dvc(Aρ)d_{vc}(A_{\rho})dvc(Aρ)满足下面的关系dvc(Aρ)≤d+1d_{vc}(A_{\rho})≤d+1dvc(Aρ)≤d+1

总结一下,这一讲主要学习了线性硬间隔指支持向量机,通过公式的推导,得出了我们的目标表达式和条件,指出了可以使用解二次规划问题的方法求解;接着又学习它背后的理论依据


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









