




 谷歌推出的PEGASUS模型,采用新型预训练目标GSG,针对文本摘要任务,实现在多个数据集上达到最佳效果,尤其在低资源情况下表现突出。
谷歌推出的PEGASUS模型,采用新型预训练目标GSG,针对文本摘要任务,实现在多个数据集上达到最佳效果,尤其在低资源情况下表现突出。
就在这几天微软发布了一款参数量多达170亿的史上最大的自然语言生成模型 Turing-NLG,在多种语言模型基准上均实现了SOTA。
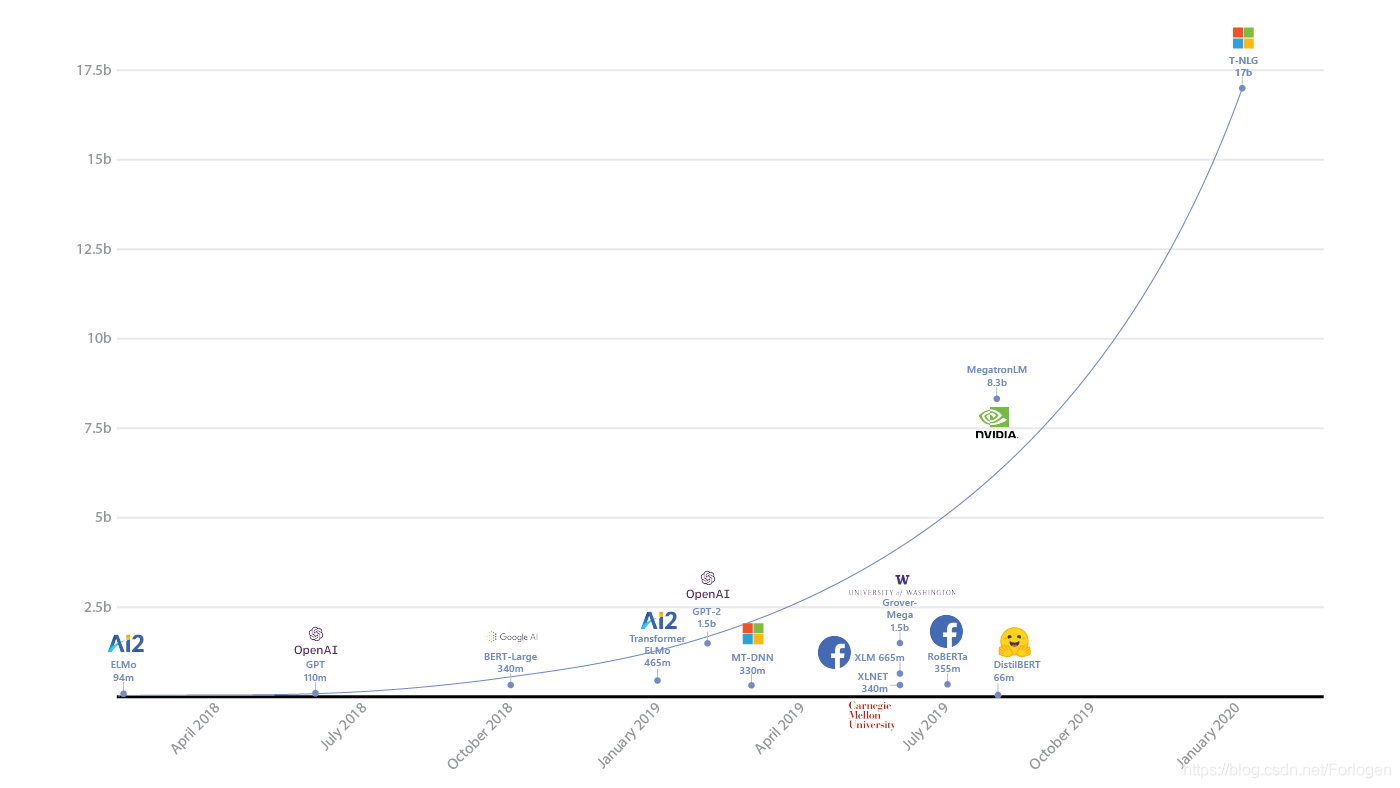
值得关注的是Turing-NLG在文本摘要上的表现,由于它已经非常善于理解文本了,因此不需要太多的配对数据就可以实现比已有模型更好的效果。
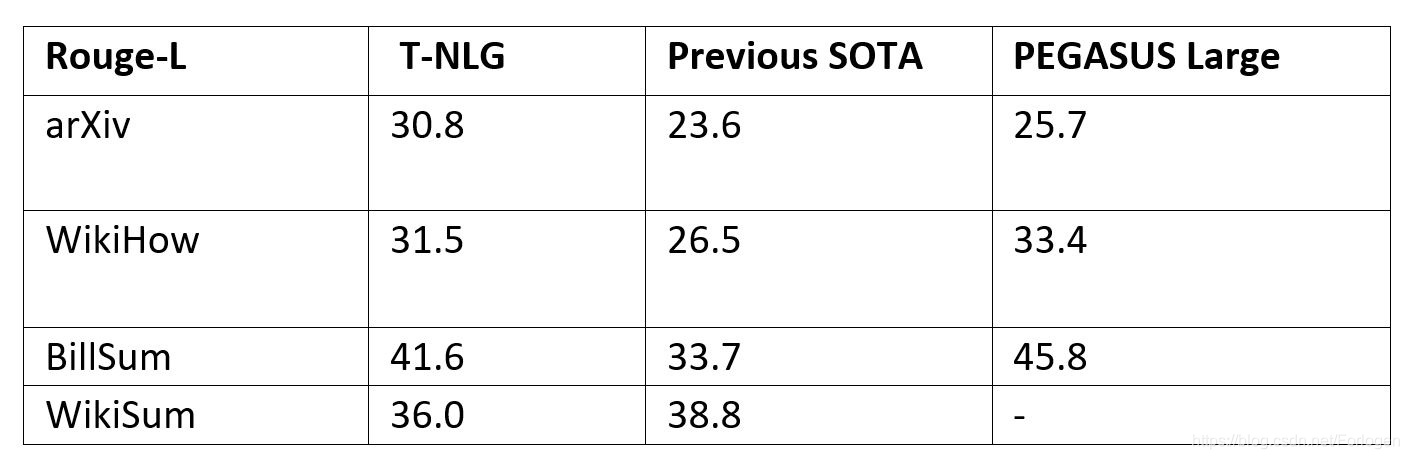
从Facebook的BART、Google的PEGASUS到今天Microsoft的Truing-NLG,越来越大的预训练数据集和越来越大的Transformer模型容量,以及新的预训练方法对于预训练模型在各项自然语言处理任务上效果的提升十分明显,同时也更加证明了有钱真好呀~
source: Turing-NLG: A 17-billion-parameter language model by Microsoft
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization

PEGASUS(Pre-training with Extracted Gap-sentences for
Abstractive Summarization)是Google Brain和帝国理工提出的一种新的自动文本摘要模型。PEGASUS同样基于Transformer进行模型构建,并针对于文本摘要任务本身的特定提出了新的自监督式的预训练目标GSG(Gap Sentences Generation),最后通过实验证明了在12个文本摘要数据集上均实现了当时的SOTA,而且作者指出在低资源的情形
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 564
564

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









