






 MaskGAN通过填充空白任务改善了基于GAN的文本生成模型,解决了传统Seq2Seq模型的局限,提高了文本生成质量和多样性。
MaskGAN通过填充空白任务改善了基于GAN的文本生成模型,解决了传统Seq2Seq模型的局限,提高了文本生成质量和多样性。
MaskGAN:Better Text Generation via Filing in the ______
传统的基于Seq2Seq的文本生成模型都是使用自回归方式来逐个的生成词,在每一时刻生成的词不仅依赖于Encoder的上下文向量,同时也依赖于Decoder已生成的部分。模型的训练普遍使用最大似然优化和teacher forcing的方式,同时使用验证困惑度(validation perplexity)来评估生成文本的质量。
但是这样的生成方式存在如下的不足:
- 真实场景下生成文本并没有ground truth来做teacher forcing,导致生成文本的质量很差 ,虽然有类似Professor forcing和Scheduled Sampling等方法来解决这个问题,但它们并没有直接对RNN的损失函数做修改,从而显式的鼓励模型生成更高质量的文本
- 验证困惑度并不能真正的评估生成文本的质量,有时困惑度的优化却伴随着文本质量的下降
因此Ian Goodfellow课题组使用在图像生成任务上表现良好的生成对抗网络(GAN)来显式的指导生成器的训练,进行不断的迭代最终生成器可以生成较高质量的文本。另外为了解决GAN在处理离散数据不可微的问题,作者使用了不同于SeqGAN中policy gradient + Mente Carlo的方式进行训练,而是采用了更方便的Actor-Critic算法,它可以根据缺失部分的上下文来来进行填充。
另外GAN中模式丢失(model dropping)和训练不稳定这两个问题在离散化的文本生成中更加显著,例如生成器会倾向于不断生成重复的n-grams,以及判别器只能判别生成的完整文本。
为了解决这个问题,作者将文本生成看做是fill-in-the-blank或in-filling任务来进行处理。文本的生成过程可以依赖缺失部分周围的上下文信息来进行预测填充,生成器的目标也不是直接优化验证困惑度,而是使得生成的文本无法和真实对应的文本无法被判别器区分出来。
另外,如何为设计每个时刻的误差归因(error attribution)也是NLP研究的一个难题。例如在用GAN用文本生成时,如果 t t t时刻之前生成的文本非常接近真实文本,但是 t t t时刻生成词 x t x_{t} xt可以很轻易的被判别器认为是来自于生成器的话,那么即使前面生成的结果再好,由于 x t x_{t} xt的存在使得它们的意义也就不大了。因此,如何为生成的token设计合适的损失信号,将会很大程度上影响模型的效果。
MaskGAN的模型示意图如下所示:
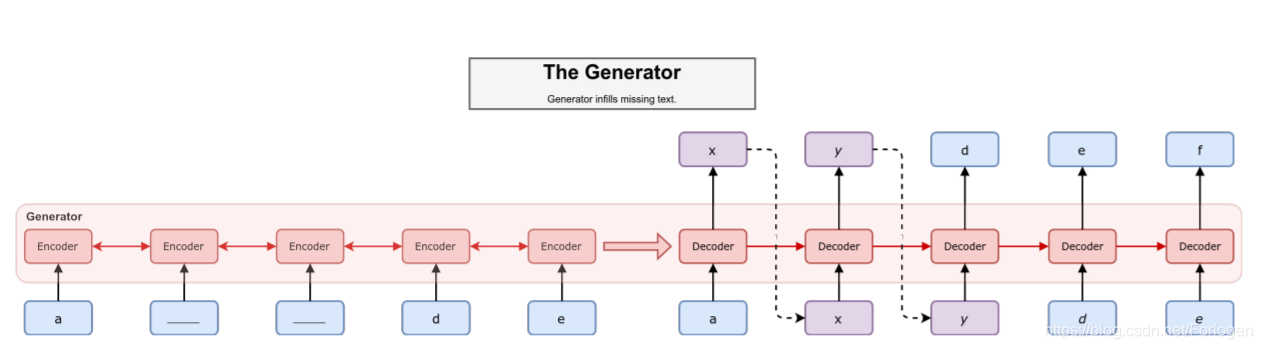
在公式化描述任务之前,让我们上面的示意图中来梳理一下它解决问题的思路。整体来看,生成器采用了Seq2Seq的架构方式。Encoder的输入为mask处理后的序列,经过编码可以得到每个值对应的隐状态(hidden state)、输出(output)和上下文向量(context vector)。Decoder的输入并不是像传统的Seq2Seq模型中使用真实文本做teacher forcing,而是每个时刻使用mask处理后的序列做为输入。具体到某个时刻来看,如果此时有真实文本对应的token,则将其做为此时刻的输入,否则使用上一时刻Decoder的输出来作为此时刻的输入,这样做一方面可以有效的利用上下文信息,另一方面也在生成过程中起来了一种修正的作用,不会使得出现的偏差随着时间不断积累。
最终生成器可以根据输入生成一段文本,接着便将其和真实文本送到判别器中进行判别,判别器会根据结果给生成器提供梯度信息进行参数的更新。经过不断的迭代,当模型收敛时生成器应该可以学会如何完成in-filling任务,即如何根据存在的上下文信息来预测缺失部分的内容。
假设将输入的离散化文本记为 x = ( x 1 , . . . x T ) x = (x_{1},...x_{T}) x=(x1,...xT),对应的mask序列为 m = ( m 1 , . . . , m T ) m = (m_{1},...,m_{T}) m=(m1,...,mT),其中 m i m_{i} mi的取值为0或1。当 m i = 0 m_{i} = 0 mi=0时, x x x中对应的位置使用< m> 进行替换;当 m i = 1 m_{i} =1 mi=1时, x x x对应位置的内容不做改变,将mask处理后的输入记为 m ( x ) m(x) m(x)。
传统的方式中,Decoder采用自回归方式来预测当前时刻的词,然而在MaskGAN中采用的方式是:Decoder在预测某个时刻的内容时需要依赖于已生成的部分和
m
(
x
)
m(x)
m(x)。因此,Decoder的生成过程可以看做是一种条件生成:
P
(
x
^
1
,
.
.
.
,
x
^
T
)
=
∏
t
=
1
T
P
(
x
^
T
∣
x
^
1
,
.
.
.
,
x
^
t
−
1
,
m
(
x
)
)
G
(
x
t
)
=
P
(
x
^
T
∣
x
^
1
,
.
.
.
,
x
^
t
−
1
,
m
(
x
)
)
P(\hat{x}_{1},...,\hat{x}_{T}) = \prod_{t=1}^T P(\hat{x}_{T}|\hat{x}_{1},...,\hat{x}_{t-1},m(x)) \\ G(x_{t})=P(\hat{x}_{T}|\hat{x}_{1},...,\hat{x}_{t-1},m(x))
P(x^1,...,x^T)=t=1∏TP(x^T∣x^1,...,x^t−1,m(x))G(xt)=P(x^T∣x^1,...,x^t−1,m(x))
判别器和生成器具有相同的架构,只是输出为表示判别结果的标量,而不是一种分布的形式。另外判别器的输入除了填充好的序列外,
m
(
x
)
m(x)
m(x)这里也是判别器的输入。这样做的道理在于:假设此时生成的句子为the director director guided the series,如果不使用
m
(
x
)
m(x)
m(x)提供的信息,判别器将无法知道两个director哪一个是真实文本中的。因为真实文本中对应的句子可能是the associate director guided the series,也可能是the director expertly guided the series, ========、
、因此
m
(
x
)
m(x)
m(x)提供的信息对于判别过程至关重要。
D
ϕ
(
x
~
t
∣
x
~
0
:
T
,
m
(
x
)
)
=
P
(
x
~
t
=
x
t
real
∣
x
~
0
:
t
,
m
(
x
)
)
D_{\phi}(\tilde{x}_{t}|\tilde{x}_{0:T},m(x)) = P(\tilde{x}_{t}=x_{t}^{\text{real}}|\tilde{x}_{0:t},m(x))
Dϕ(x~t∣x~0:T,m(x))=P(x~t=xtreal∣x~0:t,m(x))
Actor-Critic方法采用单步更新的方式,以及采用一个NN来拟合Advantage Function来指导生成器生成高质量的文本。单步的奖励值形式为:
r
t
=
log
D
ϕ
(
x
~
t
∣
x
~
0
:
t
,
m
(
x
)
)
r_{t} = \log D_{\phi}(\tilde{x}_{t}|\tilde{x}_{0:t},m(x))
rt=logDϕ(x~t∣x~0:t,m(x))
总的奖励值为此时刻到
T
T
T时刻奖励的折扣形式的和:
R
t
=
∑
s
=
t
T
γ
s
r
s
R_{t} = \sum_{s=t}^T\gamma^s r_{s}
Rt=s=t∑Tγsrs
由于在Decoder预测输入词时的采样操作,模型无法使用正常的BP进行更新,因子需借用强化学习的方法来进行模型的更新。生成器的目标是最大化累计期望奖励,即最大化
R
=
∑
t
=
1
T
R
t
R=\sum_{t=1}^T R_{t}
R=∑t=1TRt,也相当于在期望
E
G
θ
[
R
]
E_{G_{\theta}}[R]
EGθ[R]上执行梯度上升。那么
E
G
θ
[
R
]
E_{G_{\theta}}[R]
EGθ[R]上的梯度计算为:
∇
θ
E
G
[
R
t
]
=
R
t
∇
θ
log
G
θ
(
x
^
t
)
\nabla_{\theta} E_{G}[R_{t}]=R_{t}\nabla_{\theta} \log G_{\theta}(\hat{x}_{t})
∇θEG[Rt]=Rt∇θlogGθ(x^t)
为了避免得到的奖励值一直为正,这里同样需要减去一个baseline:
b
t
=
V
G
(
x
1
:
t
)
b_{t}=V^{G} (x_{1:t})
bt=VG(x1:t),那么上式也就变成了:
∇
θ
E
G
[
R
t
]
=
(
R
t
−
b
t
)
∇
θ
log
G
θ
(
x
^
t
)
\nabla_{\theta} E_{G}[R_{t}]=(R_{t} - b_{t})\nabla_{\theta} \log G_{\theta}(\hat{x}_{t})
∇θEG[Rt]=(Rt−bt)∇θlogGθ(x^t)
其中
R
t
−
b
t
R_{t}-b_{t}
Rt−bt可以看做是对选择当前动作
a
t
a_{t}
at优势的一种估计
A
(
a
t
,
s
t
)
=
Q
(
a
t
,
s
t
)
−
V
(
s
t
)
A(a_{t},s_{t})=Q(a_{t},s_{t})-V(s_{t})
A(at,st)=Q(at,st)−V(st)。当G来决定策略
π
(
s
t
)
\pi(s_{t})
π(st)、
b
t
b_{t}
bt充当critic时,整个算法流程就符合actor-critic的结构。
基于上面的分析,为了不使得某一时刻产生的token对于整体生成文本的判别起到太强的作用,这里需要为每个时刻产生的token分配奖励值,它将影响此时以及后续时刻奖励值的分配。将
R
t
R_{t}
Rt的表达式带入到
∇
θ
E
G
[
R
t
]
\nabla_{\theta} E_{G}[R_{t}]
∇θEG[Rt],那么生成器的梯度计算可以写成:
∇
E
[
R
]
=
E
x
^
t
∼
G
[
∑
t
=
1
T
(
R
t
−
b
t
)
∇
θ
log
(
G
θ
(
x
^
t
)
)
]
=
E
x
^
t
∼
G
[
∑
t
=
1
T
(
∑
t
=
1
T
γ
s
r
s
−
b
t
)
∇
θ
log
(
G
θ
(
x
^
t
)
)
]
\nabla E[R] = E_{\hat{x}_{t} \sim G}[\sum_{t=1}^T(R_{t}-b_{t}) \nabla_{\theta} \log(G_{\theta}(\hat{x}_{t}))] = E_{\hat{x}_{t} \sim G}[\sum_{t=1}^T(\sum_{t=1}^T \gamma^sr^s-b_{t}) \nabla_{\theta} \log(G_{\theta}(\hat{x}_{t}))]
∇E[R]=Ex^t∼G[t=1∑T(Rt−bt)∇θlog(Gθ(x^t))]=Ex^t∼G[t=1∑T(t=1∑Tγsrs−bt)∇θlog(Gθ(x^t))]
此时
x
^
t
\hat{x}_{t}
x^t相关的梯度信息将依赖于之后判别器分配给它的奖励,即无法只考虑某一时刻的奖励值最大,而是要考虑整个生成结果的情况。
对应的判别器的梯度计算公式为:
∇
1
m
∑
i
=
1
m
[
log
D
(
x
(
i
)
)
+
log
(
1
−
D
(
G
(
z
(
i
)
)
)
)
]
\nabla \frac{1}{m} \sum_{i=1}^m [\log D({x^{(i)})} + \log(1-D(G(z^{(i)})))]
∇m1i=1∑m[logD(x(i))+log(1−D(G(z(i))))]
对于较短的文本,Seq2Seq模型可以生成较好的结果,但是如何处理长序列以及对应的较大的词汇表依然是个问题。文中针对这两种情况给出了对应的解决思路:
- 针对于长序列而言,先将模型应用到长度为 T T T的序列上,待模型收敛后再将其用到长度为 T + 1 T+1 T+1的序列上继续训练,希望借助这种逐阶段过渡的方式,以及在较短序列上捕捉到的信息来帮助模型在更长序列上的训练。
- 针对于大词汇表来说,在生成每一个token时并不是只为其分配奖励值,而是对token所满足的分布上所有可能的token都分配奖励值。这样必然会增大计算量,但是此时判别器需考虑所有可能的情况,如果这样的方式可以取得效果,那么生成的文本质量就会有一定的保障。
当然为了训练效率,模型中的Encoder、Decoder和critic需要预训练,最后选择验证困惑度最小的模型做为后续使用的MaskGAN。
最后作者在IMDB和PTB两个数据集上进行了实验,并使用启发式的评价指标BLEU和人工评测来判断生成文本的质量,详细的实验结果可见原文。
经过实验作者发现:
- 在连续单词块被mask掉的情况下进行训练的模型往往可以生成更好的文本
- 注意力机制的使用对于所填充的token能够充分的利用上下文来说是非常重要的,如果不使用注意力,那么得到的文本可能连贯性和语义表示上会更差
- in-filling形式的任务对于减少文本生成中的模式坍缩问题具有一定的帮助,它有助于GAN训练的稳定性


















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









