




 本文提出一种基于全注意力机制的信息检索模型FABIR,旨在解决RNNs在QA任务中的局限性,引入卷积注意力、词嵌入降维及列交叉注意力等创新,提升模型上下文理解和效率。
本文提出一种基于全注意力机制的信息检索模型FABIR,旨在解决RNNs在QA任务中的局限性,引入卷积注意力、词嵌入降维及列交叉注意力等创新,提升模型上下文理解和效率。
IJCNN 2018 A Fully Attention-Based Information Retriever
背景
本文解决的仍然是QA问题中基于RNNs架构的模型难以解决的一些问题和局限性,同时借着当时Transformer的热潮,提出了一种称为Fully Attention Based Information Retriever(FABIR)的QA模型,它可以简单的理解为Transformer在QA领域的应用,同时其中还涉及了一些其他的技术。
本文的贡献主要有三点:
- 提出了一种新的注意力机制:convolutional attention,它通过建立词与词之间多对多的映射关系来获取更加丰富的上下文表示
- 提出了一种用于词嵌入降维的子层:Reduction Layer,希望借此减少模型训练的参数量,加快推断过程
- 提出了一种基于列的交叉注意力机制:Column-wise cross-attention,它可以使得查询中的词更加关注文档中和查询相关的部分
related work部分对于传统的注意力机制和Transformer中的Self-Attention机制做了较为清晰的介绍,不清楚的可以直接看相关内容
模型
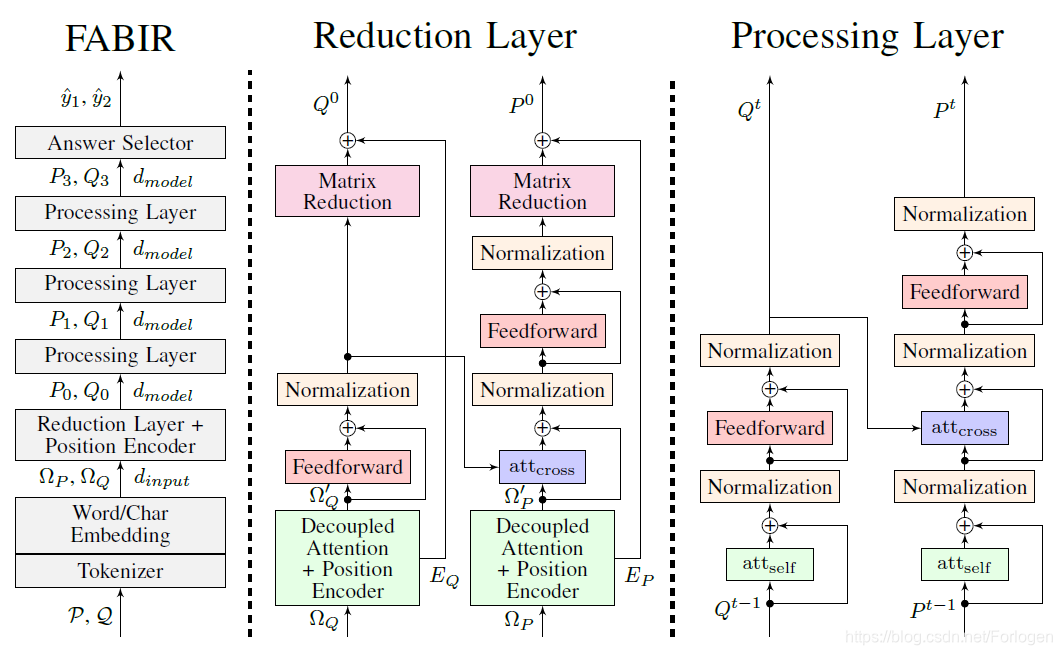
模型整体上由Embedding Layer、Reduction Layer、Processing Layer(四层)和Answer Selector四部分组成,如下所示:
-
Embedding Layer:QA模型的输入主要包含查询和文档两部分,因此需要将两部分的输入均表示为嵌入向量的形式来作为后续的输入。这里选择的仍然是word-level和character-level两个层次的嵌入,其中word-level的词嵌入直接加载预训练的Glove,而character-level则同样是使用CNN+Max pooling获取,最终查询和文档中词的嵌入表示为两部分的拼接:
w = Highway ( [ w w ; tanh ( w c ) ] ) w = \text{Highway}([w_{w};\tanh(w_{c})]) w=Highway([ww;tanh(wc)])其中Highway表示Highway Network。 -
Encoder:这部分使用的类似于Transformer的机制来获取另一种关于查询和文档的表示 P , Q → E P , E Q P,Q \rightarrow E_{P},E_{Q} P,Q→EP,EQ
因为这里无法序列化的处理数据,因此同样需要额外的提供位置信息。通过上述两种方式我们就可以获取到关于查询和文档两种类型的嵌入表示,它们是独立进行处理的,最终的表示是两种的融合形式。
下面介绍本文所说的三大贡献:
- Convolutional Attention:在标准的Attention中,查询和文档中的两个词
p
i
p_{i}
pi对
q
j
q_{j}
qj的关注程度计算方式为:
s
i
,
j
=
f
(
p
i
,
q
j
)
s_{i,j}=f(p_{i},q_{j})
si,j=f(pi,qj)。但是这种一一对应的方式作者认为无法很好的捕获相邻的一组词所表达的复杂信息,因此这里提出了这种新的Attention,它的原理就在于一次性从两部分中分词取多个词进行计算:
s i , j = f ( p i − h − 1 2 , . . . , p i + h − 1 2 , q j − w − 1 2 , . . . , q j + w − 1 2 ) s_{i,j}=f(p_{i-\frac{h-1}{2}},...,p_{i+\frac{h-1}{2}},q_{j-\frac{w-1}{2}}, ...,q_{j+\frac{w-1}{2}}) si,j=f(pi−2h−1,...,pi+2h−1,qj−2w−1,...,qj+2w−1)
其中 h h h和 w w w分别表示卷积核的高和宽。
-
Column-wise cross-attention:在Self-Attention中通过对于输入自身的计算来获取的更好的表示 att s e l f ( P ) = att c o n v ( P , P , P ) \text{att}_{self}(P)=\text{att}_{conv}(P,P,P) attself(P)=attconv(P,P,P)
而另一种cross-Attention通过关注两个不同来源的部分来进行注意力的计算
att c r o s s ( P , Q ) = cross c o n v ( P , Q , Q ) \text{att}_{cross}(P,Q)=\text{cross}_{conv}(P,Q,Q) attcross(P,Q)=crossconv(P,Q,Q)
以上两种方式都是基于行(row-wise)的形式,P中的每一个词会和Q中每一个词进行一次计算,但在实际情况中,P中的词并不总是和Q中的词具有相关性。因此,作者提出通过使用column-wise的注意力计算方式来尽量只计算相关的词 -
Reduction Layer:在之前的研究中观察到:当词嵌入向量的维度很高时,模型在训练中容易过拟合。因此,作者在这里提出了一种对嵌入向量进行降维的层,希望借此减少模型训练的参数量,加快推断过程,而且在后面的实验部分也证明了这种方式的有效性。
它主要由Decoupled Attention、cross-attention、Feedforward、Normalization和Matrix Reduction组成,其中Matrix Reduction对于降维起着主要作用。假设输入为
w
i
n
p
u
t
w_{input}
winput,输出为
w
m
o
d
e
l
w_{model}
wmodel,那么简单的表述为
w
m
o
d
e
l
=
W
r
e
d
u
c
t
i
o
n
w
i
n
p
u
t
w_{model}=W_{reduction}w_{input}
wmodel=Wreductionwinput
另外涉及的一个部分便是Decoupled Attention:
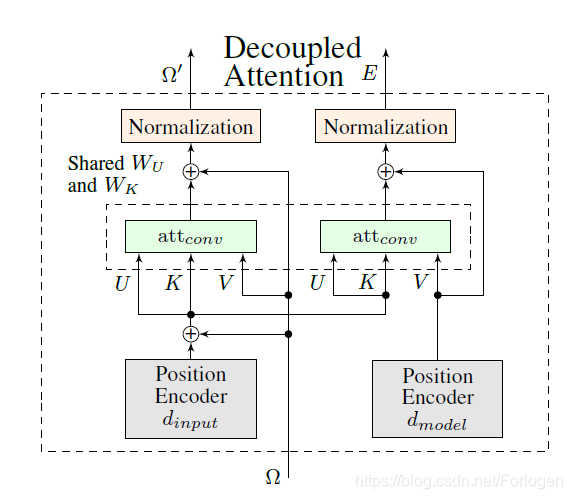
它可以独立的计算embedding matrix和encoder matrix,同时通过共享权值矩阵 W U W_{U} WU和 W K W_{K} WK及相同的输入 U U U和 K K K来加快计算Convolutional Attention。
- Answer Layer:这里同样是通过优化负对数似然的方式来计算答案的起始位置和结束位置所满足的概率分布,模型选择的是两层的卷积网络。
J = − ( y 1 log ( π 1 ) + y 2 log ( π 2 ) ) J=-(y_{1} \log(\pi_{1})+y_{2} \log(\pi_{2})) J=−(y1log(π1)+y2log(π2))
实验部分可见原文~

















 264
264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









